极客时间 - 《趣谈网络协议》笔记
第1讲 | 为什么要学习网络协议?
协议三要素
- 语法,就是这一段内容要符合一定的规则和格式。
- 语义,就是这一段内容要代表某种意义。
- 顺序,就是先干啥,后干啥。
协议举例: HTTP
1 | HTTP/1.1 200 OK |
- 符合语法,只有按照上面那个格式来,浏览器才认。例如,上来是状态,然后是首部,然后是内容。
- 符合语义,就是要按照约定的意思来。例如,状态 200,表述的意思是网页成功返回。如果不成功,就是我们常见的“404”。
- 符合顺序,你一点浏览器,就是发送出一个 HTTP 请求,然后才有上面那一串 HTTP 返回的东西。
第2讲 | 网络分层的真实含义是什么?
网络为什么要分层
复杂的程序都要分层,这是程序设计的要求。
(个人理解) 分层的本质还是效率与性能的平衡,程序分层的背后是硬件性能的提升,因而可以分层换来更高的可复用性,可拓展性等,虽然这其中会损失一部分性能,还是综合来说效率更高了。
揭秘层与层之间的关系
只要是在网络上跑的包,都是完整的。可以有下层没上层,绝对不可能有上层没下层。
第3讲 | ifconfig:最熟悉又陌生的命令行
MAC 地址与 IP 地址
- MAC 是身份证,是唯一标识
- IP 是地址,有定位功能,解决了寻址问题
IP 地址分类
- IP 地址分为 A,B,C,D 等类,每一类又分为公有 IP 和私有 IP
- CIDR 是为了解决 IP 地址分类不科学导致 IP 不够用的问题
- CIDR 可以用来判断是否同属一个私有网络
第4讲 | DHCP与PXE:IP是怎么来的,又是怎么没的?
动态主机配置协议(DHCP)
- DHCP Discover(客户机告诉网段我需要一个 ip)
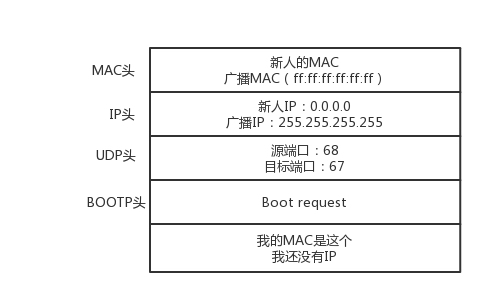
- DHCP Offer(DHCP 服务器告诉客户机我可以提供 ip)
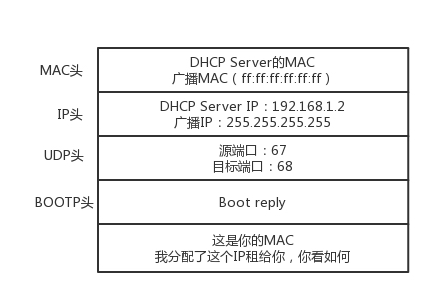
- DHCP request(客户机确认使用某一个 DHCP Offer)
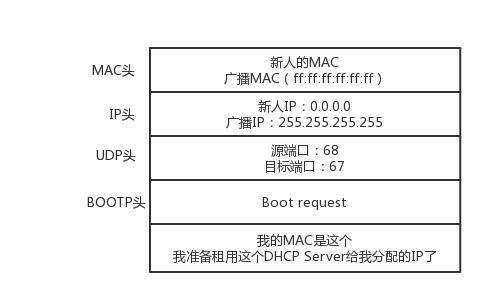
- DHCP ACK(DHCP Server 确认收到客户机的确认)
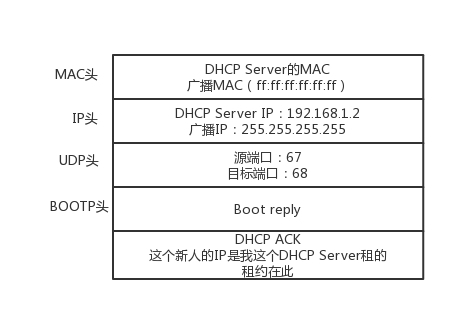
IP 租用更新就: 客户机会在租期过去 50% 的时候,直接向为其提供 IP 地址的 DHCP Server 发送 DHCP request 消息包。客户机接收到该服务器回应的 DHCP ACK 消息包,会根据包中所提供的新的租期以及其他已经更新的 TCP/IP 参数,更新自己的配置。
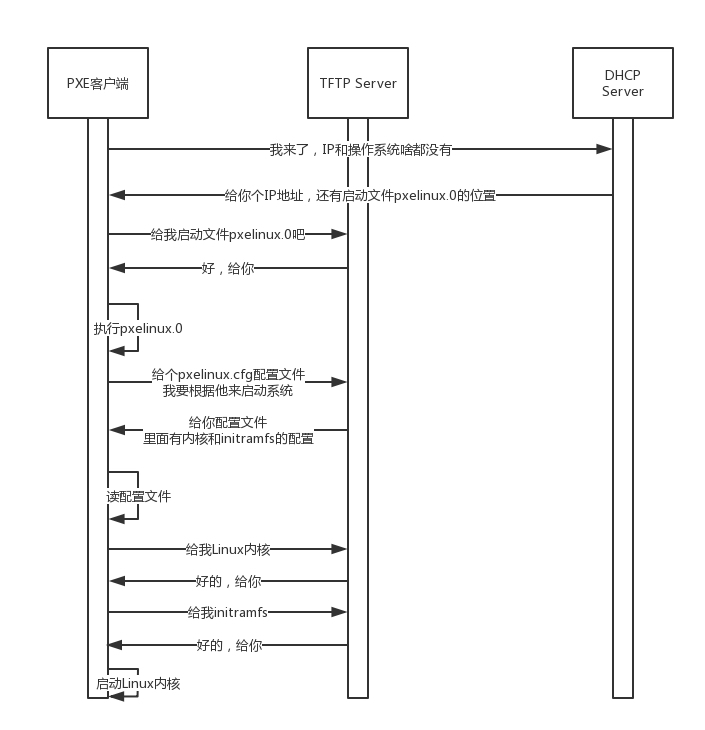
预启动执行环境(Pre-boot Execution Environment),简称PXE。
- PXE 协议分为客户端和服务器端,由于还没有操作系统,只能先把客户端放在 BIOS 里面。当计算机启动时,BIOS 把 PXE 客户端调入内存里面,就可以连接到服务端做一些操作了。
- PXE 客户端发送 DHCP Discover 后,会在 DHCP Server 返回的 DHCP Offer 中得到 PXE 服务端的信息。(以及 DHCP Offer 本就包含的 ip 地址等信息)
PXE 的工作过程
第5讲 | 从物理层到MAC层:如何在宿舍里自己组网玩联机游戏?
数据链路层解决的三个问题
- 这个包是发给谁的?谁应该接收?
- 大家都在发,会不会产生混乱?有没有谁先发、谁后发的规则?
- 如果发送的时候出现了错误,怎么办?
数据链路层解决的三个问题的解决方案
- 通过 Medium Access Control,即媒体访问控制来解决问题2,简称 MAC。
- 信道划分: 分多车道,各走各的
- 轮流协议: 分单双号,轮着来
- 随机接入协议: 直接出发,发现特堵,就回去,错过高峰再出。
著名的以太网,用的就是这个方式。
- 引入一个物理地址的概念来解决问题1,叫作链路层地址。
但是因为第二层主要解决媒体接入控制的问题,所以它常被称为MAC 地址。
- 对于以太网,第二层的最后面是CRC,也就是循环冗余检测。通过 XOR 异或的算法,来计算整个包是否在发送的过程中出现了错误,主要解决问题3
ARP 协议
已知 IP 地址,求 MAC 地址的协议。主要解决源机器不知道目标机器地址的情况
集线器(Hub) 与 交换机(Switcher)
- 集线器工作在物理层,会将每一个端口发来的数据包,都复制到其他端口去
- 交换机工作在数据链路层,会根据转发表将数据包只发送至目标设备(端口)
交换机是有 MAC 地址学习能力的,学完了它就知道谁在哪儿了,不用广播了。
第6讲 | 交换机与VLAN:办公室太复杂,我要回学校
环路问题
- 环路问题会导致交换机记录的设备所在局域网信息不准确,并不停更新设备所在局域网信息
- 环路问题在数据结构中可以看做图
STP (Spanning Tree Protocol)
- 通过最小生成树算法,使得网络中的交换机相互比较生成一个树
- 树解决了图导致的环路问题
- STP 工作机制相关的概念
- Root Bridge,根交换机,即根
- Designated Bridges,指定交换机,即树枝
- Bridge Protocol Data Units(BPDU) ,网桥协议数据单元,即两个节点相互比较的协议
- Priority Vector,优先级向量,代表一个节点优先级的量,是一组 ID,
[Root Bridge ID, Root Path Cost, Bridge ID, and Port ID]
如何解决广播问题和安全问题?
- 物理隔离,每一个局域网的交换机等设备在物理上与其他网络的不可见
- 虚拟隔离,即 VLAN,或者叫虚拟局域网。在原来的二层的头上加一个 TAG,里面有一个 VLAN ID,一共 12 位。只有相同 VLAN 的包,才会互相转发
第7讲 | ICMP与ping:投石问路的侦察兵
ICMP 协议的格式
- ICMP全称Internet Control Message Protocol,就是互联网控制报文协议
- ICMP 报文是封装在 IP 包里面的。因为传输指令的时候,肯定需要源地址和目标地址
ICMP 报文类型
- 查询报文: 主动发起请求的报文,或主动请求应答的报文等
ping 就是查询报文
- 差错报文: 请求发生错误的报文
- 终点不可达
- 网络不可达,找不到对应网络
- 主机不可达: 找到了网络,找不到对应主机
- 协议不可达: 找到了主机,但协议不匹配
- 端口不可达: 找到了主机,协议匹配,但在目标端口上没有对应服务
- 需要进行分片但设置了不分片位,如数据包过大,在经过某些节点时需要分片发送,但设置了不允许分片
- 源站抑制,源站告知需要放慢发送速度。
- 时间超时
- 路由重定向
Traceroute 就是利用了差错报文进行工作的
- 终点不可达
第8讲 | 世界这么大,我想出网关:欧洲十国游与玄奘西行
请求目标 ip 的两种场景
- 目标 ip 与源 ip 同属一个网段,则直接通过 ARP 获取目标 ip 的 mac 地址,并发送请求
- 目标 ip 与源 ip 不属同一网段,则目标 mac 地址会改为网关 (Gateway) 对应的 mac,然后进行发送,之后由网关处理下一步转发
网关往往是一个路由器,是一个三层转发设备
静态路由下,通过网关转发的两种场景
- 不同网段不存在 ip 冲突的场景
- 目标 ip 与源 ip 不变,每次转发时,源 mac 地址是当前网关 mac,目标 mac 地址是下一个网关的 mac,直到发送至目标 ip 所属网段内,最后一次发送至目标设备
- 不同网段存在 ip 冲突的场景
更贴近实际生活中的场景,比如两个家庭的网段都是 192.168.1.0,可能源 ip 与目标 ip 都是 192.168.1.10
- 源 ip 与目标 ip 首先通过 NAT 服务转换为公网 ip,之后每次转发时,与上一种场景相同,只修改相应 mac 地址,知道发送至目标 ip 所属网段内,最后一次发送需要修改 ip 为目标在网段内的内网 ip
Network Address Translation,简称NAT。
两种场景下,ip 地址在转发期间都是不变的,区别在于是否需要通过 NAT 服务将 ip 转换为公网 ip
- 源 ip 与目标 ip 首先通过 NAT 服务转换为公网 ip,之后每次转发时,与上一种场景相同,只修改相应 mac 地址,知道发送至目标 ip 所属网段内,最后一次发送需要修改 ip 为目标在网段内的内网 ip
第9讲 | 路由协议:西出网关无故人,敢问路在何方
如何确定下一个转发目标?
- 当一个入口的网络包送到路由器时,它会根据一个本地的转发信息库,来决定如何正确地转发流量。这个转发信息库通常被称为路由表
一张路由表中会有多条路由规则。每一条规则至少包含这三项信息
- 目的网络:这个包想去哪儿?
- 出口设备:将包从哪个口扔出去?
- 下一跳网关:下一个路由器的地址。
策略路由 (仅用于静态路由)
- 在真实的复杂的网络环境中,除了可以根据目的 ip 地址配置路由外,还可以根据多个参数来配置路由,这就称为策略路由。
- 可以配置多个路由表,可以根据源 IP 地址、入口设备、TOS 等选择路由表,然后在路由表中查找路由。这样可以使得来自不同来源的包走不同的路由。
- 一条路由规则中,也可以走多条路径。比如设置下一跳有两个 ip,但有不同的权重。
动态路由
- 手动配置路由表,叫做静态路由
- 根据路由协议算法生成动态路由表,随网络运行状况的变化而变化,叫做动态路由
动态路由算法
- 动态路由算法本质是解决最短路径问题。网络中的设备组成一个网路图,两点之间的通信一定希望越近越快越好,因此是最短路径问题。
- 距离矢量路由算法 (基于 Bellman-Ford 算法)
- 基本思路: 每个路由器都保存一个路由表,包含多行,每行对应网络中的一个路由器,每一行包含两部分信息,一个是要到目标路由器,从哪条线出去,另一个是到目标路由器的距离。
- 更新策略: 每过几秒,每个路由器都将自己所知的到达所有的路由器的距离告知邻居,每个路由器也能从邻居那里得到相似的信息。
- 问题
- 好消息传得快,坏消息传得慢。新路由器加入的消息会很快得到广播,但有路由器挂掉是不会有广播的,可能得到一定时间后才回认为这个路由器掉线。
- 每次发送的时候,要发送整个全局路由表。当网络越来越大时,效能太差。
- 链路状态路由算法 (基于 Dijkstra 算法)
- 基本思路: 路由器每寻找到一个邻居,即将自己和邻居之间的链路状态包(距离信息等)广播出去,发送到整个网络的每个路由器。这样每个路由器都能够收到它和邻居之间的关系的信息。因而,每个路由器都能在自己本地构建一个完整的图,然后针对这个图使用 Dijkstra 算法,找到两点之间的最短路径。
- 更新策略: 链路状态路由协议只广播更新的或改变的网络拓扑
- 解决了距离矢量路由算法的两个问题
- 更新信息更小,节省了带宽和 CPU 利用率
- 一旦一个路由器挂了,它的邻居都会广播这个消息,可以使得坏消息迅速收敛
动态路由协议
- 基于链路状态路由算法的 OSPF (内网)
- OSPF(Open Shortest Path First,开放式最短路径优先)是一个基于链路状态路由协议,广泛应用在数据中心中的协议。
- 由于主要用在数据中心内部,用于路由决策,因而称为内部网关协议(Interior Gateway Protocol,简称IGP)。
- 内部网关协议的重点就是找到最短的路径。有时候 OSPF 可以发现多个最短的路径,可以在这多个路径中进行负载均衡,这常常被称为等价路由。
- 基于距离矢量路由算法的 BGP (外网)
- 每个数据中心都设置自己的 Policy。例如,哪些外部的 IP 可以让内部知晓,哪些内部的 IP 可以让外部知晓,哪些可以通过,哪些不能通过。
- 这一个个数据中心称为自治系统AS(Autonomous System)。自治系统分几种类型。
- Stub AS:对外只有一个连接。这类 AS 不会传输其他 AS 的包。例如,个人或者小公司的网络。
- Multihomed AS:可能有多个连接连到其他的 AS,但是大多拒绝帮其他的 AS 传输包。例如一些大公司的网络。
- Transit AS:有多个连接连到其他的 AS,并且可以帮助其他的 AS 传输包。例如主干网。
- BGP 又分为两类,eBGP 和 iBGP
- 自治系统间,边界路由器之间使用 eBGP 广播路由。
- 边界路由器将 BGP 学习到的路由导入到内部网络,就是通过运行 iBGP,使得内部的路由器能够找到到达外网目的地的最好的边界路由器。
- BGP 协议使用的算法是路径矢量路由协议(path-vector protocol)。它是距离矢量路由协议的升级版。
- 关于距离矢量路由协议收敛慢的问题: 在 BGP 里面,除了下一跳 hop 之外,还包括了自治系统 AS 的路径,从而可以避免坏消息传的慢的问题。比如 B 知道 C(内网) 原来能够到达 A(另一个内网),是因为通过自己(数据中心),一旦自己都到达不了 A 了,就不用假设 C 还能到达 A 了。
第10讲 | UDP协议:因性善而简单,难免碰到“城会玩”
TCP 和 UDP 有哪些区别?
- 连接类型
- TCP 是面向连接的
- UDP 是面向无连接的
所谓的建立连接,是为了在客户端和服务端维护连接,而建立一定的数据结构来维护双方交互的状态,用这样的数据结构来保证所谓的面向连接的特性。
- 可靠性
- TCP 提供可靠交付
- UDP 继承了 IP 包的特性,不保证不丢失,不保证按顺序到达
- 数据单元
- TCP 是面向字节流的
- UDP 继承了 IP 的特性,基于数据报的,一个一个地发,一个一个地收
- 可控性
- TCP 是可以有拥塞控制的
- UDP 不会,应用让我发,我就发
- 服务类型
- TCP 是一个有状态服务。里面精确地记着发送了没有,接收到没有,发送到哪个了,应该接收哪个了等等状态信息
- TCP 是一个无状态服务
UDP 的三大使用场景
- 需要资源少,在网络情况比较好的内网,或者对于丢包不敏感的应用
- 不需要一对一沟通,建立连接,而是可以广播的应用
- 需要处理速度快,时延低,可以容忍少数丢包,但是要求即便网络拥塞,也毫不退缩,一往无前的时候
基于 UDP 的五个例子
- 网页或者 APP 的访问
- HTTP 建立连接的成本太高,且连接虽然看似并发,但在 tcp 层还是一帧一帧发的,效率低。Google 则推出了一种基于 UDP 改进的通信协议 QUIC(全称Quick UDP Internet Connections,快速 UDP 互联网连接)
- 流媒体的协议
- 比如直播使用的 RTMP,直播中前一帧丢掉就丢掉了,继续播收到的下一帧就好
- 实时游戏
- TCP 需要消耗资源来维持长链接,游戏玩家一多,Server 的开销会大,另外则是 TCP 严格按照顺序发送,一旦有一个数据没送到,之后的都会阻塞,这在实时游戏中是不可接受的。因此,这里更适合采用自定义的可靠 UDP 协议
- IoT 物联网
- IoT 设备性能有限,维持 TCP 协议代价较大,另一方面 IoT 对延时十分敏感。Google 旗下的 Nest 建立 Thread Group,推出了物联网通信协议 Thread,就是基于 UDP 协议的。
- 移动通信领域
- 在 4G 网络里,移动流量上网的数据面对的协议 GTP-U 是基于 UDP 的。因为移动网络协议比较复杂,而 GTP 协议本身就包含复杂的手机上线下线的通信协议。如果基于 TCP,TCP 的机制就显得非常多余。
第11讲 | TCP协议(上):因性恶而复杂,先恶后善反轻松
TCP 包头主要关注的5个问题
- 顺序问题
- 丢包问题
- 连接维护
- 流量控制
- 拥塞控制
TCP 的三次握手
- 三次握手举例
- A:您好,我是 A。
- B:您好 A,我是 B。
- A:您好 B。
- 三次握手是 A B 双方都确认对方可以收到消息 (1,2 是 A 确认 B 可以收到消息;2,3 是 B 确认 A 可以收到消息)
- 三次握手除了双方建立连接外,主要还是为了沟通一件事情,就是TCP 包的序号的问题。
为什么序号不能都从 1 开始呢?
例如,A 连上 B 之后,发送了 1、2、3 三个包,但是发送 3 的时候,中间丢了,或者绕路了,于是重新发送,后来 A 掉线了,重新连上 B 后,序号又从 1 开始,然后发送 2,但是压根没想发送 3,但是上次绕路的那个 3 又回来了,发给了 B,B 自然认为,这就是下一个包,于是发生了错误。
TCP 四次挥手
- 四次挥手举例
- A:B 啊,我不想玩了。
- B:哦,你不想玩了啊,我知道了。
- B:A 啊,好吧,我也不玩了,拜拜。
- A:好的,拜拜。
- 四次挥手可能出现的意外
- A 说完“不玩了”之后,直接跑路,B 就算发起结束,也得不到回答,B 就不知道该怎么办了
- A 说完“不玩了”,B 直接跑路,因为 A 不知道 B 是还有事情要处理,还是过一会儿会发送结束
- A 直接跑路导致 A 的端口直接空出来了,B 原来发过的很多包很可能还在路上,如果 A 的端口被一个新的应用占用了,这个新的应用会收到上个连接中 B 发过来的包。
- 上述意外的解决方案
- TCP 协议专门设计了几个状态来处理可能出现的意外。参考下面的状态时序图
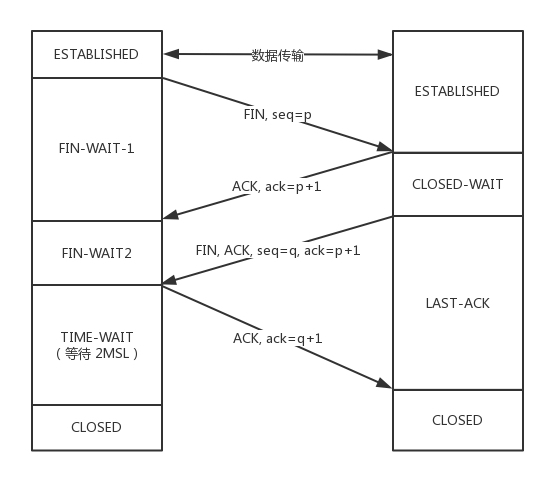
- MSL是Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
- TCP 协议专门设计了几个状态来处理可能出现的意外。参考下面的状态时序图
TCP 状态机
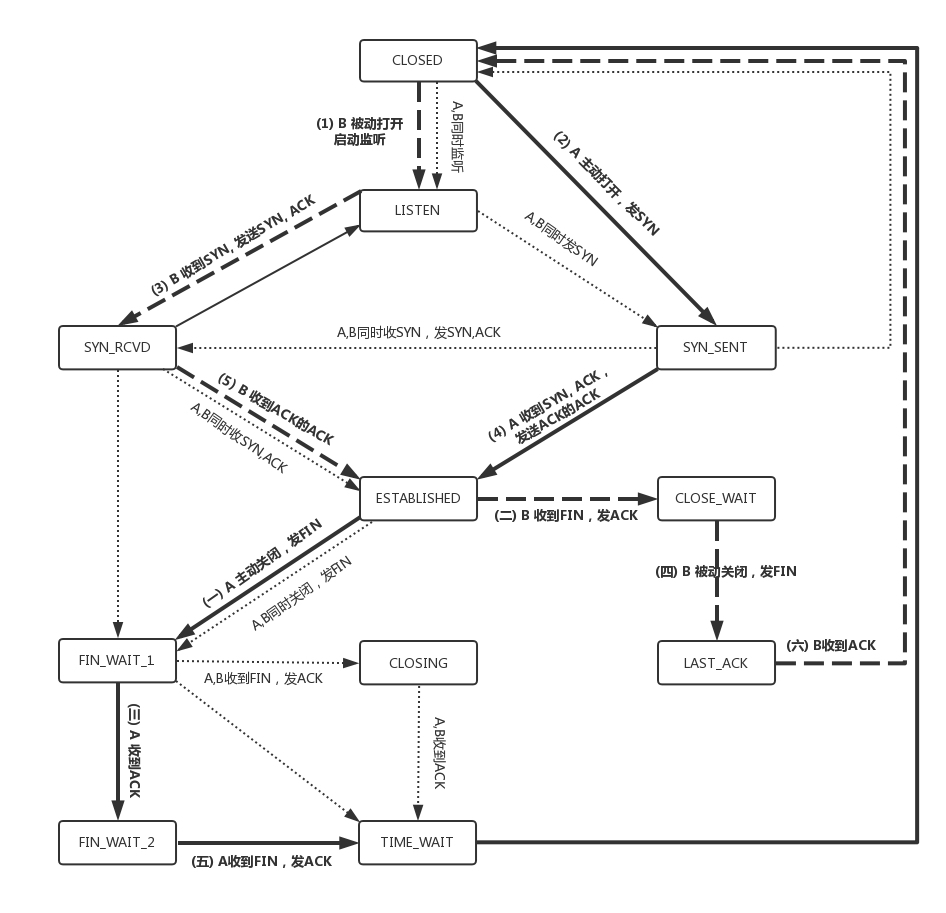
在这个图中,加黑加粗的部分,是上面说到的主要流程,其中阿拉伯数字的序号,是连接过程中的顺序,而大写中文数字的序号,是连接断开过程中的顺序。加粗的实线是客户端 A 的状态变迁,加粗的虚线是服务端 B 的状态变迁。
第12讲 | TCP协议(下):西行必定多妖孽,恒心智慧消磨难
累计确认/累计应答(cumulative acknowledgment)
- TCP 协议为了保证顺序性,每一个包都有一个 ID。在建立连接的时候,会商定起始的 ID 是什么,然后按照 ID 一个个发送。为了保证不丢包,对于发送的包都要进行应答,但是这个应答也不是一个一个来的,而是会应答某个之前的 ID,表示都收到了,这种模式称为累计确认或者累计应答。
TCP 发送端缓存
- 四部分缓存
- 发送了并且已经确认的
- 发送了并且尚未确认的
- 没有发送,但是已经等待发送的
- 没有发送
- 区分 3,4 部分的目的是实现流量控制。接收端会给发送端报一个窗口的大小,叫 Advertised window。这个窗口的大小应该等于上面的 2,3 部分之和,超出这个窗口大小的就是 4 部分
- 缓存数据结构
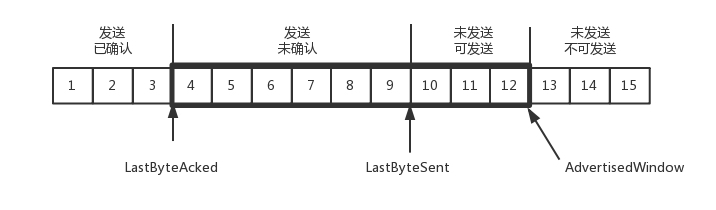
- LastByteAcked:1,2 部分的分界线
- LastByteSent:2,3 部分的分界线
- LastByteAcked + AdvertisedWindow:3,4 部分的分界线
TCP 接收端缓存
- 三部分缓存
- 接受并且确认过的
- 还没接收,但是马上就能接收的
- 还没接收,也没法接收的
- 缓存数据结构
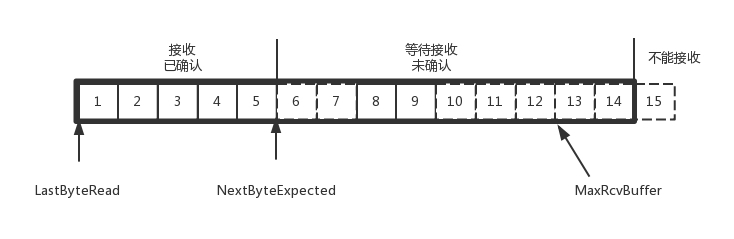
- MaxRcvBuffer:最大缓存的量
- LastByteRead 之后是已经接收了,但是还没被应用层读取的
- NextByteExpected 是 1,2 部分的分界线
超时重试
- 对每一个发送了,但是没有 ACK 的包,都有设一个定时器,超过了一定的时间,就重新尝试
- 超时时间的确认: TCP 通过采样 RTT 的时间,然后进行加权平均,算出一个值,而且这个值还随网络状况不断变化。除了采样 RTT,还要采样 RTT 的波动范围,计算出一个估计的超时时间。我们称为自适应重传算法(Adaptive Retransmission Algorithm)。
- 当一个包再次超时时,TCP 的策略是超时间隔加倍
- 加快超时重试的机制
- 当接收方收到一个序号大于下一个所期望的报文段时,就检测到了数据流中的一个间格,于是发送三个冗余的 ACK,客户端收到后,就在定时器过期之前,重传丢失的报文段。
- 还有一种方式称为 Selective Acknowledgment (SACK)。这种方式需要在 TCP 头里加一个 SACK 的东西,可以将缓存的地图发送给发送方。例如可以发送 ACK6、SACK8、SACK9,有了地图,发送方一下子就能看出来是 7 丢了。
流量控制
- 在对于包的确认中,同时会携带一个窗口的大小
通过上面的数据结构图,我们可以得到窗口大小的计算公式:
AdvertisedWindow=MaxRcvBuffer-((NextByteExpected-1)-LastByteRead)
- 对于发送端来说,每收到一个确认,窗口向右滑动一格,即可以再发送一个包,直到全部未发送可发送的包发送完毕
- 接收端本地处理太慢,导致缓存中没有空间,可以通过确认信息修改窗口的大小,甚至可以设置为 0,则发送方将暂时停止发送。
- 比如,接收端一直不读取缓存数据,则当一个包在接收端确认后,NextByteExpected 向右平移1,根据上述公式,AdvertisedWindow 会减小1,则确认包到达发送端时,发送端会修改 AdvertisedWindow,最终 AdvertisedWindow 可能减小为0,此时发送端停止发送
- 停止发送后,发送方会定时发送窗口探测数据包,看是否有机会调整窗口的大小。当接收方比较慢的时候,要防止低能窗口综合征,别空出一个字节来就赶快告诉发送方,然后马上又填满了,可以当窗口太小的时候,不更新窗口,直到达到一定大小,或者缓冲区一半为空,才更新窗口。
拥塞控制
- 前面的滑动窗口 rwnd 是怕发送方把接收方缓存塞满,而拥塞窗口 cwnd,是怕把网络塞满
- 这里有一个公式 LastByteSent - LastByteAcked <= min {cwnd, rwnd} ,是拥塞窗口和滑动窗口共同控制发送的速度。
根据发送端数据结构,可以看出,LastByteSent - LastByteAcked 就是发送了并且尚未确认的部分
- 网络上,通道的容量 = 带宽 × 往返延迟。网络带宽,即每秒钟能够发送多少数据。我们设置发送窗口,使得发送但未确认的包为为通道的容量,就能够撑满整个管道。
- 网络传输可能出现的问题
- 包丢失: 一个包,从一端到达另一端,假设一共经过四个设备,每个设备处理一个包时间耗费 1s,所以到达另一端需要耗费 4s,如果发送的更加快速,则单位时间内,会有更多的包到达这些中间设备,这些设备还是只能每秒处理一个包的话,多出来的包就会被丢弃
- 超时重传: 假如这个四个设备本来每秒处理一个包,但是我们在这些设备上加缓存,处理不过来的在队列里面排着,这样包就不会丢失,但是缺点是会增加时延,这个缓存的包,4s 肯定到达不了接收端了,如果时延达到一定程度,就会超时重传
- 慢启动: 一开始慢慢传输,然后发现总能收到确认,就可以越发越快
- 一条 TCP 连接开始,cwnd 设置为一个报文段,一次只能发送一个;当收到这一个确认的时候,cwnd 加一,于是一次能够发送两个;当这两个的确认到来的时候,每个确认 cwnd 加一,两个确认 cwnd 加二,于是一次能够发送四个;当这四个的确认到来的时候,每个确认 cwnd 加一,四个确认 cwnd 加四,于是一次能够发送八个。可以看出这是指数性的增长。
- 每收到一个确认后,cwnd 增加 1/cwnd,我们接着上面的过程来,一次发送八个,当八个确认到来的时候,每个确认增加 1/8,八个确认一共 cwnd 增加 1,于是一次能够发送九个,变成了线性增长。
- 慢启动,丢包与超时重传
- 慢启动传输速度的控制: 有一个值 ssthresh 为 65535 个字节,当超过这个值的时候,传输就会放慢
- 当丢包发生时,需要超时重传,这时将 sshresh 设为 cwnd/2,将 cwnd 设为 1,重新开始慢启动。
但是这种方式太激进了,将一个高速的传输速度一下子停了下来,会造成网络卡顿。
- 快速重传算法: 参见前面阐述过的部分,TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,cwnd 减半为 cwnd/2,然后 sshthresh = cwnd,当三个包返回的时候,cwnd = sshthresh + 3,整体上传输速度没有断崖式下跌,而是还在比较高的值,呈线性增长。
- 拥塞控制方案可能出现的问题
- 丢包并不代表着通道满了,也可能网络本身不稳定导致的丢包,这个时候就认为拥塞了,其实是不对的。
- TCP 的拥塞控制要等到将中间设备都填充满了,才发生丢包,从而降低速度,这时候已经晚了。其实 TCP 只要填满管道就可以了,不应该接着填,直到连缓存也填满。
- 为了优化上述两个问题,后来有了 TCP BBR 拥塞算法。它企图找到一个平衡点,就是通过不断的加快发送速度,将管道填满,但是不要填满中间设备的缓存,因为这样时延会增加,在这个平衡点可以很好的达到高带宽和低时延的平衡。
第13讲 | 套接字Socket:Talk is cheap, show me the code
基于 TCP 协议的 Socket 程序函数调用过程
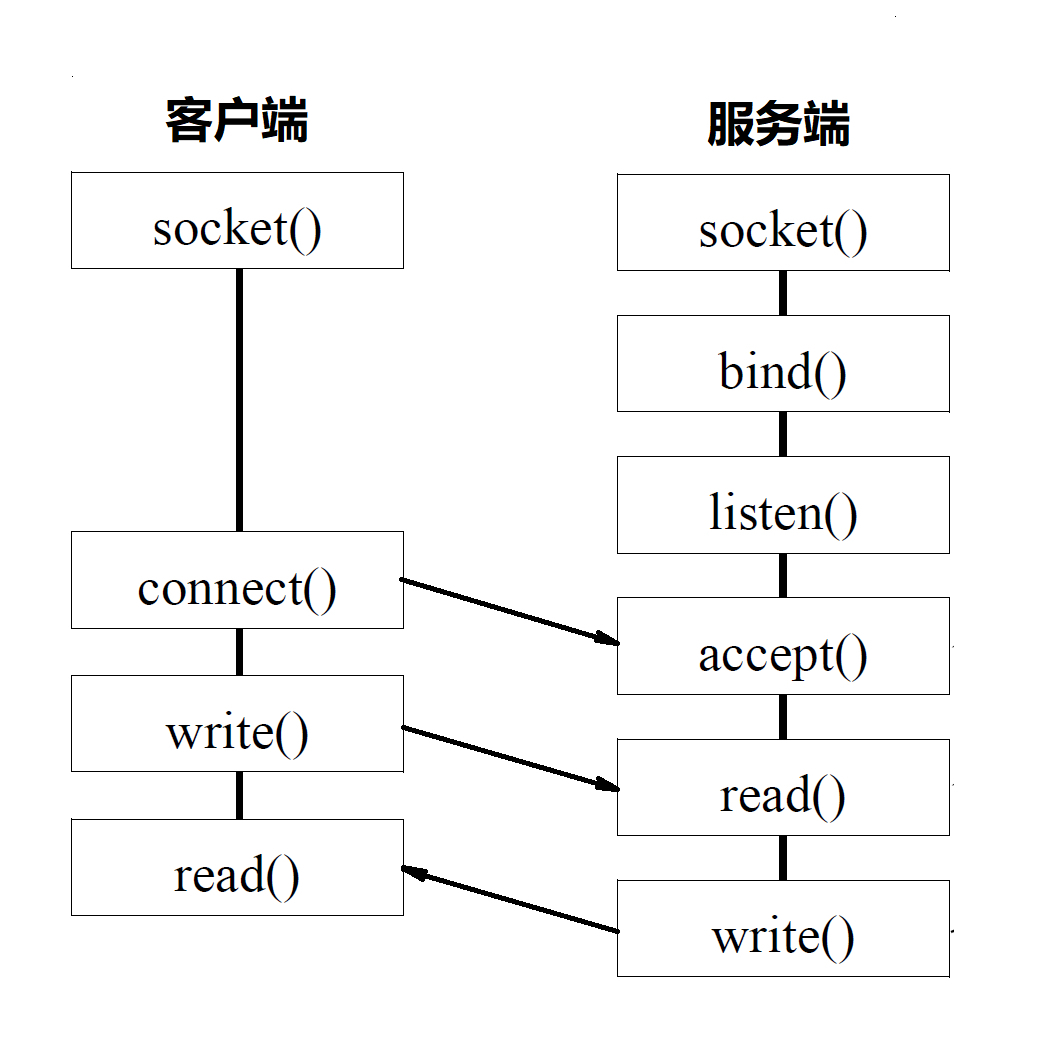
- TCP 的服务端要先监听一个端口,一般是先调用 bind 函数,给这个 Socket 赋予一个 IP 地址和端口。
- 为什么需要端口呢?当一个网络包来的时候,内核要通过 TCP 头里面的这个端口,来找到你这个应用程序,把包给你。
- 为什么要 IP 地址呢?一台机器会有多个网卡,也就会有多个 IP 地址,你可以选择监听所有的网卡,也可以选择监听一个网卡,这样,只有发给这个网卡的包,才会给你。
- 当服务端有了 IP 和端口号,就可以调用 listen 函数进行监听。这个时候客户端就可以发起连接了。
- 接下来,服务端调用 accept 函数,拿出一个已经完成的连接进行处理。如果还没有完成,就要等着。
在内核中,为每个 Socket 维护两个队列。一个是已经建立了连接的队列,这时候连接三次握手已经完毕,处于 established 状态;一个是还没有完全建立连接的队列,这个时候三次握手还没完成,处于 syn_rcvd 的状态。
- 在服务端等待的时候,客户端可以通过 connect 函数发起连接。先在参数中指明要连接的 IP 地址和端口号,然后开始发起三次握手。内核会给客户端分配一个临时的端口。一旦握手成功,服务端的 accept 就会返回另一个 Socket。
这是一个经常考的知识点,就是监听的 Socket 和真正用来传数据的 Socket 是两个,一个叫作监听 Socket,一个叫作已连接 Socket。
- 连接建立成功之后,双方开始通过 read 和 write 函数来读写数据,就像往一个文件流里面写东西一样。
基于 UDP 协议的 Socket 程序函数调用过程
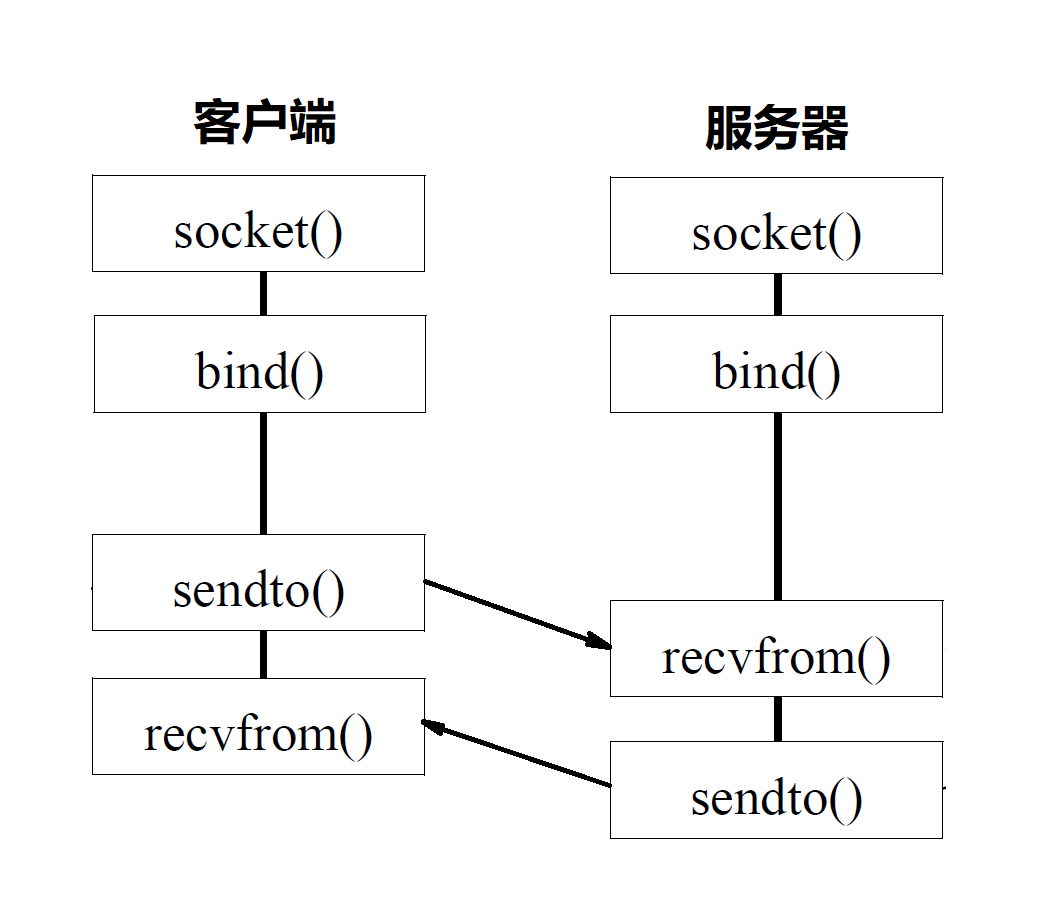
- 一般是先调用 bind 函数,给这个 Socket 赋予一个 IP 地址和端口。
UDP 是没有连接的,所以不需要三次握手,也就不需要调用 listen 和 connect。
- 调用 sendto 和 recvfrom 读写数据。
UDP 是没有维护连接状态的,因而不需要每对连接建立一组 Socket,而是只要有一个 Socket,就能够和多个客户端通信。也正是因为没有连接状态,每次通信的时候,都调用 sendto 和 recvfrom,都可以传入 IP 地址和端口。
基于 TCP 协议的 Socket 的文件流数据结构
- 说 TCP 的 Socket 就是一个文件流,是非常准确的。因为,Socket 在 Linux 中就是以文件的形式存在的。除此之外,还存在文件描述符。写入和读出,也是通过文件描述符。
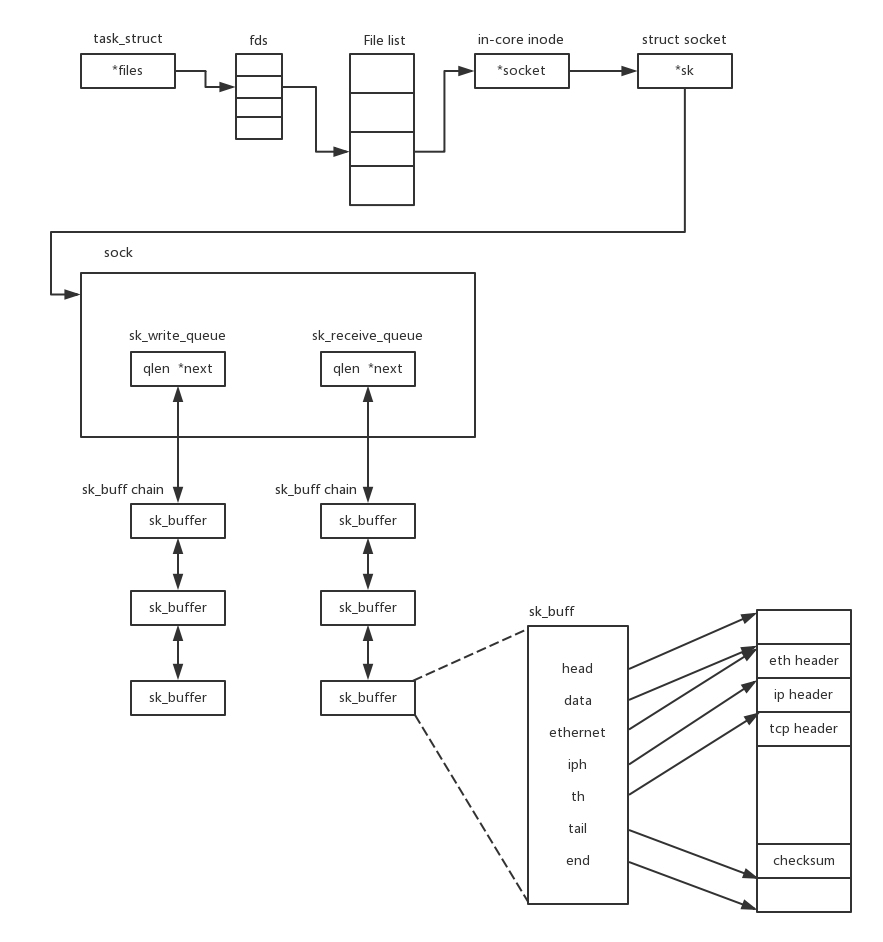
- 在内核中,Socket 是一个文件,那对应就有文件描述符。每一个进程都有一个数据结构 task_struct,里面指向一个文件描述符数组,来列出这个进程打开的所有文件的文件描述符。文件描述符是一个整数,是这个数组的下标。
- 这个数组中的内容是一个指针,指向内核中所有打开的文件的列表。既然是一个文件,就会有一个 inode,只不过 Socket 对应的 inode 不像真正的文件系统一样,保存在硬盘上的,而是在内存中的。在这个 inode 中,指向了 Socket 在内核中的 Socket 结构。
- 在这个结构里面,主要的是两个队列,一个是发送队列,一个是接收队列。在这两个队列里面保存的是一个缓存 sk_buff。这个缓存里面能够看到完整的包的结构。
这个包结构可以联想到之前网络层三层的内容,比如三层的 header
最大连接数
- 系统会用一个四元组来标识一个 TCP 连接。 服务器通常固定在某个本地端口上监听,等待客户端的连接请求。因此,服务端端 TCP 连接四元组中只有对端 IP, 也就是客户端的 IP 和对端的端口,也即客户端的端口是可变的,因此,最大 TCP 连接数 = 客户端 IP 数×客户端端口数。
1
{本机 IP, 本机端口, 对端 IP, 对端端口}
对 IPv4,客户端的 IP 数最多为 2 的 32 次方,客户端的端口数最多为 2 的 16 次方,也就是服务端单机最大 TCP 连接数,约为 2 的 48 次方。
- 服务端最大并发 TCP 连接数远不能达到理论上限
- 文件描述符限制: 按照上面的原理,Socket 都是文件,所以首先要通过 ulimit 配置文件描述符的数目
- 内存限制: 按上面的数据结构,每个 TCP 连接都要占用一定内存,操作系统是有限的。
服务器如何接更多的项目?
- 多进程
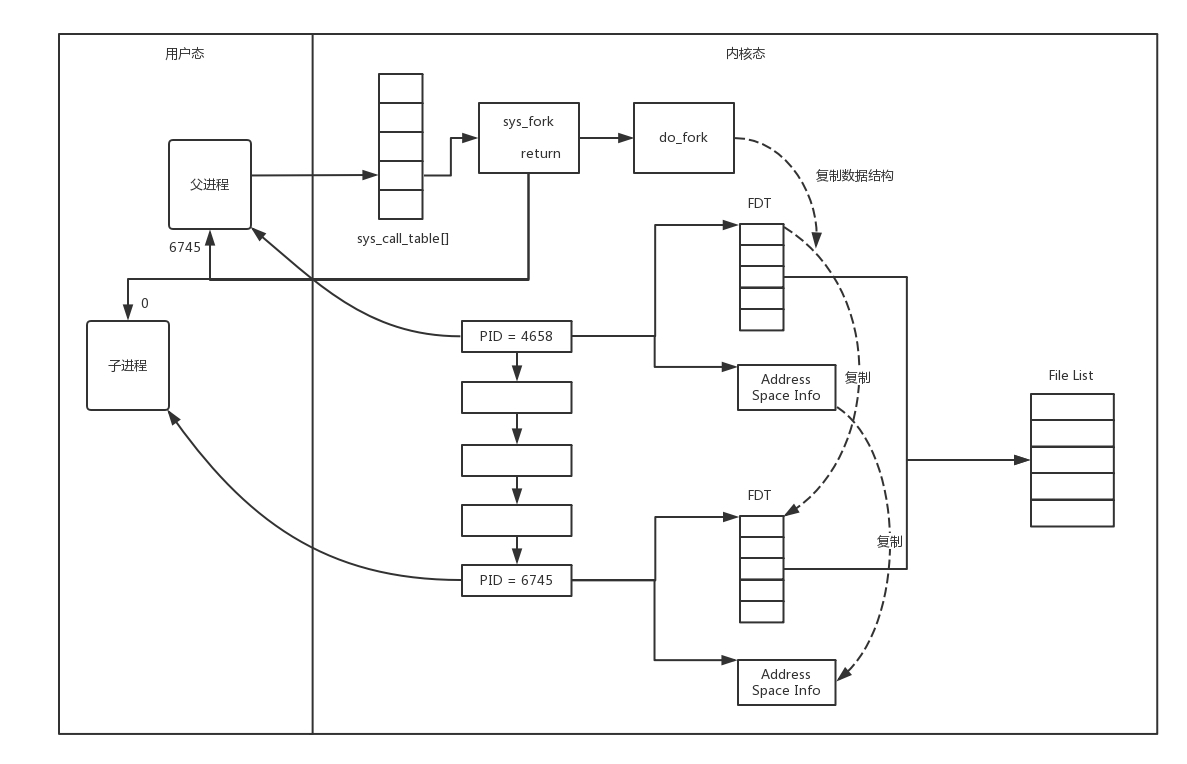
- 一旦建立了一个连接,就会有一个已连接 Socket,这时候你可以创建一个子进程,然后将基于已连接 Socket 的交互交给这个新的子进程来做。
- 因为复制了文件描述符列表,而文件描述符都是指向整个内核统一的打开文件列表的,因而父进程刚才因为 accept 创建的已连接 Socket 也是一个文件描述符,同样也会被子进程获得。
- 弊端
- 子进程每次创建和销毁的性能开销比较大,数量多后服务器无法支撑
- 多线程
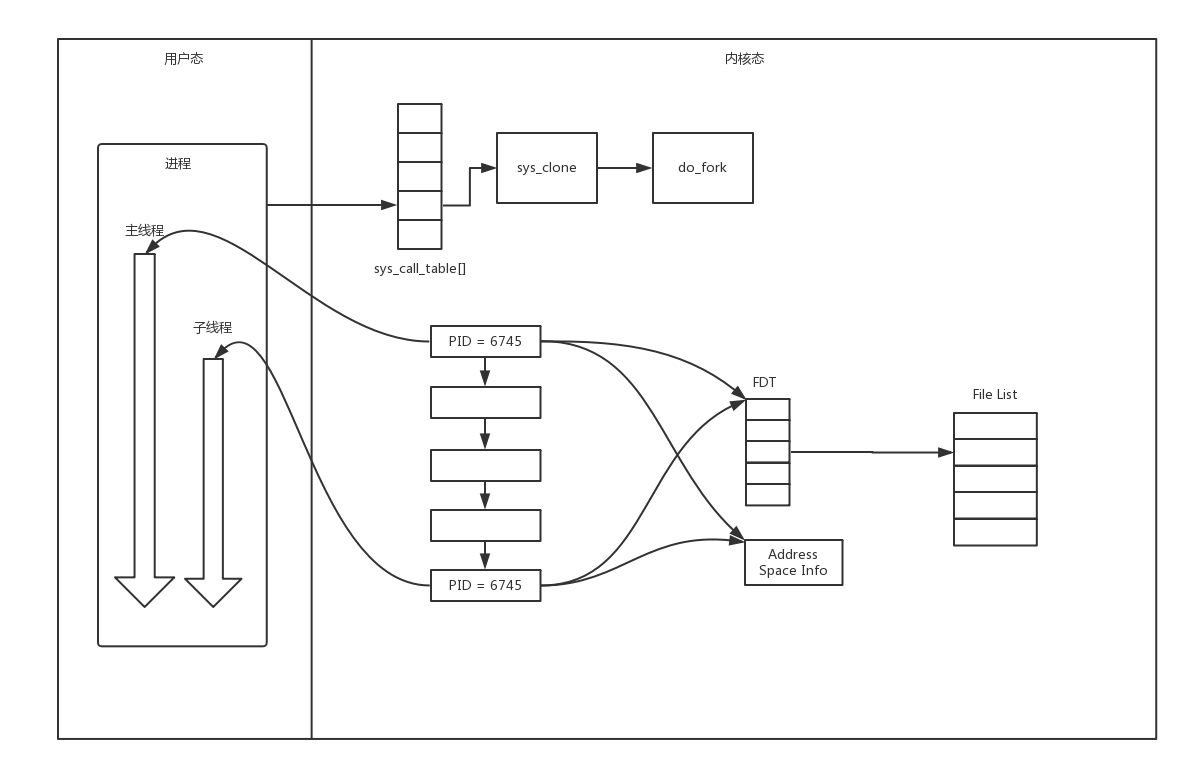
- 新的线程在 task 列表会新创建一项,但是很多资源,例如文件描述符列表、进程空间,还是共享的,只不过多了一个引用而已。
- 弊端
- C10K 问题: 它的意思是一台机器要维护 1 万个连接,就要创建 1 万个进程或者线程,那么操作系统是无法承受的。如果维持 1 亿用户在线需要 10 万台服务器,成本也太高了。
- IO 多路复用,一个线程维护多个 Socket
- 由于 Socket 是文件描述符,因而某个线程盯的所有的 Socket,都放在一个文件描述符集合 fd_set 中,然后调用 select 函数来监听文件描述符集合是否有变化。一旦有变化,就会依次查看每个文件描述符。
- 弊端
- 每次 Socket 所在的文件描述符集合中有 Socket 发生变化的时候,都需要通过轮询的方式,这大大影响了一个项目组能够支撑的最大的项目数量。因而使用 select,能够同时盯的项目数量由 FD_SETSIZE 限制。
- IO 多路复用,从“派人盯着”到“有事通知”
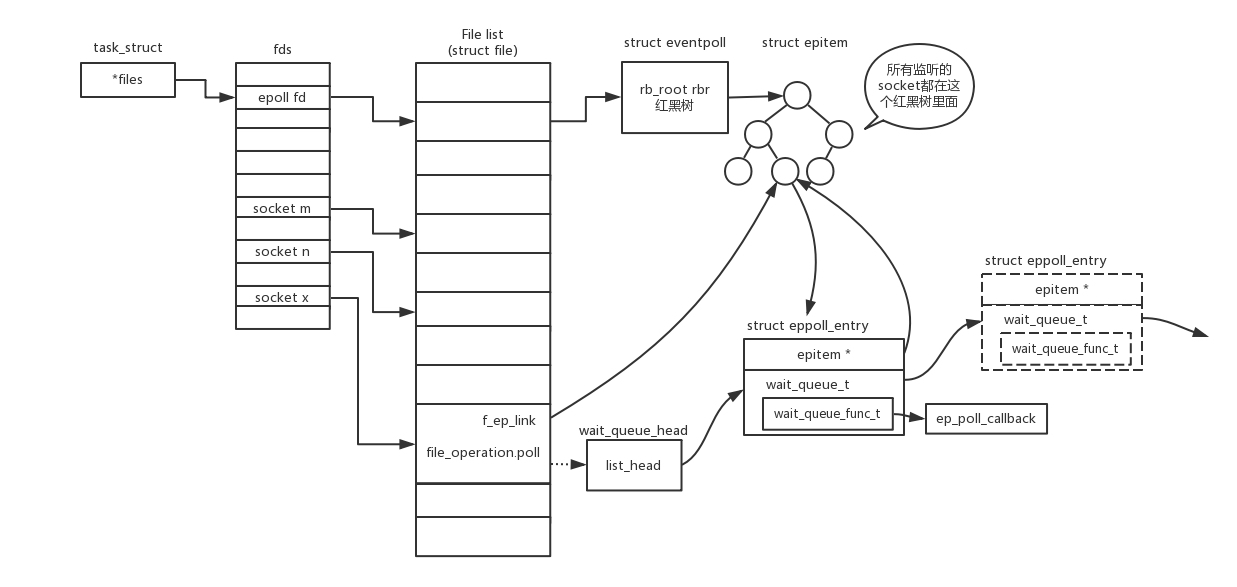
- epoll 函数: 它在内核中的实现不是通过轮询的方式,而是通过注册 callback 函数的方式,当某个文件描述符发送变化的时候,就会主动通知。
- 这种通知方式使得监听的 Socket 数据增加的时候,效率不会大幅度降低,能够同时监听的 Socket 的数目也非常的多了。上限就为系统定义的、进程打开的最大文件描述符个数。因而,epoll 被称为解决 C10K 问题的利器。
- epoll_create 创建一个 epoll 对象,也是一个文件,也对应一个文件描述符,同样也对应着打开文件列表中的一项。在这项里面有一个红黑树,在红黑树里,要保存这个 epoll 要监听的所有 Socket。
- epoll_ctl 添加一个 Socket 的时候,其实是加入这个红黑树,同时红黑树里面的节点指向一个结构,将这个结构挂在被监听的 Socket 的事件列表中。
- 当一个 Socket 来了一个事件的时候,可以从这个列表中得到 epoll 对象,并调用 call back 通知它。
第14讲 | HTTP协议:看个新闻原来这么麻烦
前面章节讲述的是传输层的内容,从这章开始是应用层的协议。
以 http://www.baidu.com 举例,这是个 URL,叫作统一资源定位符。正是因为这个东西是统一的,所以当你把这样一个字符串输入到浏览器的框里的时候,浏览器才知道如何进行统一处理。
HTTP 请求的准备
- 浏览器会将 www.baidu.com 这个域名发送给 DNS 服务器,让它解析为 IP 地址。
- HTTP 是基于 TCP 协议的,之后要先根据 IP 地址建立 TCP 连接,即三次握手。
目前使用的 HTTP 协议大部分都是 1.1。在 1.1 的协议里面,默认是开启了 Keep-Alive 的,这样建立的 TCP 连接,就可以在多次请求中复用。
HTTP 请求的构建
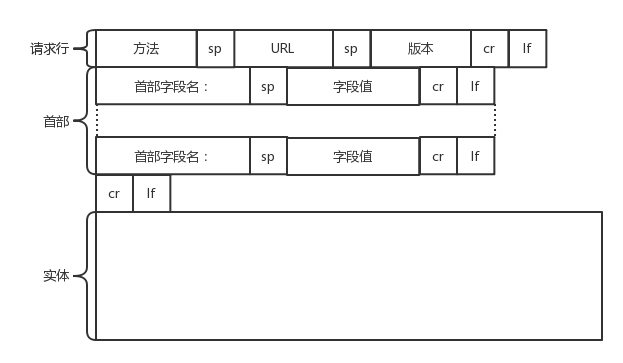
- 请求行
- 方法: GET,POST,PUT,DELETE 等
- 首部字段: key value 字段
- Accept-Charset,表示客户端可以接受的字符集
- Content-Type是指正文的格式
- …
- 正文实体
接下来,浏览器会把它交给下一层传输层。其实也无非是用 Socket 这些东西,只不过用的浏览器里,这些程序不需要你自己写,有人已经帮你写好了。
HTTP 请求的发送
- HTTP 协议是基于 TCP 协议的,所以它使用面向连接的方式发送请求,通过 stream 二进制流的方式传给对方。到了 TCP 层,它会把二进制流变成一个的报文段发送给服务器。
- 在发送给每个报文段的时候,都需要对方有一个回应 ACK,来保证报文可靠地到达了对方。如果没有回应,那么 TCP 这一层会进行重新传输,直到可以到达。同一个包有可能被传了好多次,但是 HTTP 这一层不需要知道这一点,因为是 TCP 这一层在埋头苦干。
- TCP 头里面还有端口号,HTTP 的服务器正在监听这个端口号。于是,目标机器自然知道是 HTTP 服务器这个进程想要这个包,于是将包发给 HTTP 服务器。HTTP 服务器的进程看到,原来这个请求是要访问一个网页,于是就把这个网页发给客户端。
HTTP 返回的构建
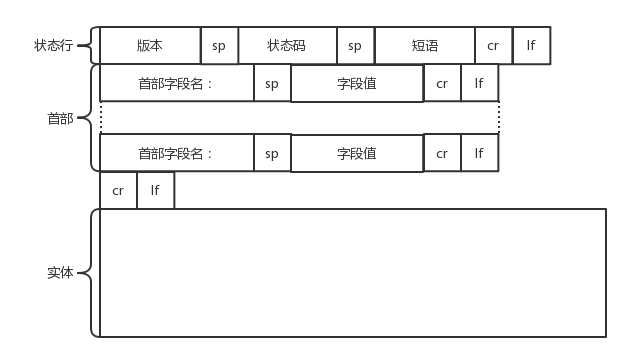
- 状态行
- 状态码: 反应 HTTP 请求的结果,如 200,404 等。
- 首部字段
- Retry-After表示,告诉客户端应该在多长时间以后再次尝试一下
- Content-Type,表示返回的是 HTML,还是 JSON
- …
- 正文实体
HTTP 返回的发送
- 构造好了返回的 HTTP 报文,还是交给 Socket 去发送,还是交给 TCP 层,让 TCP 层将返回的 HTML,也分成一个个小的段,并且保证每个段都可靠到达。
- 当浏览器拿到了 HTTP 的报文。发现返回“200”,一切正常,于是就从正文中将 HTML 拿出来。HTML 是一个标准的网页格式。浏览器只要根据这个格式,展示出一个绚丽多彩的网页。
HTTP 2.0
- HTTP 2.0 会对 HTTP 的头进行一定的压缩,将原来每次都要携带的大量 key value 在两端建立一个索引表,对相同的头只发送索引表中的索引。
- HTTP 2.0 协议中数据传输的切分
- HTTP 2.0 协议将一个 TCP 的连接中,切分成多个流,每个流都有自己的 ID,而且流可以是客户端发往服务端,也可以是服务端发往客户端。它其实只是一个虚拟的通道。流是有优先级的。
- HTTP 2.0 还将所有的传输信息分割为更小的消息和帧,并对它们采用二进制格式编码。常见的帧有Header 帧,用于传输 Header 内容,并且会开启一个新的流。再就是Data 帧,用来传输正文实体。多个 Data 帧属于同一个流。
- 通过这两种机制,HTTP 2.0 的客户端可以将多个请求分到不同的流中,然后将请求内容拆成帧,进行二进制传输。这些帧可以打散乱序发送, 然后根据每个帧首部的流标识符重新组装,并且可以根据优先级,决定优先处理哪个流的数据。
- 假设我们的一个页面要发送三个独立的请求,一个获取 css,一个获取 js,一个获取图片 jpg。如果使用 HTTP 1.1 就是串行的,但是如果使用 HTTP 2.0,就可以在一个连接里,客户端和服务端都可以同时发送多个请求或回应,而且不用按照顺序一对一对应。
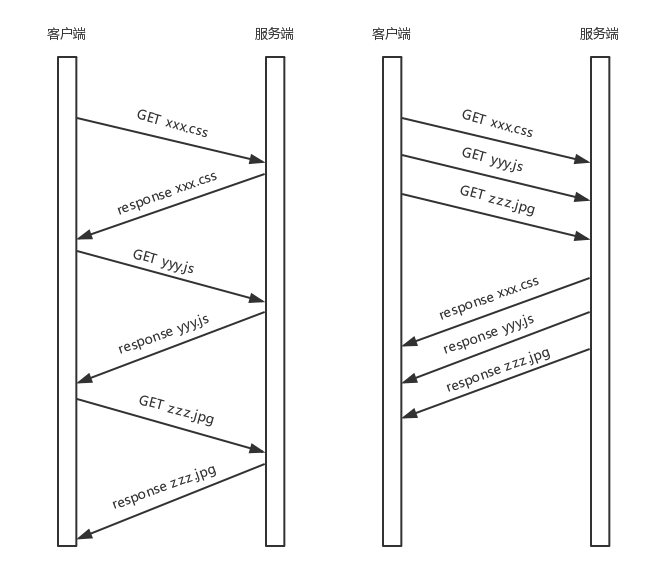
HTTP 2.0 其实是将三个请求变成三个流,将数据分成帧,乱序发送到一个 TCP 连接中。
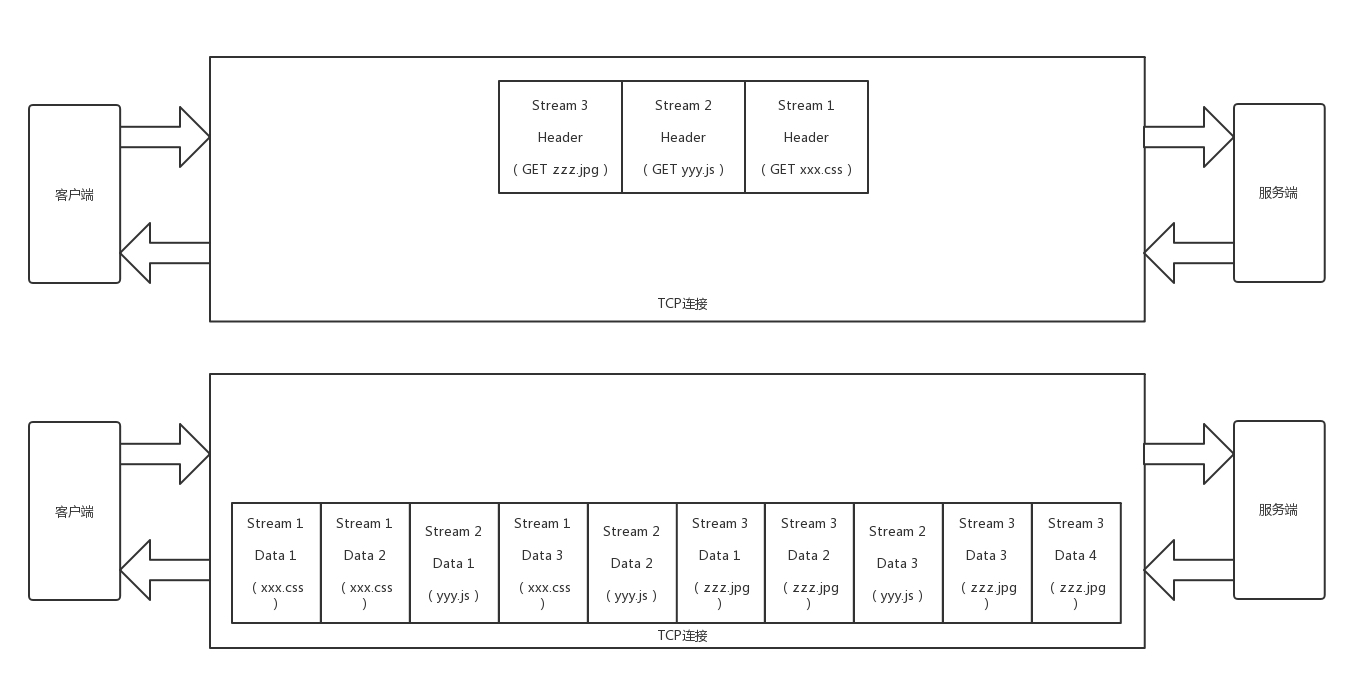
- HTTP 2.0 成功解决了 HTTP 1.1 的队首阻塞问题,同时,也不需要通过 HTTP 1.x 的 pipeline 机制用多条 TCP 连接来实现并行请求与响应;减少了 TCP 连接数对服务器性能的影响,同时将页面的多个数据 css、js、 jpg 等通过一个数据链接进行传输,能够加快页面组件的传输速度。
QUIC 协议
HTTP 2.0 虽然大大增加了并发性,但还是有问题的。因为 HTTP 2.0 也是基于 TCP 协议的,TCP 协议在处理包时是有严格顺序的。于是,就又到了从 TCP 切换到 UDP,这就是 Google 的 QUIC 协议。
- 自定义连接机制
- 一条 TCP 连接是由四元组标识的,分别是源 IP、源端口、目的 IP、目的端口。一旦一个元素发生变化时,就需要断开重连,重新连接。在移动互联情况下,当手机信号不稳定或者在 WIFI 和 移动网络切换时,都会导致重连,从而进行再次的三次握手,导致一定的时延。
- 基于 UDP,可以在 QUIC 自己的逻辑里面维护连接的机制,不再以四元组标识,而是以一个 64 位的随机数作为 ID 来标识,而且 UDP 是无连接的,所以当 IP 或者端口变化的时候,只要 ID 不变,就不需要重新建立连接。
- 自定义重传机制
- TCP 为了保证可靠性,通过使用序号和应答机制,来解决顺序问题和丢包问题。TCP 自适应重传算法的超时是通过采样往返时间 RTT不断调整的,这个采样存在不准确的问题。
例如,发送一个包,序号为 100,发现没有返回,于是再发送一个 100,过一阵返回一个 ACK101。这个时候客户端知道这个包肯定收到了,但是往返时间是多少呢?是 ACK 到达的时间减去后一个 100 发送的时间,还是减去前一个 100 发送的时间呢?事实是,第一种算法把时间算短了,第二种算法把时间算长了。
- QUIC 也有个序列号,是递增的。任何一个序列号的包只发送一次,下次就要加一了。
例如,发送一个包,序号是 100,发现没有返回;再次发送的时候,序号就是 101 了;如果返回的 ACK 100,就是对第一个包的响应。如果返回 ACK 101 就是对第二个包的响应,RTT 计算相对准确。
怎么知道包 100 和包 101 发送的是同样的内容呢?QUIC 定义了一个 offset 概念。QUIC 既然是面向连接的,也就像 TCP 一样,是一个数据流,发送的数据在这个数据流里面有个偏移量 offset,可以通过 offset 查看数据发送到了哪里,这样只要这个 offset 的包没有来,就要重发;如果来了,按照 offset 拼接,还是能够拼成一个流。
- TCP 为了保证可靠性,通过使用序号和应答机制,来解决顺序问题和丢包问题。TCP 自适应重传算法的超时是通过采样往返时间 RTT不断调整的,这个采样存在不准确的问题。
- 无阻塞的多路复用
- 同 HTTP 2.0 一样,同一条 QUIC 连接上可以创建多个 stream,来发送多个 HTTP 请求。但 QUIC 是基于 UDP 的,一个连接上的多个 stream 之间没有依赖。这样,假如 stream2 丢了一个 UDP 包,后面跟着 stream3 的一个 UDP 包,虽然 stream2 的那个包需要重传,但是 stream3 的包无需等待,就可以发给用户。
- 自定义流量控制
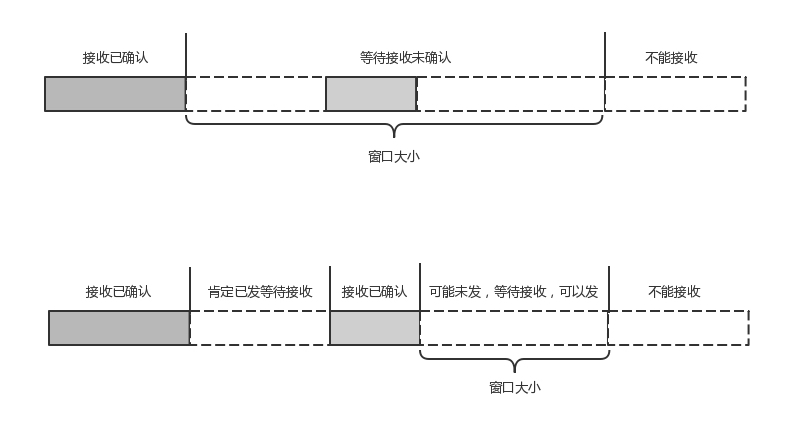
- TCP 的流量控制是通过滑动窗口协议。在 TCP 协议中,接收端的窗口的起始点是下一个要接收并且 ACK 的包,即便后来的包都到了,放在缓存里面,窗口也不能右移,因为 TCP 的 ACK 机制是基于序列号的累计应答,一旦 ACK 了一个系列号,就说明前面的都到了,所以只要前面的没到,后面的到了也不能 ACK,就会导致后面的到了,也有可能超时重传,浪费带宽。
- QUIC 的流量控制也是通过 window_update,来告诉对端它可以接受的字节数。但是 QUIC 的窗口是适应自己的多路复用机制的,不但在一个连接上控制窗口,还在一个连接中的每个 stream 控制窗口。QUIC 的 ACK 是基于 offset 的,每个 offset 的包来了,进了缓存,就可以应答,应答后就不会重发,中间的空挡会等待到来或者重发即可,而窗口的起始位置为当前收到的最大 offset,从这个 offset 到当前的 stream 所能容纳的最大缓存,是真正的窗口大小。显然,这样更加准确。
- 如图,上半部分为 TCP,下半部分为 QUIC
第15讲 | HTTPS协议:点外卖的过程原来这么复杂
加密方式
- 对称加密: 为保证密码安全性,只能通过线下传输。在互联网应用中,客户太多,这样是不行的。
- 非对称加密: 中间拦截拿到数据后因为没有私钥也无法解密,且公钥可以在网络上传输,公钥无法解密,服务提供商只要保证自己私钥的安全性即可。
数字证书 (Certificate)
- 数字证书包含的内容
- 公钥
- 证书的所有者
- 证书的发布机构
- 证书的有效期
- 证书签名
- 将证书发给权威机构 CA(Certificate Authority),权威机构会给这个证书盖一个章,我们称为签名算法
- 只有用 CA 的私钥签名的证书,才能保证证书签名的真实性,之后可以通过 CA 的公钥进行解密以验证其真实性
- 签名证书包含的内容
- Issuer: 证书是谁颁发的
- Subject: 证书颁发给谁
- Validity: 证书期限
- Public-key: 服务端公钥(不是证书机构的公钥,证书机构的公钥是用于验证证书真实性的)
- Signature Algorithm: 签名算法
- 如何确保 CA 机构的可靠,以及其公钥的可靠?
- 找更有公信力的 CA 进行二次签名,依次类推,直到全球皆知的几个著名大 CA,称为root CA,做最后的背书。通过这种层层授信背书的方式,从而保证了非对称加密模式的正常运转。
- 还有一种证书,称为Self-Signed Certificate,就是自己给自己签名。这个给人一种“我就是我,你爱信不信”的感觉。
这些工作都是为了确保别人给你的公钥是对的。避免有中间拦截者冒充服务端,发给你一个它的自己的假冒公钥。否则之后你与服务端的通信都是与假冒网站通信了。
HTTPS 的工作模式
HTTPS 是综合了对称加密和非对称加密算法的 HTTP 协议。既保证传输安全,也保证传输效率。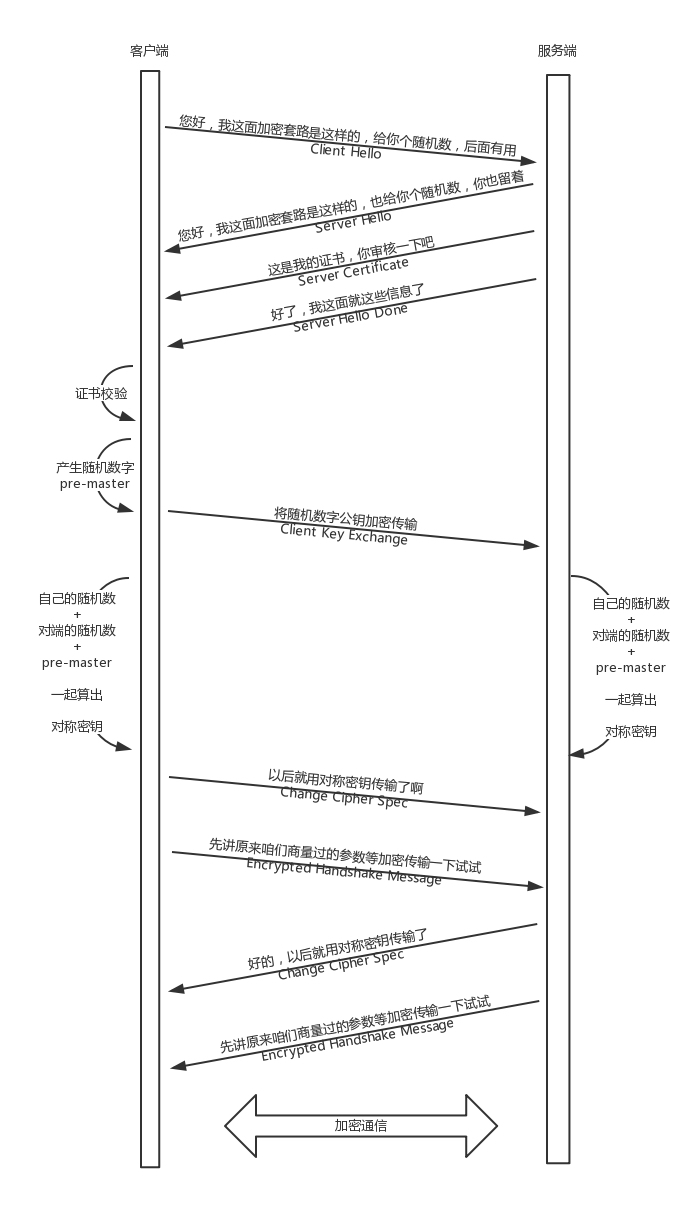
- 客户端会发送 Client Hello 消息到服务器,以明文传输 TLS 版本信息、加密套件候选列表、压缩算法候选列表等信息。另外,还会有一个随机数,用于后续的对称密钥协商。
- 服务端返回 Server Hello 消息, 告诉客户端,服务器选择使用的协议版本、加密套件、压缩算法等,还有一个随机数,用于后续的对称密钥协商。
- 服务端返回给客户端一个服务器端的证书
- 服务端返回 “Server Hello Done,我这里就这些信息了。”
- 客户端从自己信任的 CA 仓库中,拿 CA 的证书里面的公钥去解密服务端的证书。如果能够成功,则说明外卖网站是可信的。这个过程中,可能会不断往上追溯 CA、CA 的 CA、CA 的 CA 的 CA,直到一个授信的 CA。
- 客户端计算产生随机数字 Pre-master,发送 Client Key Exchange,用证书中的公钥加密,再发送给服务器,服务器可以通过私钥解密出来。
- 到目前为止,客户端与服务器都有了三个随机数,分别是:自己的、对端的,以及刚生成的 Pre-Master 随机数。通过这三个随机数,可以在客户端和服务器产生相同的对称密钥。
- 客户端发送 Change Cipher Spec,说:“咱们以后都采用协商的通信密钥和加密算法进行加密通信了。”
- 客户端发送 Encrypted Handshake Message,将已经商定好的参数等,采用协商密钥进行加密,发送给服务器用于数据与握手验证。
- 服务端发送 Change Cipher Spec,说:“没问题,咱们以后都采用协商的通信密钥和加密算法进行加密通信了”
- 服务端发送 Encrypted Handshake Message 的消息试试。当双方握手结束之后,就可以通过对称密钥进行加密传输了。
重放与篡改
虽然 https 无法被黑客解密,但是黑客可以直接复制请求包,并多次重复向服务端发送,这被称之为重放
可以使用 Timestamp 和 Nonce 解决重放与篡改的问题
- Timestamp 是时间戳,Nonce 是客户端生成的随机数,Nonce 随机数保证唯一,或者 Timestamp 和 Nonce 合起来保证唯一,然后两者结合做一个不可逆的签名来保证。
- 服务端对于请求只接受一次,当服务端多次受到相同的 Timestamp 和 Nonce,则视为无效即可。
- 如果有人想篡改 Timestamp 和 Nonce,还有签名保证不可篡改性,如果改了用签名算法解出来,就对不上了,可以丢弃。
第16讲 | 流媒体协议:如何在直播里看到美女帅哥?
视频编码其实就是一个压缩的过程
如果不压缩,以一个1分钟长度,30帧,720p的视频举例,每个像素由 RGB 组成,每个数值8位,一共24位,则视频大小为 1280 * 720 * 24 * 30帧 * 60s = 39813120000 Bytes ≈ 40GB,因此需要视频压缩(编码)来减小视频大小。
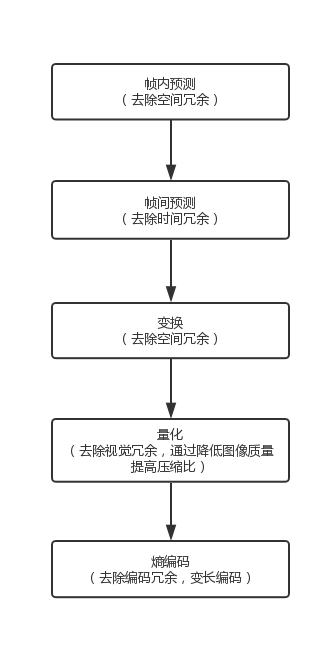
视频和图片的压缩过程的特点
- 空间冗余:图像的相邻像素之间有较强的相关性,一张图片相邻像素往往是渐变的,不是突变的,没必要每个像素都完整地保存,可以隔几个保存一个,中间的用算法计算出来。
- 时间冗余:视频序列的相邻图像之间内容相似。一个视频中连续出现的图片也不是突变的,可以根据已有的图片进行预测和推断。
- 视觉冗余:人的视觉系统对某些细节不敏感,因此不会每一个细节都注意到,可以允许丢失一些数据。
- 编码冗余:不同像素值出现的概率不同,概率高的用的字节少,概率低的用的字节多,类似霍夫曼编码(Huffman Coding)的思路。
视频编码流程,可以参考下图:
视频编码的规范
- 两大流派
- ITU(International Telecommunications Union)的 VCEG(Video Coding Experts Group),这个称为国际电联下的 VCEG。
诸如 H.261、 H.262、H.263、H.264、H.265 就是这个组织制定的标准
- ISO(International Standards Organization)的 MPEG(Moving Picture Experts Group),这个是ISO 旗下的 MPEG。
诸如 MPEG-1、MPEG-2、MPEG-4、MPEG-7 就是这个组织制定的标准
- ITU(International Telecommunications Union)的 VCEG(Video Coding Experts Group),这个称为国际电联下的 VCEG。
- 后来,ITU-T 与 MPEG 联合制定了 H.264/MPEG-4 AVC
- 经过编码之后,图像就变成了二进制数据,这个二进制可以放在一个文件里面,按照一定的格式保存起来。
诸如 AVI、MPEG、RMVB、MP4、MOV、FLV、WebM、WMV、ASF、MKV 就是所谓的格式。例如,前几个字节是什么意义,后几个字节是什么意义,然后是数据,数据中保存的就是编码好的结果。
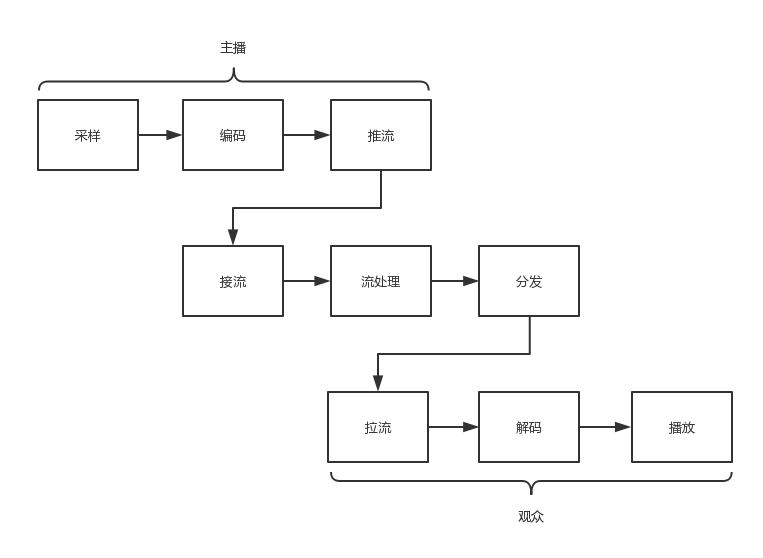
直播的原理
- 前提: 视频编码后的二进制数据可以通过某种网络协议进行封装,放在互联网上传输
- 接流: 网络协议将编码好的视频流,从主播端推送到服务器,在服务器上有个运行了同样协议的服务端来接收这些网络包,从而得到里面的视频流,这个过程称为接流。
- 服务端转码: 服务端接到视频流之后,可以对视频流进行一定的处理,例如转码,也即从一个编码格式,转成另一种格式。转码的目的是保证视频流在服务端的格式一致,方便服务端针对视频流做一些统一处理,以及后续的拉流等操作。
- 拉流: 流处理完毕之后,就可以等待观众的客户端来请求这些视频流。观众的客户端请求的过程称为拉流。
- 分发: 同时看一个视频直播,那都从一个服务器上拉流,压力太大了,因而需要一个视频的分发网络,将视频预先加载到就近的边缘节点,这样大部分观众看的视频,是从边缘节点拉取的,就能降低服务器的压力。
- 客户端解码: 当观众的客户端将视频流拉下来之后,就需要进行解码,也即通过上述过程的逆过程,将一串串看不懂的二进制,再转变成一帧帧图片,在客户端播放出来。
整个直播流程可以用下图描述
编码的原理
首先将视频中的图片分为三种帧
- I 帧,也称关键帧。里面是完整的图片,只需要本帧数据,就可以完成解码。
- P 帧,前向预测编码帧。P 帧表示的是这一帧跟之前的一个关键帧(或 P 帧)的差别,解码时需要用之前缓存的画面,叠加上和本帧定义的差别,生成最终画面。
- B 帧,双向预测内插编码帧。B 帧记录的是本帧与前后帧的差别。要解码 B 帧,不仅要取得之前的缓存画面,还要解码之后的画面,通过前后画面的数据与本帧数据的叠加,取得最终的画面。
编码结构
)
- 时间上的编码: I 帧最完整,B 帧压缩率最高,而压缩后帧的序列,应该是在 IBBP 的间隔出现的。这就是通过时序进行编码。
- 空间上的编码: 在一帧中,分成多个片,每个片中分成多个宏块,每个宏块分成多个子块,这样将一张大的图分解成一个个小块,可以方便进行空间上的编码。
解码,则按照类似的下图顺序,先解码一个 I,接着是 I 之后的一个 P,然后解码 I P 之间的 B,以此类推

编码转换为二进制流
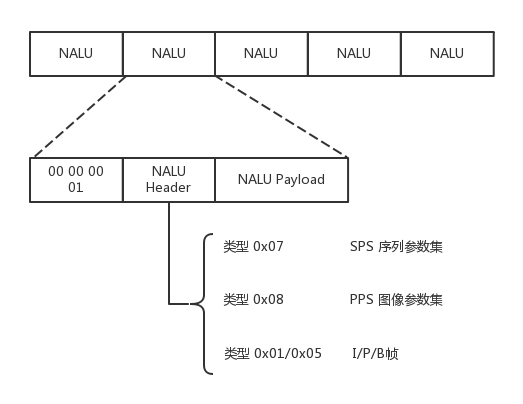
这个流的结构是一个个的网络提取层单元(NALU,Network Abstraction Layer Unit)。变成这种格式就是为了传输,因为网络上的传输,默认的是一个个的包,因而这里也就分成了一个个的单元。- NALU 首先是一个起始标识符,用于标识 NALU 之间的间隔
- 然后是 NALU 的头,里面主要配置了 NALU 的类型,NALU 头里面,主要的内容是类型NAL Type。
- 0x07 表示 SPS,是序列参数集, 包括一个图像序列的所有信息,如图像尺寸、视频格式等。
- 0x08 表示 PPS,是图像参数集,包括一个图像的所有分片的所有相关信息,包括图像类型、序列号等。
- 最终 Payload 里面是 NALU 承载的数据。
总结: 一个视频,可以拆分成一系列的帧,每一帧拆分成一系列的片,每一片都放在一个 NALU 里面,NALU 之间都是通过特殊的起始标识符分隔,在每一个 I 帧的第一片前面,要插入单独保存 SPS 和 PPS 的 NALU,最终形成一个长长的 NALU 序列。
推流:如何把数据流打包传输到对端?(基于 RTMP 协议)
- RTMP 是基于 TCP 的,因而肯定需要双方建立一个 TCP 的连接。在有 TCP 的连接的基础上,还需要建立一个 RTMP 的连接。
- RMTP 连接主要确认版本号与时间戳,以保证之后的传输能正常进行。如果客户端、服务器的版本号不一致,则不能工作。视频播放中,时间是很重要的,后面的数据流互通的时候,经常要带上时间戳的差值,因而一开始双方就要知道对方的时间戳。
- RMTP 连接的建立,需要发送六条消息:客户端发送 C0、C1、 C2,服务器发送 S0、 S1、 S2。
- 首先,客户端发送 C0 表示自己的版本号,不必等对方的回复,然后发送 C1 表示自己的时间戳。
- 服务器只有在收到 C0 的时候,才能返回 S0,表明自己的版本号,如果版本不匹配,可以断开连接。
- 服务器发送完 S0 后,无需等待,直接发送自己的时间戳 S1。客户端收到 S1 的时候,发一个知道了对方时间戳的 ACK C2。同理服务器收到 C1 的时候,发一个知道了对方时间戳的 ACK S2。
- RMTP 连接建立成功,之后可以开始视频流的传输
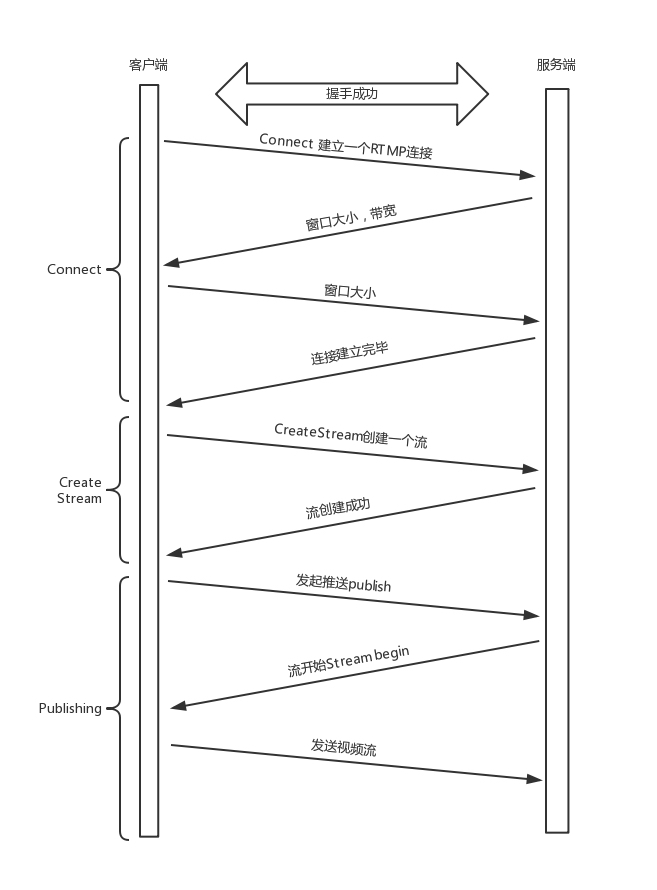
- 双方需要互相传递一些控制信息,例如 Chunk 块的大小、窗口大小等。
- 真正传输数据的时候,还是需要创建一个流 Stream,然后通过这个 Stream 来推流 publish。
- 推流的过程,就是将 NALU 放在 Message 里面发送,这个也称为RTMP Packet 包。Message 的格式就像这样。
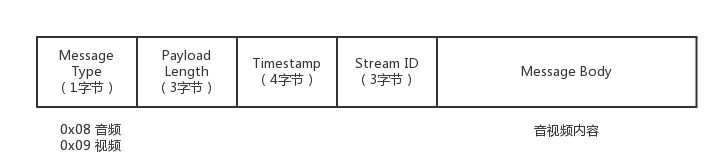
RTMP 在收发数据的时候并不是以 Message 为单位的,而是把 Message 拆分成 Chunk 发送,而且必须在一个 Chunk 发送完成之后,才能开始发送下一个 Chunk。每个 Chunk 中都带有 Message ID,表示属于哪个 Message,接收端也会按照这个 ID 将 Chunk 组装成 Message。
拉流:观众的客户端如何看到视频?
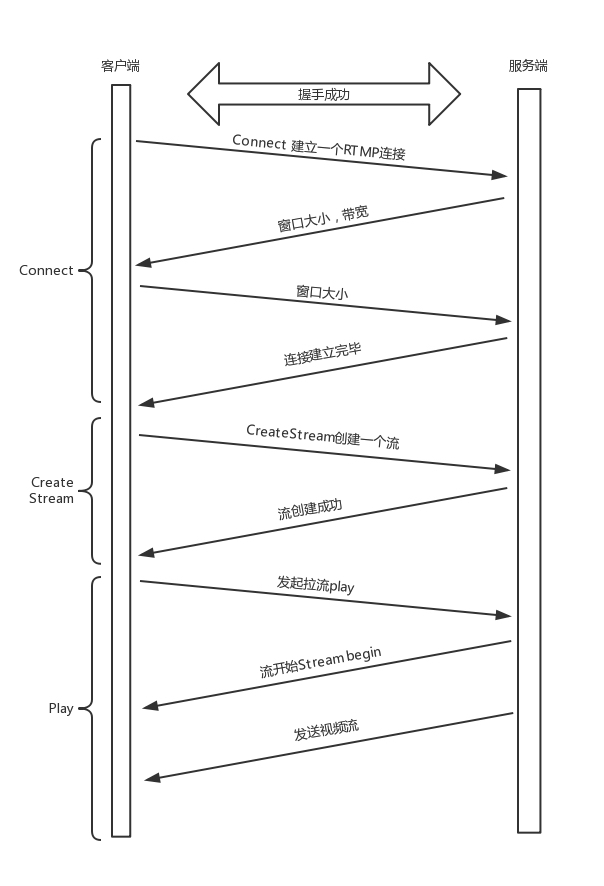
- 先读到的是 H.264 的解码参数,例如 SPS 和 PPS
- 然后对收到的 NALU 组成的一个个帧
- 进行解码,交给播发器播放
第17讲 | P2P协议:我下小电影,99%急死你
FTP(文件传输协议)
FTP 采用两个 TCP 连接来传输一个文件
- 控制连接:服务器以被动的方式,打开众所周知用于 FTP 的端口 21,客户端则主动发起连接。该连接将命令从客户端传给服务器,并传回服务器的应答。常用的命令有:list——获取文件目录;reter——取一个文件;store——存一个文件。
- 数据连接:每当一个文件在客户端与服务器之间传输时,就创建一个数据连接。
FTP 的两种工作模式,这两种模式都是站在 FTP 服务器的角度来说的。
- 主动模式(PORT):客户端随机打开一个大于 1024 的端口 N,向服务器的命令端口 21 发起连接,同时开放 N+1 端口监听,并向服务器发出 “port N+1” 命令,由服务器从自己的数据端口 20,主动连接到客户端指定的数据端口 N+1。
- 被动模式(PASV):客户端打开两个任意的本地端口 N(大于 1024)和 N+1。第一个端口连接服务器的 21 端口,提交 PASV 命令。然后,服务器会开启一个任意的端口 P(大于 1024),返回“227 entering passive mode”消息,里面有 FTP 服务器开放的用来进行数据传输的端口。客户端收到消息取得端口号之后,会通过 N+1 号端口连接服务器的端口 P,然后在两个端口之间进行数据传输。
P2P
- P2P,即 peer-to-peer。资源开始并不集中地存储在某些设备上,而是分散地存储在多台设备上。这些设备我们姑且称为 peer。
想要下载一个文件的时候,你只要得到那些已经存在了文件的 peer,并和这些 peer 之间,建立点对点的连接,而不需要到中心服务器上,就可以就近下载文件。一旦下载了文件,你也就成为 peer 中的一员,你旁边的那些机器,也可能会选择从你这里下载文件。
- P2P 解决了 HTTP/FTP 等方式存在的单一服务器的带宽压力问题
种子(.torrent)文件
种子,即 .torrent 文件,由两部分组成,分别是:announce(tracker URL)和文件信息。
文件信息中包含如下内容
- info 区:这里指定的是该种子有几个文件、文件有多长、目录结构,以及目录和文件的名字。
- Name 字段:指定顶层目录名字。
- 每个段的大小:BitTorrent(简称 BT)协议把一个文件分成很多个小段,然后分段下载。
- 段哈希值:将整个种子中,每个段的 SHA-1 哈希值拼在一起。
下载流程
- BT 客户端首先解析.torrent 文件,得到 tracker 地址,然后连接 tracker 服务器。
- tracker 服务器回应下载者的请求,将其他下载者(包括发布者)的 IP 提供给下载者。
- 下载者连接其他下载者,根据.torrent 文件,两者分别对方告知自己已经有的块,然后交换对方没有的数据。
此时不需要其他服务器参与,并分散了单个线路上的数据流量,因此减轻了服务器的负担。
- 下载者每得到一个块,需要算出下载块的 Hash 验证码,并与.torrent 文件中的对比。如果一样,则说明块正确,不一样则需要重新下载这个块。这种规定是为了解决下载内容的准确性问题。
P2P 的弊端
- 一旦 tracker 服务器出现故障或者线路遭到屏蔽,BT 工具就无法正常工作了。虽然下载的过程是非中心化的,但是加入这个 P2P 网络的时候,都需要借助 tracker 中心服务器,这个服务器是用来登记有哪些用户在请求哪些资源。
去中心化网络(DHT)
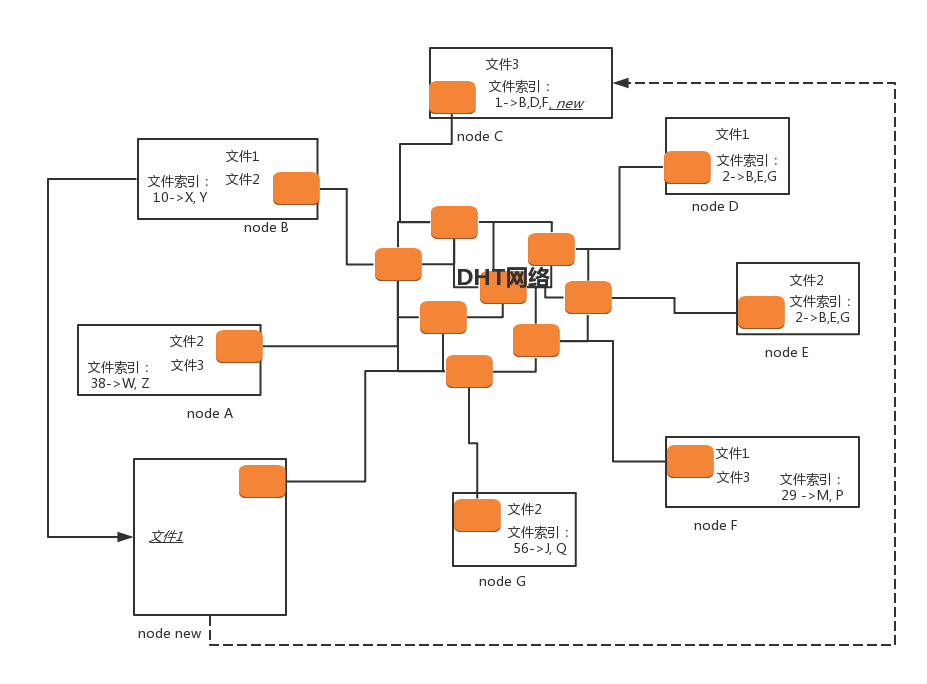
- 每个加入这个 DHT 网络的人,都要负责存储这个网络里的资源信息和其他成员的联系信息,相当于所有人一起构成了一个庞大的分布式存储数据库。
- 有一种著名的 DHT 协议,叫Kademlia 协议。
- 任何一个 BitTorrent 启动之后,它都有两个角色
- 一个是peer,监听一个 TCP 端口,用来上传和下载文件,这个角色表明,我这里有某个文件。
- 另一个角色DHT node,监听一个 UDP 的端口,通过这个角色,这个节点加入了一个 DHT 的网络。
- 每一个 DHT node 都有一个 ID。每个 DHT node 都有责任掌握一些文件索引,也即它应该知道某些文件是保存在哪些节点上。但它自己本身不一定就是保存这个文件的节点。
DHT node 应该知道哪部分文件的索引?
每个文件可以计算出一个哈希值,而DHT node 的 ID 是和哈希值相同长度的串。
DHT 算法是这样规定的
- 如果一个文件计算出一个哈希值,则和这个哈希值一样的那个 DHT node,就有责任知道从哪里下载这个文件,即便它自己没保存这个文件。
- 除了一模一样的那个 DHT node 应该知道,ID 和这个哈希值非常接近的 N 个 DHT node 也应该知道。
- 举例
- 文件 1 通过哈希运算,得到匹配 ID 的 DHT node 为 node C,当然还会有其他的,这里没有画出来。所以,node C 有责任知道文件 1 的存放地址,虽然 node C 本身没有存放文件 1。
- 文件 2 通过哈希运算,得到匹配 ID 的 DHT node 为 node E,但是 node D 和 E 的 ID 值很近,所以 node D 也知道。当然,文件 2 本身没有必要一定在 node D 和 E 里,但是碰巧这里就在 E 那有一份。
DHT node 新节点上线
这里以 node new 上线,下载文件 1 来举例
- DHT 网络中,种子 .torrent 文件里面就不再是 tracker 的地址了,而是一个 list 的 node 的地址,所有这些 node 都是已经在 DHT 网络里面的。当然随着时间的推移,很可能有退出的,有下线的。node new 只要在种子里面找到一个 DHT node,就加入了网络。
这里我们假设,不会所有的都联系不上,总有一个能联系上。
- node new 会计算文件 1 的哈希值,并根据这个哈希值了解到,和这个哈希值匹配,或者很接近的 node 上知道如何下载这个文件,例如计算出来的哈希值就是 node C。
- node new 通过 DHT 网络,询问其他 DHT node,得到 node C,或与 C 相临近的 N 个 node 之一,他们都知道文件 1 的下载方式。
- node new 通过 node C 知道下载文件 1,要去 B、D、 F,于是 node new 选择和 node B 进行 peer 连接,开始下载,它一旦开始下载,自己本地也有文件 1 了,于是 node new 告诉 node C 以及和 node C 的 ID 很像的那些节点,我也有文件 1 了,可以加入那个文件拥有者列表了。
DHT 网络的节点关系是怎么规定的?
DHT 网络按距离分层
- 距离的计算方法
- 假设某个节点的 ID 为 01010,如果一个节点的 ID,前面所有位数都与它相同,只有最后 1 位不同。这样的节点只有 1 个,为 01011。与基础节点的异或值为 00001,即距离为 1;对于 01010 而言,这样的节点归为“k-bucket 1”。
- 如果一个节点的 ID,前面所有位数都相同,从倒数第 2 位开始不同,这样的节点只有 2 个,即 01000 和 01001,与基础节点的异或值为 00010 和 00011,即距离范围为 2 和 3;对于 01010 而言,这样的节点归为“k-bucket 2”。
- 如果一个节点的 ID,前面所有位数相同,从倒数第 i 位开始不同,这样的节点只有 2^(i-1) 个,与基础节点的距离范围为 [2^(i-1), 2^i);对于 01010 而言,这样的节点归为“k-bucket i”。
- 分层的规则: 每一层都只放 K 个,这是参数可以配置。
DHT 网络是如何查找节点的?
- 以 A 查找 B 举例
- 假设,node A 的 ID 为 00110,要找 node B ID 为 10000,异或距离为 10110,距离范围在 [2^4, 2^5),所以这个目标节点可能在“k-bucket 5”中,这就说明 B 的 ID 与 A 的 ID 从第 5 位开始不同,所以 B 可能在“k-bucket 5”中。
- 然后,A 看看自己的 k-bucket 5 有没有 B。如果有,太好了,找到你了;如果没有,在 k-bucket 5 里随便找一个 C。因为是二进制,C、B 都和 A 的第 5 位不同,那么 C 的 ID 第 5 位肯定与 B 相同,即它与 B 的距离会小于 2^4,相当于比 A、B 之间的距离缩短了一半以上。
- 再请求 C,在它自己的通讯录里,按同样的查找方式找一下 B。如果 C 知道 B,就告诉 A;如果 C 也不知道 B,那 C 按同样的搜索方法,可以在自己的通讯录里找到一个离 B 更近的 D 朋友(D、B 之间距离小于 2^3),把 D 推荐给 A,A 请求 D 进行下一步查找。
- Kademlia 的这种查询机制,是通过折半查找的方式来收缩范围,对于总的节点数目为 N,最多只需要查询 log2(N) 次,就能够找到。
DHT 网络中,节点之间如何沟通?
Kademlia 算法中,每个节点只有 4 个指令
- PING:测试一个节点是否在线,还活着没,相当于打个电话,看还能打通不。
- STORE:要求一个节点存储一份数据,既然加入了组织,有义务保存一份数据。
- FIND_NODE:根据节点 ID 查找一个节点,就是给一个 160 位的 ID,通过上面朋友圈的方式找到那个节点。
- FIND_VALUE:根据 KEY 查找一个数据,实则上跟 FIND_NODE 非常类似。KEY 就是文件对应的 160 位的 ID,就是要找到保存了文件的节点。
DHT 网络中,节点关系如何更新?
- 每个 bucket 里的节点,都按最后一次接触的时间倒序排列
- 每次执行四个指令中的任意一个都会触发更新。
- 举例: 当一个节点与自己接触时
- 检查它是否已经在 k-bucket 中
- 如果在,那么将它挪到 k-bucket 列表的最底,也就是最新的位置
- 如果不在,且节点列表没有满,则添加到 k-bucket 最底层
- 如果不在,且节点列表已满,PING 一下列表最上面,也即最旧的一个节点。如果 PING 通了,将旧节点挪到列表最底,并丢弃新节点;如果 PING 不通,删除旧节点,并将新节点加入列表。
- 检查它是否已经在 k-bucket 中
第18讲 | DNS协议:网络世界的地址簿
DNS 服务器
- 你肯定记得住网站的名称,但是很难记住网站的 IP 地址,因而也需要一个地址簿,就是DNS 服务器。
- 由此可见,每个人上网,都需要访问 DNS 服务器,因而 DNS 服务器一定要设置成高可用、高并发和分布式的。
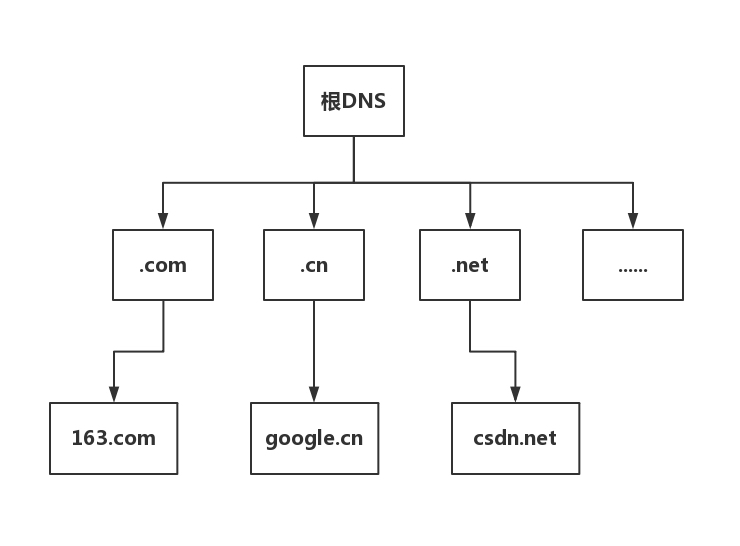
- 根 DNS 服务器 :返回顶级域 DNS 服务器的 IP 地址
- 顶级域 DNS 服务器:返回权威 DNS 服务器的 IP 地址
- 权威 DNS 服务器 :返回相应主机的 IP 地址
DNS 解析流程
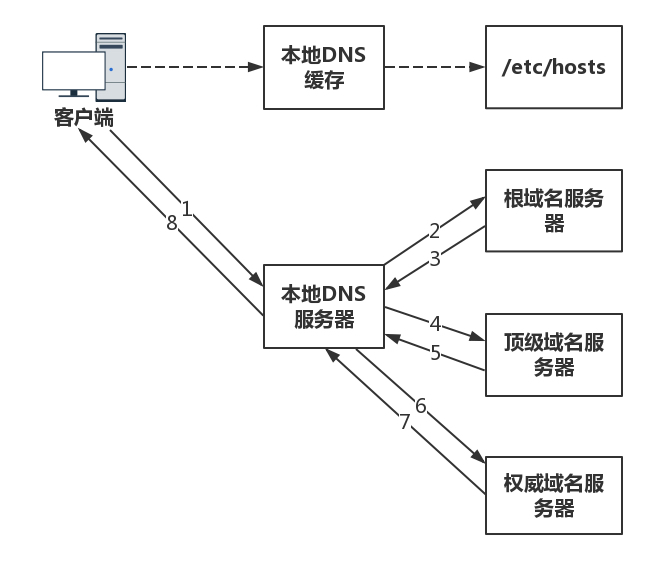
为了提高 DNS 的解析性能,很多网络都会就近部署 DNS 缓存服务器。这里以访问 www.baidu.com 来举例:
- 电脑客户端会发出一个 DNS 请求,问 www.baidu.com 的 IP 是什么,并发给本地域名服务器 (本地 DNS)。
如果是通过 DHCP 配置,本地 DNS 由你的网络服务商(ISP),如电信、移动等自动分配,它通常就在你网络服务商的某个机房。
也可以手动配置本地域名服务器,比如常见的 Google 的 8.8.8.8, 8.8.4.4
- 本地 DNS 收到来自客户端的请求。如果能在 DNS 表中找到 www.baidu.com,它直接就返回 IP 地址。如果没有,本地 DNS 会去问它的根域名服务器
根域名服务器是最高层次的,全球共有 13 套。它不直接用于域名解析,但能指明一条道路。
- 根 DNS 收到来自本地 DNS 的请求,发现后缀是 .com,并返回顶级域名服务器 .com 的地址
- 本地 DNS 再将请求发向顶级域名服务器,顶级域名服务器返回 www.baidu.com 区域的权威 DNS 服务器的地址
权威服务器就是保存域名及其对应 ip 的服务器,一般来说,权威 DNS 服务器可能是大公司自己组建的,专门提供自家域名解析。也可能是 DNS 解析服务提供商,如阿里云。
- 本地 DNS 转向请求权威 DNS 服务器,并最终得到 www.baidu.com 对应的 ip 地址
- 本地 DNS 再将 IP 地址返回客户端,客户端和目标建立连接
负载均衡
- 内部负载均衡: 在域名解析的时候,我们只要配置策略,这次返回第一个 IP,下次返回第二个 IP,就可以实现负载均衡了。
- 全局负载均衡: 我们肯定希望北京的用户访问北京的数据中心,上海的用户访问上海的数据中心,这样,客户体验就会非常好,访问速度就会超快。这就是全局负载均衡的概念。
- 高可用: 为了保证我们的应用高可用,往往会部署在多个机房,每个地方都会有自己的 IP 地址。当用户访问某个域名的时候,这个 IP 地址可以轮询访问多个数据中心。如果一个数据中心因为某种原因挂了,只要在 DNS 服务器里面,将这个数据中心对应的 IP 地址删除,就可以实现一定的高可用。
示例:DNS 访问数据中心中对象存储上的静态资源
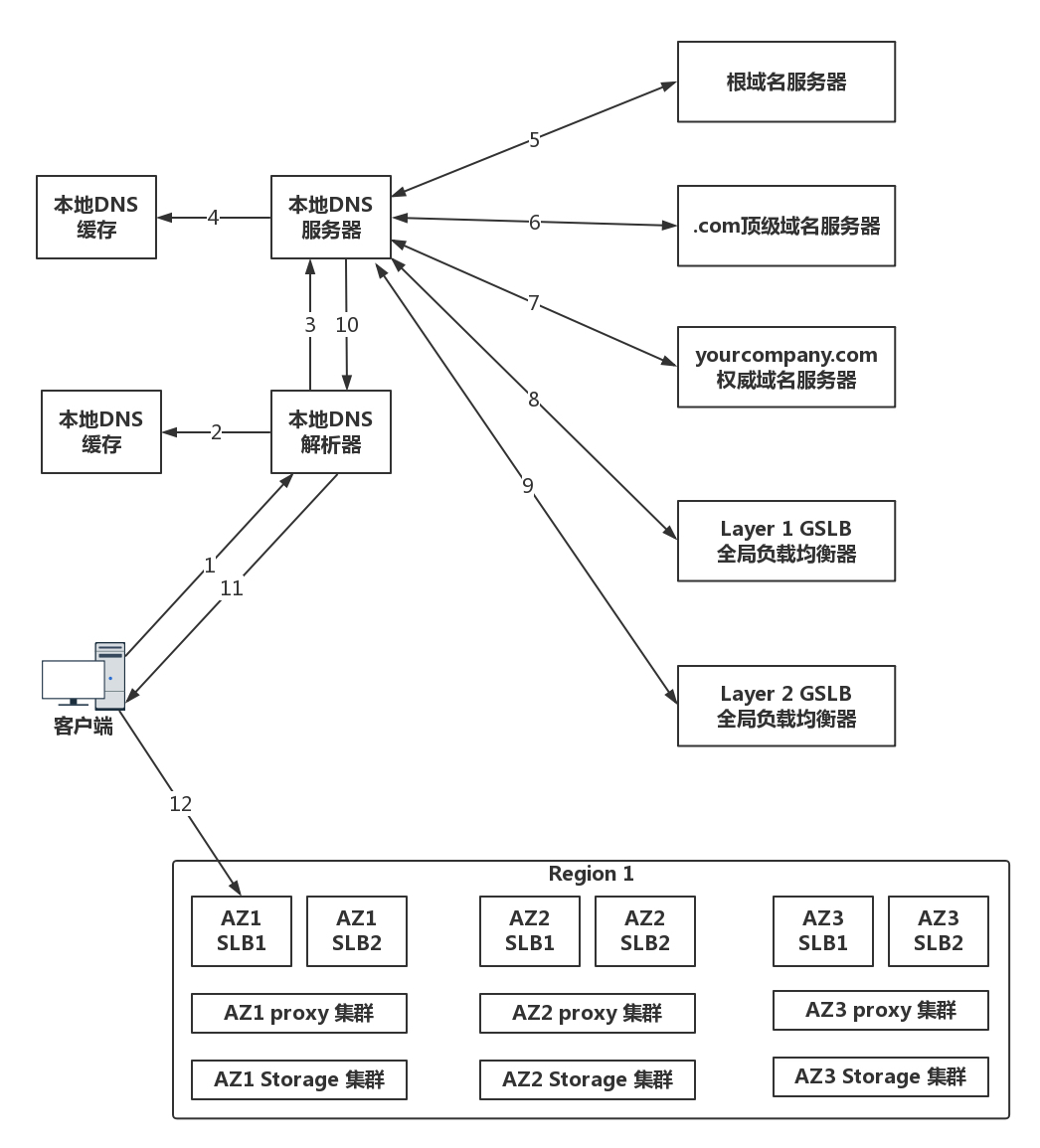
- 当一个客户端要访问 object.yourcompany.com 的时候,需要请求本地 DNS 解析器
- 本地 DNS 解析器先查看看本地的缓存是否有这个记录。如果有则直接使用
- 缓存中没有则请求本地的 DNS 服务器
- 本地的 DNS 服务器一般部署在你的数据中心或者你所在的运营商的网络中,本地 DNS 服务器也需要看本地是否有缓存,如果有则返回。
- 本地没有则请求根 DNS 服务器,得到顶级 DNS 服务器地址
- 请求顶级 DNS 服务器,得到权威 DNS 服务器地址
- 请求权威 DNS 服务器,获取 ip
- 是否需要全局负载均衡的区别
- 对于不需要做全局负载均衡的简单应用来讲,yourcompany.com 的权威 DNS 服务器可以直接将 object.yourcompany.com 这个域名解析为一个或者多个 IP 地址,然后客户端可以通过多个 IP 地址,进行简单的轮询,实现简单的负载均衡。
- 对于需要更加复杂的全局负载均衡机制的应用,需要专门的设备或者服务器来做这件事情,这就是全局负载均衡器(GSLB,Global Server Load Balance)。
在 yourcompany.com 的 DNS 服务器中,一般是通过配置 CNAME 的方式,给 object.yourcompany.com 起一个别名,例如 object.vip.yourcomany.com,然后告诉本地 DNS 服务器,让它请求 GSLB 解析这个域名,GSLB 就可以在解析这个域名的过程中,通过自己的策略实现负载均衡。
- 第一层 GSLB,通过查看请求它的本地 DNS 服务器所在的运营商,就知道用户所在的运营商。假设是移动,通过 CNAME 的方式,通过另一个别名 object.yd.yourcompany.com,告诉本地 DNS 服务器去请求第二层的 GSLB。
- 第二层 GSLB,通过查看请求它的本地 DNS 服务器所在的地址,就知道用户所在的地理位置,然后将距离用户位置比较近的 Region 里面,六个内部负载均衡(SLB,Server Load Balancer)的地址,返回给本地 DNS 服务器。
- 本地 DNS 服务器将结果返回给本地 DNS 解析器。
- 本地 DNS 解析器将结果缓存后,返回给客户端。
- 客户端开始访问属于相同运营商的距离较近的 Region 1 中的对象存储,当然客户端得到了六个 IP 地址,它可以通过负载均衡的方式,随机或者轮询选择一个可用区进行访问。
对象存储一般会有三个备份,从而可以实现对存储读写的负载均衡。
第19讲 | HTTPDNS:网络世界的地址簿也会指错路
传统 DNS 存在哪些问题?
- 域名缓存问题
- 可能域名对应 ip 已经更换,但是本地缓存还是解析到了之前的 ip,这就导致访问了一个失效/错误的 ip
- 有的运营商会把一些静态页面,缓存到本运营商的服务器内,这样用户请求的时候,就不用跨运营商进行访问,这样既加快了速度,也减少了运营商之间流量计算的成本。在域名解析的时候,不会将用户导向真正的网站,而是指向这个缓存的服务器。但当页面更新时,缓存服务器的更新没有那么快。这就导致访问更新内容的不及时
- 本地的缓存,往往使得全局负载均衡失败,因为上次进行缓存的时候,缓存中的地址不一定是这次访问离客户最近的地方,如果把这个地址返回给客户,那肯定就会绕远路。
- 域名转发问题
- 可能一些 DNS 运营商将域名直接转发到其他 DNS 运营商以提供解析,比如 A 运营商转发到 B 运营商解析,权威服务器会认为你是 B 运营商的,返回给你一个在 B 运营商处建立的网站 ip 地址,这样每次访问就需要跨运营商,速度很慢。
- 出口 NAT 问题
- 很多机房都会配置NAT,也即网络地址转换,使得从这个网关出去的包,都换成新的 IP 地址。一旦做了网络地址的转换,权威的 DNS 服务器,就没办法通过这个地址,来判断客户到底是来自哪个运营商,而且极有可能因为转换过后的地址,误判运营商,导致跨运营商的访问。
- 域名更新问题
- 本地 DNS 服务器是由不同地区、不同运营商独立部署的。对域名解析缓存的处理上,实现策略也有区别,有的会偷懒,忽略域名解析结果的 TTL 时间限制,在权威 DNS 服务器解析变更的时候,解析结果在全网生效的周期非常漫长。但是有的时候,在 DNS 的切换中,场景对生效时间要求比较高。
例如双机房部署的时候,跨机房的负载均衡和容灾多使用 DNS 来做。当一个机房出问题之后,需要修改权威 DNS,将域名指向新的 IP 地址,但是如果更新太慢,那很多用户都会出现访问异常。
- 本地 DNS 服务器是由不同地区、不同运营商独立部署的。对域名解析缓存的处理上,实现策略也有区别,有的会偷懒,忽略域名解析结果的 TTL 时间限制,在权威 DNS 服务器解析变更的时候,解析结果在全网生效的周期非常漫长。但是有的时候,在 DNS 的切换中,场景对生效时间要求比较高。
- 解析延迟问题
- 从上一节的 DNS 查询过程来看,DNS 的查询过程需要递归遍历多个 DNS 服务器,才能获得最终的解析结果,这会带来一定的时延,甚至会解析超时。
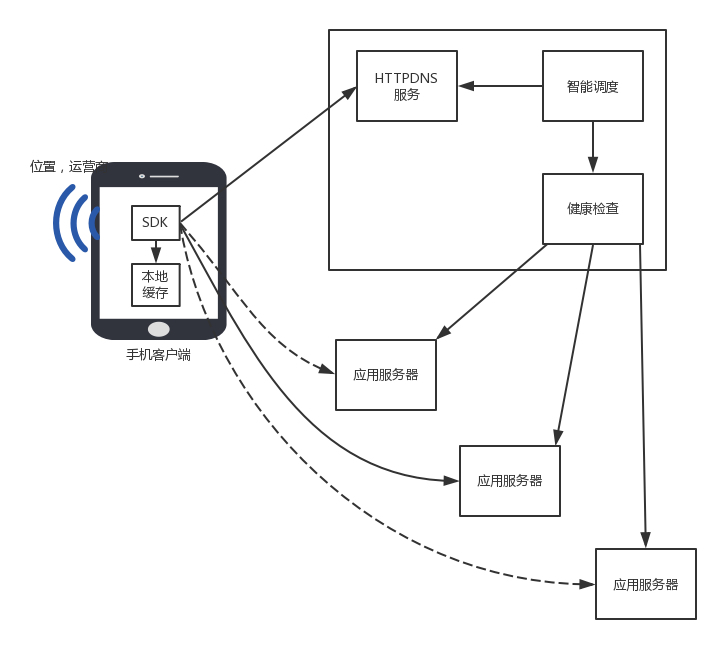
HTTPDNS 的工作模式
HTTPNDS: 不走传统的 DNS 解析,而是自己搭建基于 HTTP 协议的 DNS 服务器集群,分布在多个地点和多个运营商。当客户端需要 DNS 解析的时候,直接通过 HTTP 协议进行请求这个服务器集群,得到就近的地址。
使用 HTTPDNS 需要绕过默认的 DNS 路径,就不能使用默认的客户端。使用 HTTPDNS 的,往往是手机应用,需要在手机端嵌入支持 HTTPDNS 的客户端 SDK。
- 在客户端的 SDK 里动态请求服务端,获取 HTTPDNS 服务器的 IP 列表,缓存到本地。随着不断地解析域名,SDK 也会在本地缓存 DNS 域名解析的结果。
- 当手机应用要访问一个地址的时候,首先看是否有本地的缓存,如果有就直接返回。这个缓存和本地 DNS 的缓存不一样的是,这个是手机应用自己做的,而非整个运营商统一做的。如何更新、何时更新,手机应用的客户端可以和服务器协调来做这件事情。
- 如果本地没有,就需要请求 HTTPDNS 的服务器,在本地 HTTPDNS 服务器的 IP 列表中,选择一个发出 HTTP 的请求,会返回一个要访问的网站的 IP 列表。
- 请求的方式是这样的。
1
2curl http://106.2.xxx.xxx/d?dn=c.m.163.com
{"dns":[{"host":"c.m.163.com","ips":["223.252.199.12"],"ttl":300,"http2":0}],"client":{"ip":"106.2.81.50","line":269692944}}
- 请求的方式是这样的。
- 手机客户端自然知道手机在哪个运营商、哪个地址。由于是直接的 HTTP 通信,HTTPDNS 服务器能够准确知道这些信息,因而可以做精准的全局负载均衡。
HTTPDNS 的缓存设计
HTTPDNS 缓存设计策略分三层,即手机客户端、DNS 缓存、HTTPDNS 服务器。
- 概述
- SDK 中的缓存会严格按照缓存过期时间,如果缓存没有命中,或者已经过期,而且客户端不允许使用过期的记录,则会发起一次解析,保障记录是更新的。
- 缓存更新
- 同步更新
- 优点是实时性好
- 缺点是如果有多个请求都发现过期的时候,同时会请求 HTTPDNS 多次,其实是一种浪费。
- 异步更新
- 优点是,可以将多个请求都发现过期的情况,合并为一个对于 HTTPDNS 的请求任务,只执行一次,减少 HTTPDNS 的压力。同时可以在即将过期的时候,就创建一个任务进行预加载,防止过期之后再刷新,称为预加载。
- 缺点是当前请求拿到过期数据的时候,如果客户端允许使用过期数据,需要冒一次风险。如果过期的数据还能请求,就没问题;如果不能请求,则失败一次,等下次缓存更新后,再请求方能成功。
- 同步更新
HTTPDNS 的调度设计
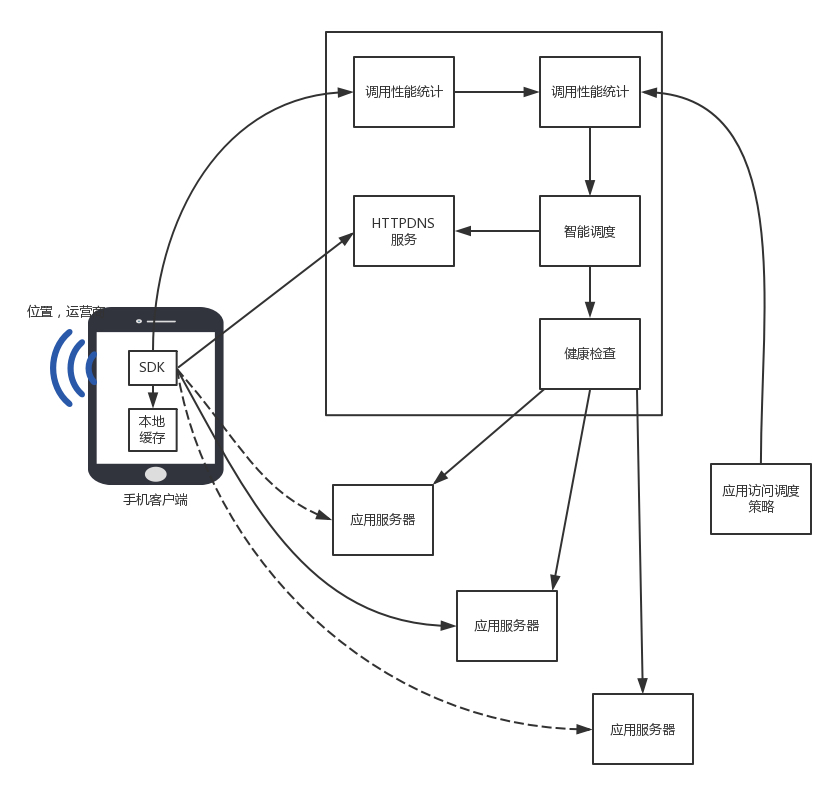
客户端
- 可以知道手机是哪个国家、哪个运营商、哪个省,甚至哪个市,HTTPDNS 服务端可以根据这些信息,选择最佳的服务节点返回。
- 如果有多个节点,还会考虑错误率、请求时间、服务器压力、网络状况等,进行综合选择,而非仅仅考虑地理位置。当有一个节点宕机或者性能下降的时候,可以尽快进行切换。
- 客户端的 SDK 会收集网络请求数据,如错误率、请求时间等网络请求质量数据,并发送到统计后台,进行分析、聚合,以此查看不同的 IP 的服务质量。
服务端
- 应用可以通过调用 HTTPDNS 的管理接口,配置不同服务质量的优先级、权重。HTTPDNS 会根据这些策略综合地理位置和线路状况算出一个排序,优先访问当前那些优质的、时延低的 IP 地址。
HTTPDNS 通过智能调度之后返回的结果,也会缓存在客户端。为了不让缓存使得调度失真,客户端可以根据不同的移动网络运营商 WIFI 的 SSID 来分维度缓存。不同的运营商或者 WIFI 解析出来的结果会不同。
第20讲 | CDN:你去小卖部取过快递么?
CDN 的分发系统的架构
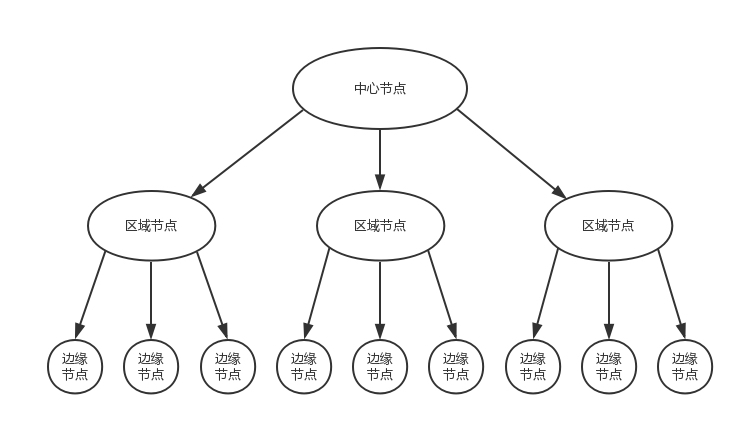
由于边缘节点数目比较多,但是每个集群规模比较小,不可能缓存下来所有东西,因而可能无法命中,这样就会在边缘节点之上。有区域节点,规模就要更大,缓存的数据会更多,命中的概率也就更大。在区域节点之上是中心节点,规模更大,缓存数据更多。如果还不命中,就只好回源网站访问了。
客户端如何找到相应的边缘节点进行访问呢?
以 baidu.com 举例
- baidu.com 这个权威 DNS 服务器上,会设置一个 CNAME 别名,指向另外一个域名 baidu.cdn.com,返回给本地 DNS 服务器。
- 当本地 DNS 服务器拿到这个新的域名时,需要继续解析这个新的域名。这个时候,访问的是 baidu.cdn.com 的权威 DNS 服务器,这是 CDN 自己的权威 DNS 服务器。在这个服务器上,还是会设置一个 CNAME,指向另外一个域名,也即 CDN 网络的全局负载均衡器。
- 本地 DNS 服务器去请求 CDN 的全局负载均衡器解析域名,全局负载均衡器会为用户选择一台合适的缓存服务器提供服务(返回边缘节点的 ip),选择的依据包括:
- 根据用户 IP 地址,判断哪一台服务器距用户最近
- 用户所处的运营商
- 根据用户所请求的 URL 中携带的内容名称,判断哪一台服务器上有用户所需的内容
- 查询各个服务器当前的负载情况,判断哪一台服务器尚有服务能力
- 本地 DNS 服务器缓存这个 IP 地址,然后将 IP 返回给客户端,客户端去访问这个边缘节点,下载资源。
- 如果这台缓存服务器上并没有用户想要的内容,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器将内容拉到本地。
CDN 可以进行缓存的内容
- 静态资源
- 对于静态页面来讲,内容的分发往往采取拉取的方式,也即当发现未命中的时候,再去上一级进行拉取。
- 流媒体
- CDN 支持流媒体协议,例如前面讲过的 RTMP 协议。
- 流媒体数据量大,如果出现回源,压力会比较大,所以往往采取主动推送的模式,将热点数据主动推送到边缘节点。
- 对于流媒体来讲,很多 CDN 还提供预处理服务,也即文件在分发之前,经过一定的处理。例如将视频转换为不同的码流,参考我们常见的 “标清,高清,超清”
CDN 防盗链
- HTTP 头的 refer 字段, 当浏览器发送请求的时候,一般会带上 referer,告诉服务器是从哪个页面链接过来的,服务器基于此可以获得一些信息用于处理。如果 refer 信息不是来自本站,就阻止访问或者跳到其它链接。
- 时间戳防盗链: 使用 CDN 的管理员可以在配置界面上,和 CDN 厂商约定一个加密字符串。
- 客户端取出当前的时间戳,要访问的资源及其路径,连同加密字符串进行签名算法得到一个字符串,然后生成一个下载链接,带上这个签名字符串和截止时间戳去访问 CDN。
- 服务端,根据取出过期时间,和当前 CDN 节点时间进行比较,确认请求是否过期。然后 CDN 服务端有了资源及路径,时间戳,以及约定的加密字符串,根据相同的签名算法计算签名,如果匹配则一致,访问合法,才会将资源返回给客户。
动态 CDN
- 边缘计算的模式。数据的逻辑计算和存储,相应的放在边缘的节点。其中定时从源数据那里同步存储的数据,然后在边缘进行计算得到结果。
- 路径优化的模式。数据不是在边缘计算生成的,而是在源站生成的,但是数据的下发则可以通过 CDN 的网络,对路径进行优化。因为 CDN 节点较多,能够找到离源站很近的边缘节点,也能找到离用户很近的边缘节点。中间的链路完全由 CDN 来规划,选择一个更加可靠的路径,使用类似专线的方式进行访问。
第21讲 | 数据中心:我是开发商,自己拿地盖别墅
概述
- 数据中心里面是服务器。服务器被放在一个个叫作机架(Rack)的架子上面。
- 数据中心的入口和出口也是路由器,由于在数据中心的边界,称为边界路由器(Border Router)。
- 为了高可用,边界路由器会有多个。
- 为了高可用,边界路由器会连接多个运营商网络。
- 数据中心里面的机器访问外网,或者提供给外网访问,都可以通过 BGP 协议,获取内外互通的路由信息。这就是多线 BGP的概念。
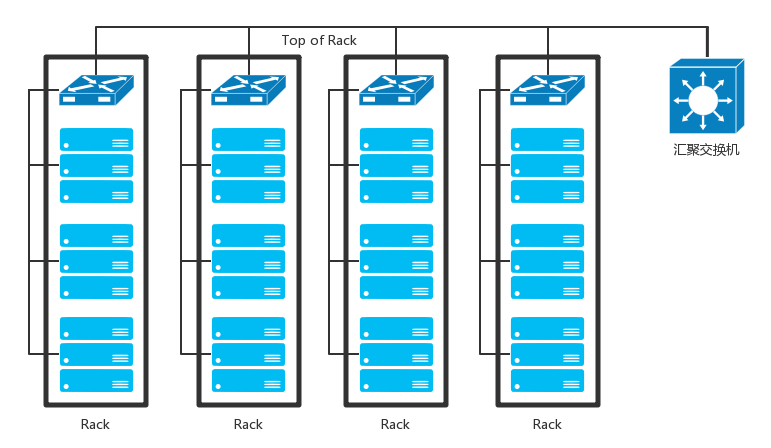
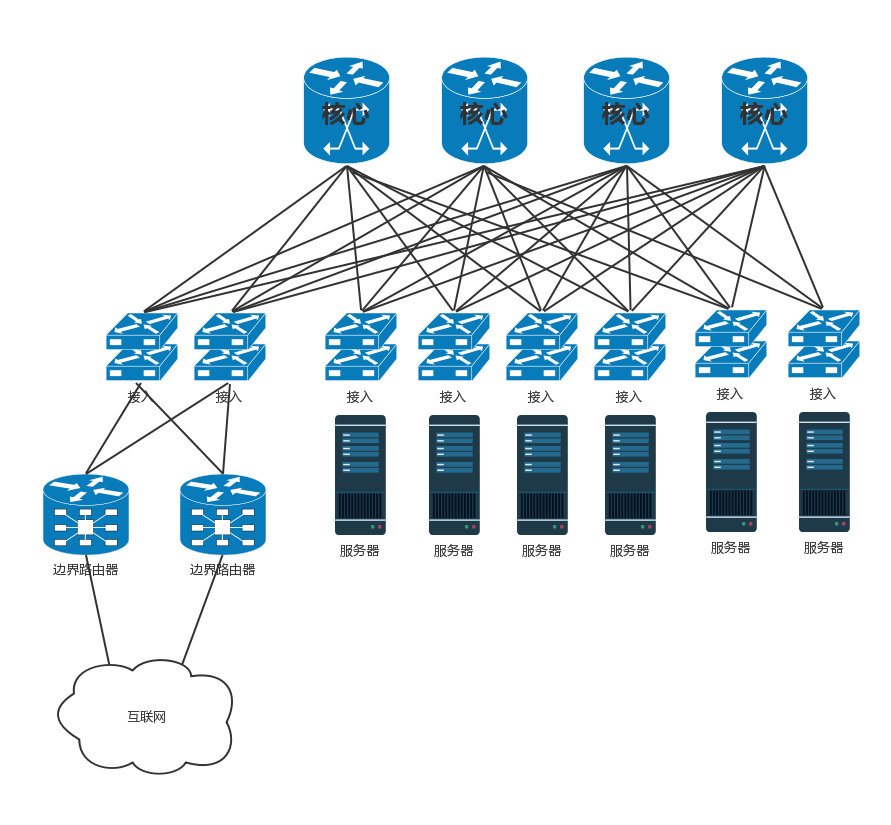
- 数据中心里面往往有非常多的机器,当塞满一机架的时候,需要有交换机将这些服务器连接起来,可以互相通信。这些交换机往往是放在机架顶端的,所以经常称为TOR(Top Of Rack)交换机。这一层的交换机常常称为接入层(Access Layer)。
- 当一个机架放不下的时候,就需要多个机架,还需要有交换机将多个机架连接在一起。这些交换机对性能的要求更高,带宽也更大。这些交换机称为汇聚层交换机(Aggregation Layer)。
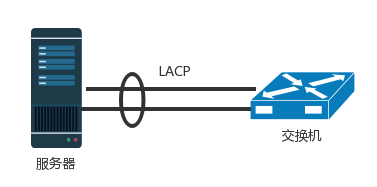
- 单台机器的高可用: 一台机器至少要有两个网卡、两个网线插到 TOR 交换机上,但是两个网卡要工作得像一张网卡一样,这就是网卡绑定(bond)。
- 这需要服务器和交换机都支持一种协议LACP(Link Aggregation Control Protocol)。它们互相通信,将多个网卡聚合称为一个网卡,多个网线聚合成一个网线,在网线之间可以进行负载均衡。
- 这需要服务器和交换机都支持一种协议LACP(Link Aggregation Control Protocol)。它们互相通信,将多个网卡聚合称为一个网卡,多个网线聚合成一个网线,在网线之间可以进行负载均衡。
- 机架的高可用: 部署多个 TOR、多个汇聚交换机。服务器和多个接入交换机都连接,TOR 和多个汇聚都连接
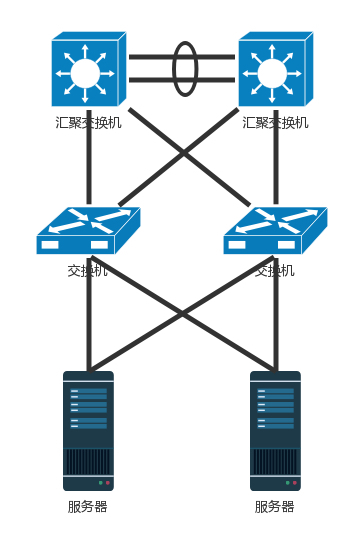
但这样需要解决交换机环路问题- 方法一: STP 协议,但是这样只有一条线路起作用
- 方法二: 堆叠技术,将多个交换机形成一个逻辑的交换机,服务器通过多根线分配连到多个接入层交换机上,而接入层交换机多根线分别连接到多个交换机上,并且通过堆叠的私有协议,形成双活的连接方式。
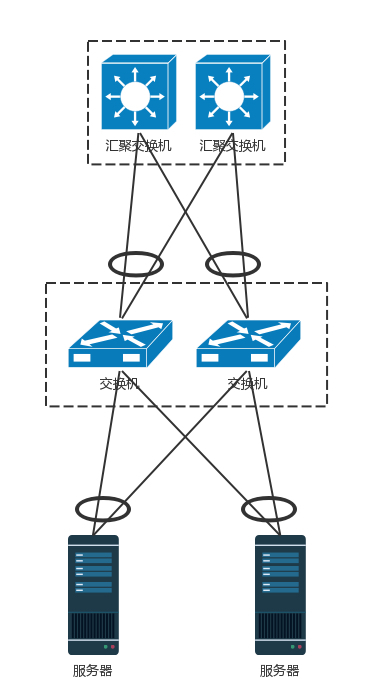
- 汇聚层将大量的计算节点相互连接在一起,形成一个集群。在这个集群里面,服务器之间通过二层互通,这个区域常称为一个POD(Point Of Delivery),有时候也称为一个可用区(Available Zone)。
- 当节点数目再多的时候,一个可用区放不下,需要将多个可用区连在一起,连接多个可用区的交换机称为核心交换机。
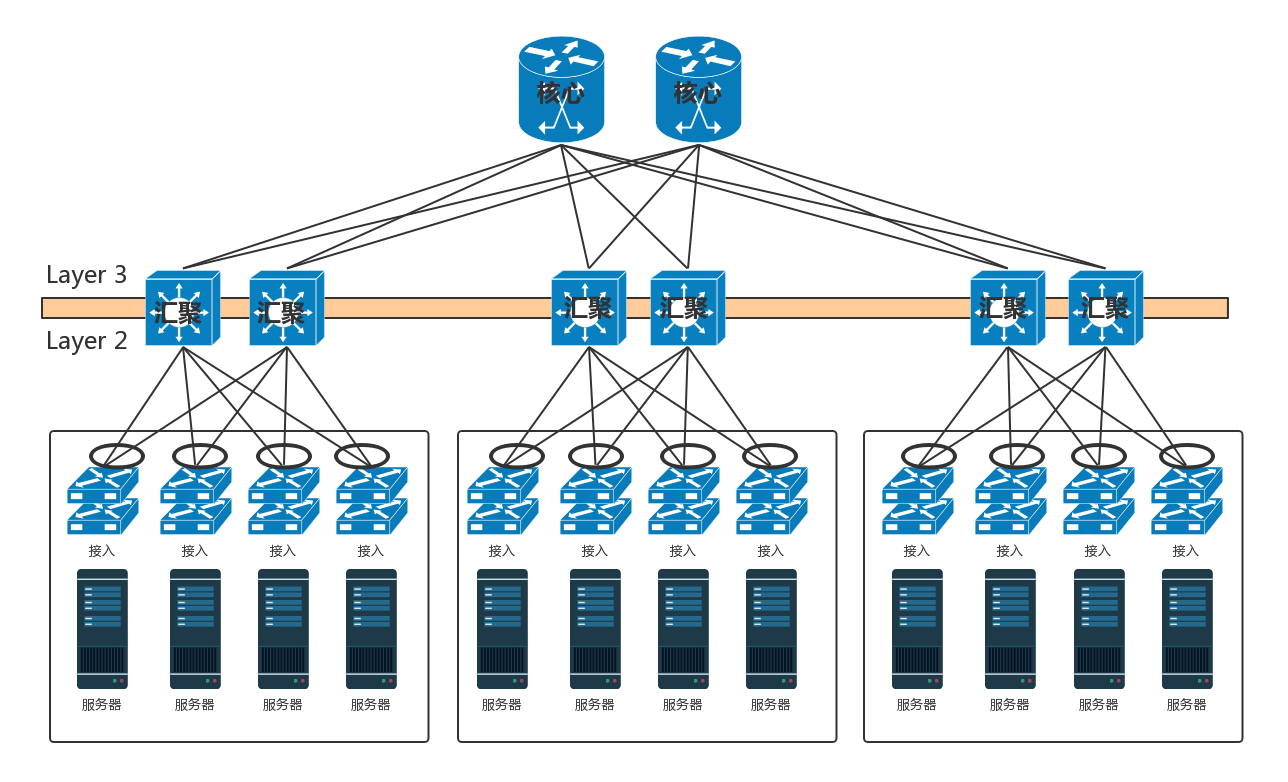
- 核心交换机的高可用: 堆叠不足以满足核心交换机的吞吐量,因而还是需要部署多组核心交换机。核心和汇聚交换机之间为了高可用,也是全互连模式的,因此还需要解决环路问题。
- 方法一: 不同的可用区在不同的二层网络,需要分配不同的网段。汇聚和核心之间通过三层网络互通的,二层都不在一个广播域里面,不会存在二层环路的问题。三层有环是没有问题的,核心层和汇聚层之间通过内部的路由协议 OSPF,找到最佳的路径进行访问。
但当有了云计算、大数据,集群规模非常大,而且都要求在一个二层网络里面,就需要使用方法二了。
- 方法二: 二层互连从汇聚层上升为核心层,也即在核心以下,全部是二层互连,全部在一个广播域里面,这就是常说的大二层。
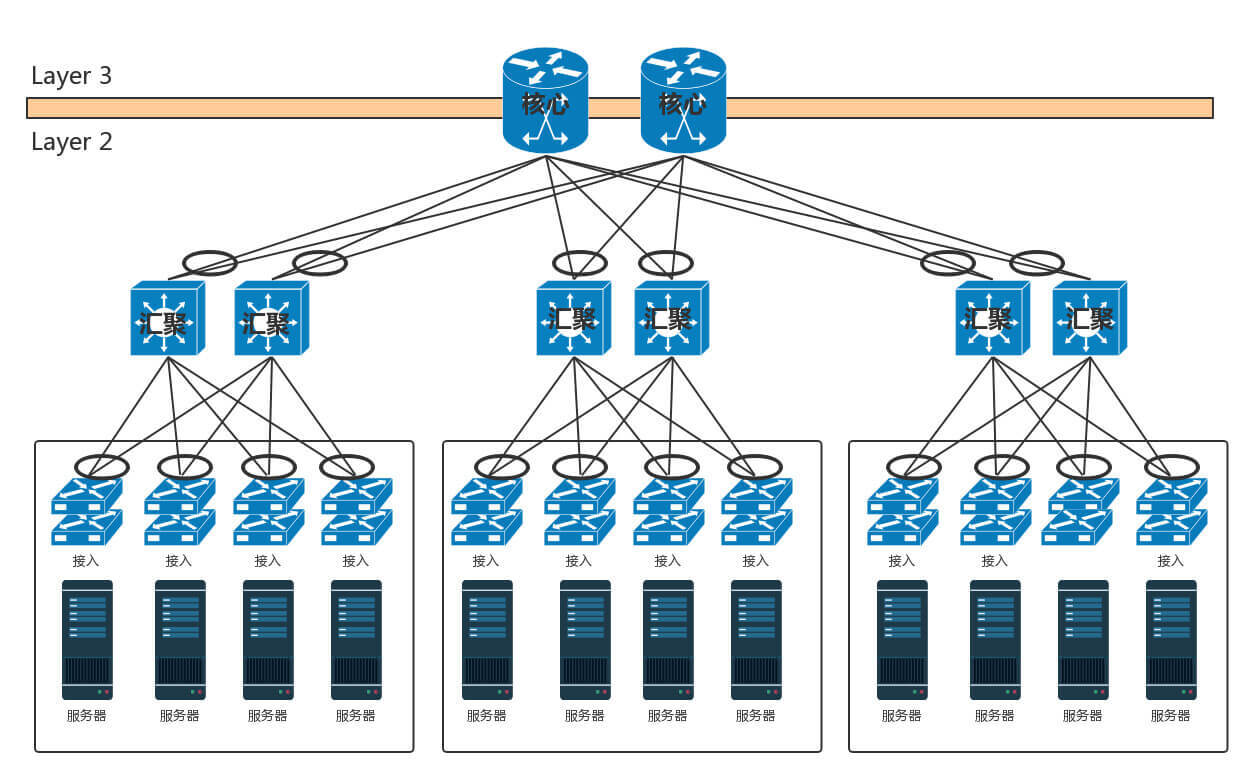
- 这里引入 TRILL(Transparent Interconnection of Lots of Link),即多链接透明互联协议解决问题。它的基本思想是,二层环有问题,三层环没有问题,那就把三层的路由能力模拟在二层实现。
- 运行 TRILL 协议的交换机称为RBridge,是具有路由转发特性的网桥设备,只不过这个路由是根据 MAC 地址来的,不是根据 IP 来的。Rbridage 之间通过链路状态协议运作。
- TRILL 协议在原来的 MAC 头外面加上自己的头,以及外层的 MAC 头。TRILL 头里面的 Ingress RBridge,有点像 IP 头里面的源 IP 地址,Egress RBridge 是目标 IP 地址,这两个地址是端到端的,在中间路由的时候,不会发生改变。而外层的 MAC,可以有下一跳的 Bridge,就像路由的下一跳,也是通过 MAC 地址来呈现的一样。
这个过程和 IP 路由很像
- 方法一: 不同的可用区在不同的二层网络,需要分配不同的网段。汇聚和核心之间通过三层网络互通的,二层都不在一个广播域里面,不会存在二层环路的问题。三层有环是没有问题的,核心层和汇聚层之间通过内部的路由协议 OSPF,找到最佳的路径进行访问。
- 在核心交换机上面,往往会挂一些安全设备,例如入侵检测、DDoS 防护等等。这是整个数据中心的屏障,防止来自外来的攻击。核心交换机上往往还有负载均衡器。有的数据中心里面,对于存储设备,还会有一个存储网络,最终整个数据中心的网络如下图所示。
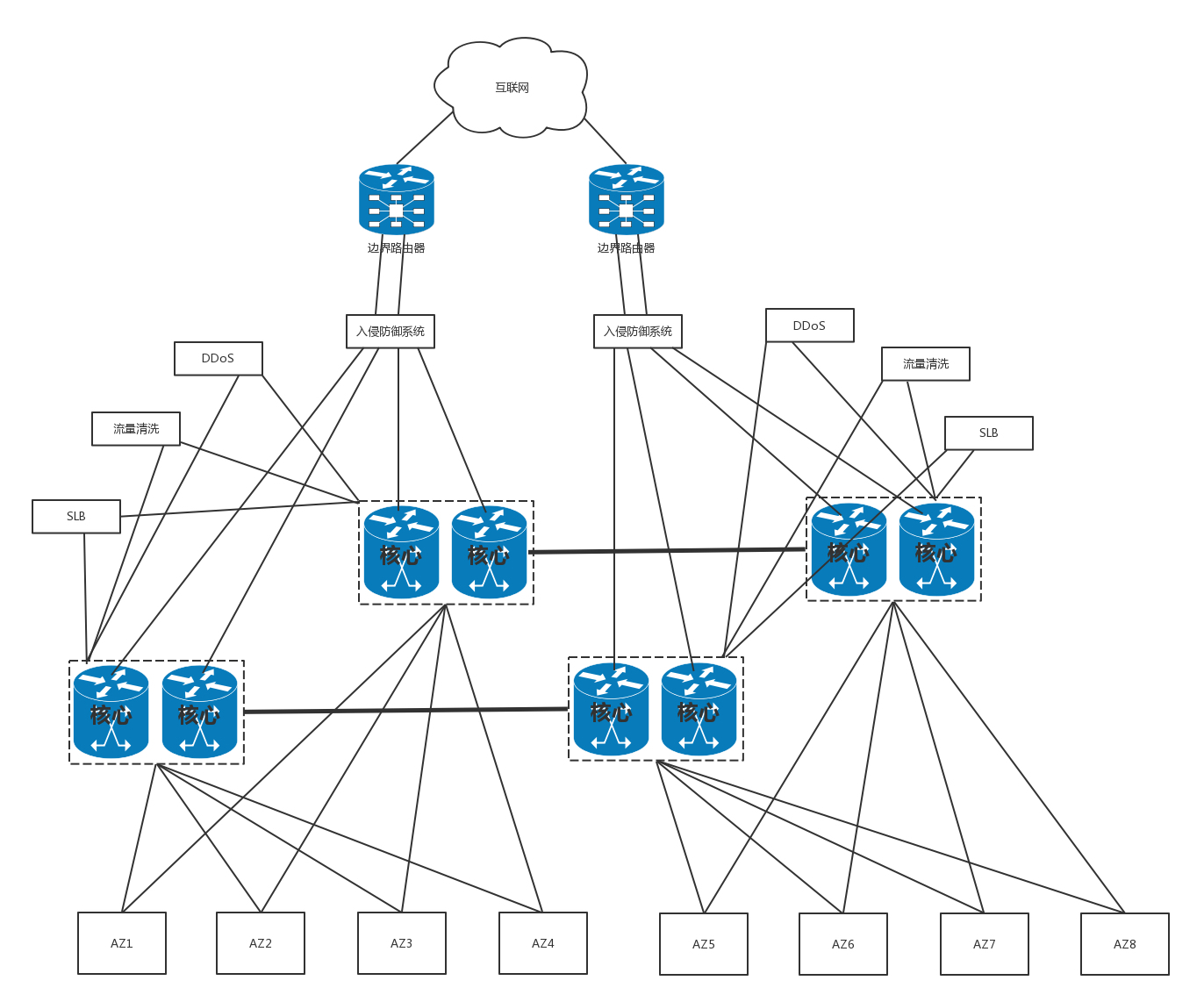
这是一个典型的三层网络结构,即接入层、汇聚层、核心层三层。 - 数据中心流量类型
- 南北流量: 这种模式非常有利于外部流量请求到内部应用。对应到上面那张图里,就是上下流通,所以称为南北流量。
- 东西流量: 大数据计算经常要在不同的节点将数据拷贝来拷贝去,这样需要经过交换机,使得数据从左右流通,所以称为东西流量。
- 叶脊网络(Spine/Leaf): 为了解决东西流量的问题而演进出的网络。传统的三层网络架构是垂直的结构,而叶脊网络架构是扁平的结构,更易于水平扩展。
- 叶子交换机(leaf),直接连接物理服务器。L2/L3 网络的分界点在叶子交换机上,叶子交换机之上是三层网络。
- 脊交换机(spine switch),相当于核心交换机。叶脊之间通过 ECMP 动态选择多条路径。脊交换机现在只是为叶子交换机提供一个弹性的 L3 路由网络。南北流量可以不用直接从脊交换机发出,而是通过与 leaf 交换机并行的交换机,再接到边界路由器出去。
第22讲 | VPN:朝中有人好做官
将多个多个数据中心连接起来的方法
- 走公网,但是公网太不安全,隐私可能会被别人偷窥
- 租用专线的方式把它们连起来,但需要花很多钱
- 用 VPN 来连接,这种方法比较折中,安全又不贵
VPN,全名Virtual Private Network,虚拟专用网,就是利用开放的公众网络,建立专用数据传输通道,将远程的分支机构、移动办公人员等连接起来。
VPN 是如何工作的?
VPN 通过隧道技术在公众网络上仿真一条点到点的专线,是通过利用一种协议来传输另外一种协议的技术,这里面涉及三种协议
- 乘客协议
- 隧道协议
- 承载协议
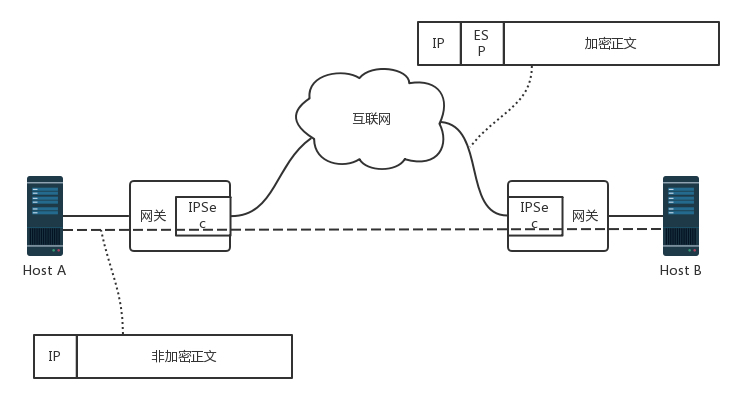
IPsec
IPsec 是基于 IP 协议的安全隧道协议,为了保证在公网上面信息的安全,因而采取了一定的机制保证安全性。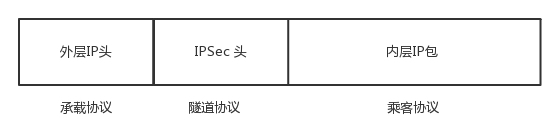
- 私密性,防止信息泄漏给未经授权的个人,通过加密把数据从明文变成无法读懂的密文,从而确保数据的私密性。
这里使用的是对称加密,其中秘钥的传输使用了 IKE 协议,即 Internet Key Exchange,因特网密钥交换协议。
- 完整性,数据没有被非法篡改,通过对数据进行 hash 运算,产生类似于指纹的数据摘要,以保证数据的完整性。
- 真实性,数据确实是由特定的对端发出,通过身份认证可以保证数据的真实性。
- 方法一: 通过预共享密钥来确保真实性
- 方法二: 用数字签名来验证。使用私钥进行签名,私钥只有我自己有,所以如果对方能用我的数字证书里面的公钥解开,就说明我是我
IPsec VPN 的协议簇
基于以上三个特性(私密性,完整性,真实性),组成了IPsec VPN 的协议簇。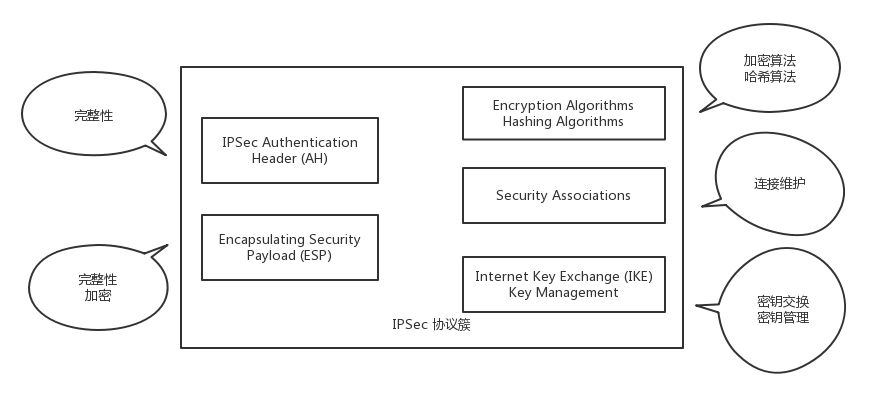
- 两种协议
- AH(Authentication Header),只能进行数据摘要,不能实现数据加密
- ESP(Encapsulating Security Payload),能够进行数据加密和数据摘要
- 两种算法
- 加密算法
- 摘要算法
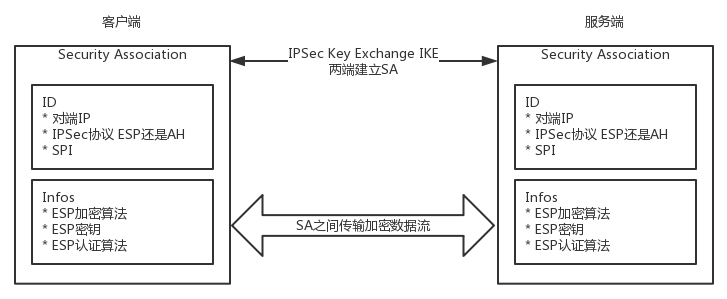
- 两大组件
- VPN 的双方要进行对称密钥的交换的 IKE 组件
- VPN 的双方要对连接进行维护的 SA(Security Association)组件
IPsec VPN 的建立过程
- 建立 IKE 自己的 SA。这个 SA 用来维护一个通过身份认证和安全保护的通道,为第二个阶段提供服务。在这个阶段,通过 DH(Diffie-Hellman)算法计算出一个对称密钥 K。
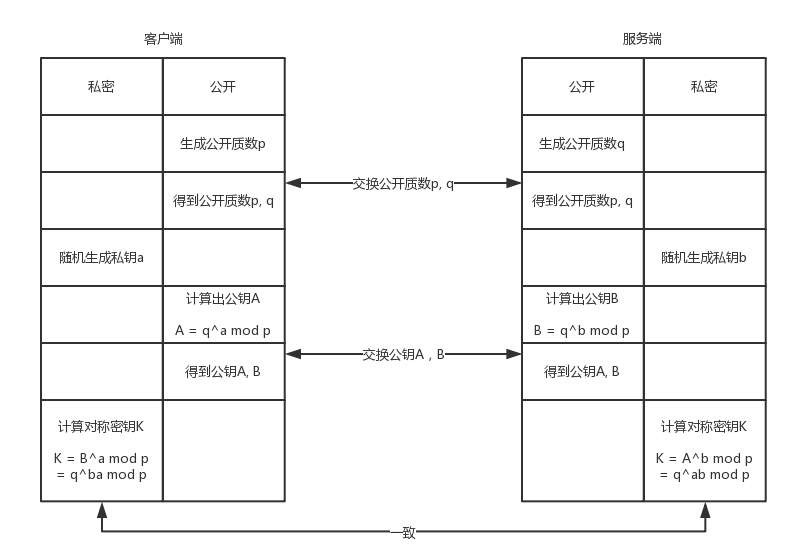
可以看出,这里巧妙的利用了一些数学原理,使得客户端,服务端双方都能计算出对称密钥 K,但中间拦截者因为没有 a,b 的数值,无法计算出 K。
- 建立 IPsec SA。在这个 SA 里面,双方会生成一个随机的对称密钥 M,由 K 加密传给对方,然后使用 M 进行双方接下来通信的数据。对称密钥 M 是有过期时间的,会过一段时间,重新生成一次,从而防止被破解。IPsec SA 中包含如下内容:
- SPI(Security Parameter Index),用于标识不同的连接
- 双方商量好的加密算法、哈希算法和封装模式
- 生存周期,超过这个周期,就需要重新生成一个 IPsec SA,重新生成对称密钥
- 打包封装传输
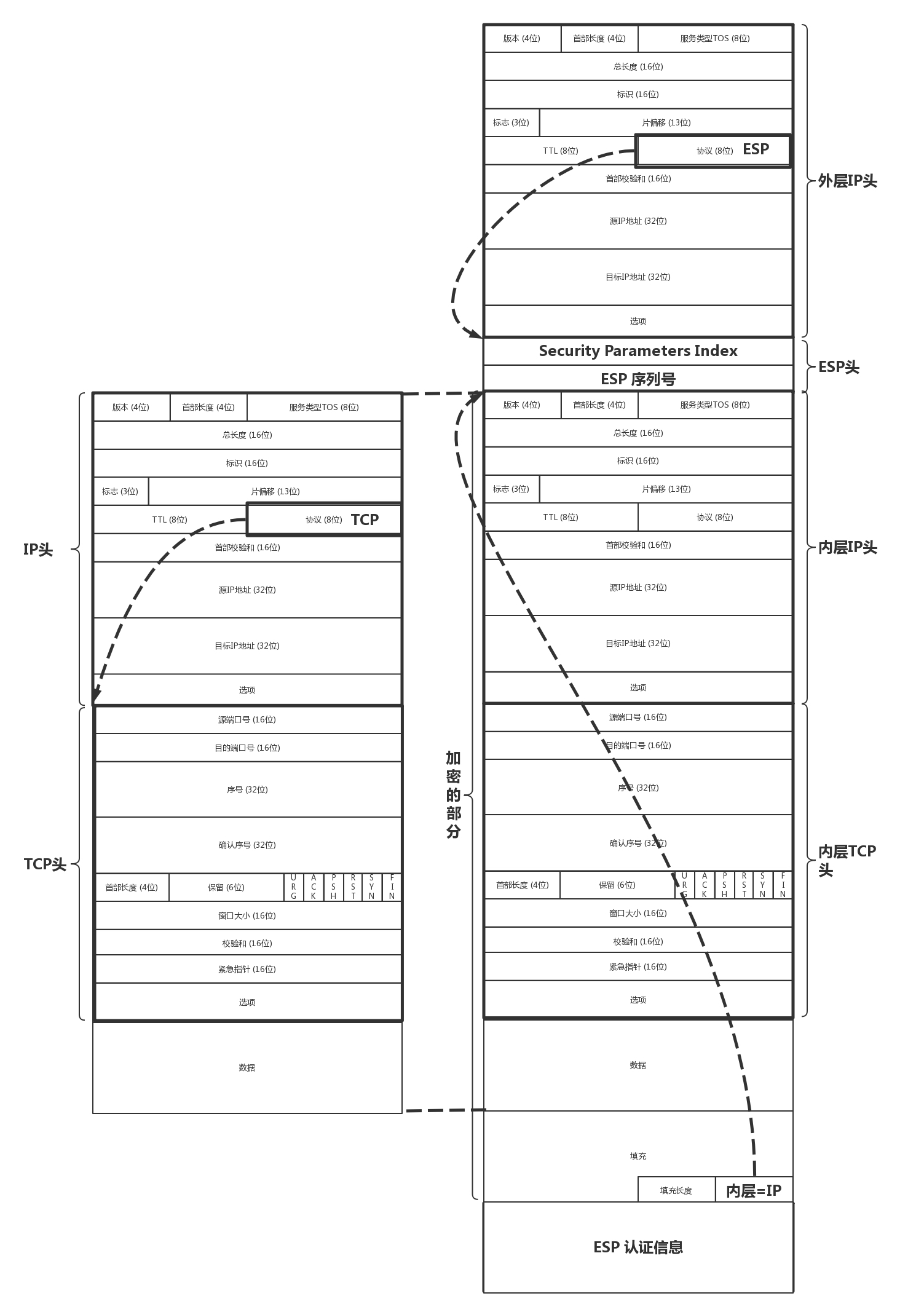
- ESP 要对 IP 包进行封装,因而 IP 头里面的上一层协议为 ESP。在 ESP 的正文里面,ESP 的头部有双方商讨好的 SPI,以及这次传输的序列号。
- 接下来全部是加密的内容。可以通过对称密钥进行解密,解密后在正文的最后,指明了里面的协议是什么。如果是 IP,则需要先解析 IP 头,然后解析 TCP 头,这是从隧道出来后解封装的过程。
ATM
ATM 是与 IP 同一层的协议,与 IP 不同的是,ATM 是面向连接的。
IP 与 ATM 的对比:
- IP
- IP 基于 TCP 来保证重试成功,TCP 虽然是面向连接的,但是与 IP 不处于同一层,IP 层还是不面向连接的。
- 优势: 包可以选择不同的道路,一条道路崩溃时,可以选择其他道路,保证到达
- 劣势: 不断的路由查找,效率比较差
- ATM
- ATM 在传输之前先建立一个连接,形成一个虚拟的通路,一旦连接建立了,所有的包都按照相同的路径走。
- 优势: 不许查找路由,虚拟路径已经建立,打上了标签,传输效率更高
- 劣势: 一旦道路断了,则连接直接崩溃,后续所有的包都无法达到
多协议标签交换(MPLS,Multi-Protocol Label Switching)
MPLS 结合了 IP 与 ATM 两者的优势,既保证了达到,又有较高的传输效率。
- MPLS 的格式如图所示,在原始的 IP 头之外,多了 MPLS 的头,里面可以打标签。
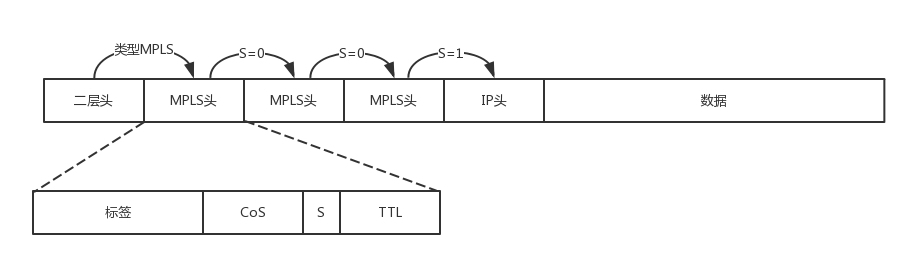
- 在二层头里面,有类型字段,0x0800 表示 IP,0x8847 表示 MPLS Label。
- 在 MPLS 头里面,首先是标签值占 20 位,接着是 3 位实验位,再接下来是 1 位栈底标志位,表示当前标签是否位于栈底了。这样就允许多个标签被编码到同一个数据包中,形成标签栈。最后是 8 位 TTL 存活时间字段,0 即代表过期。
- 标签交换路由器(LSR,Label Switching Router): 能认这个标签,并且能够根据这个标签转发的路由器
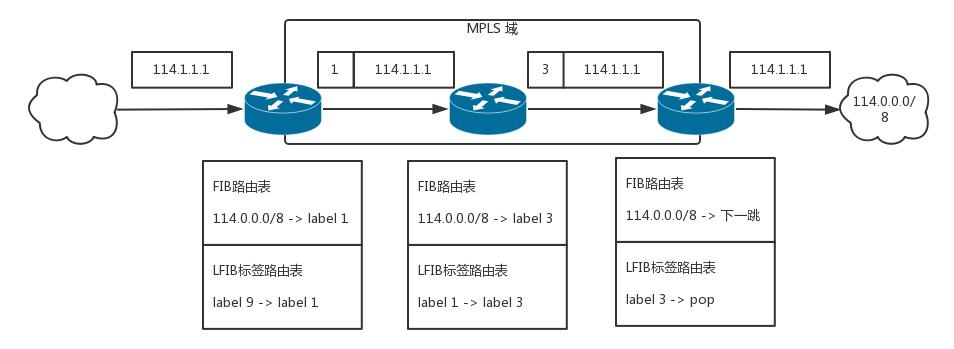
- 这种路由器会有两个表格,一个就是传统的 FIB,也即路由表,另一个就是 LFIB,标签转发表。有了这两个表,既可以进行普通的路由转发,也可以进行基于标签的转发。
- 在 MPLS 区域中间,使用标签进行转发,非 MPLS 区域,使用普通路由转发。
- 在边缘节点上,需要有能力将对于普通路由的转发,变成对于标签的转发。
- 这样一个通过标签转换而建立的路径称为 LSP,标签交换路径。在一条 LSP 上,沿数据包传送的方向,相邻的 LSR 分别叫上游 LSR(upstream LSR)和下游 LSR(downstream LSR)。
- LDP(Label Distribution Protocol),一个动态的生成标签的协议。
- 如果有一个边缘节点发现自己的路由表中出现了新的目的地址,同时此边缘节点存在上游 LSR,上游 LSR 尚有可供分配的标签,则边缘节点为新的路径分配标签,并向上游发出标签映射消息,其中包含分配的标签等信息。
- 收到标签映射消息的 LSR 记录相应的标签映射信息,在其标签转发表中增加相应的条目。之后继续按照上述规则向上游 LSR 分配标签。
- 当入口 LSR 收到标签映射消息时,在标签转发表中增加相应的条目。这时,就完成了 LSP 的建立。
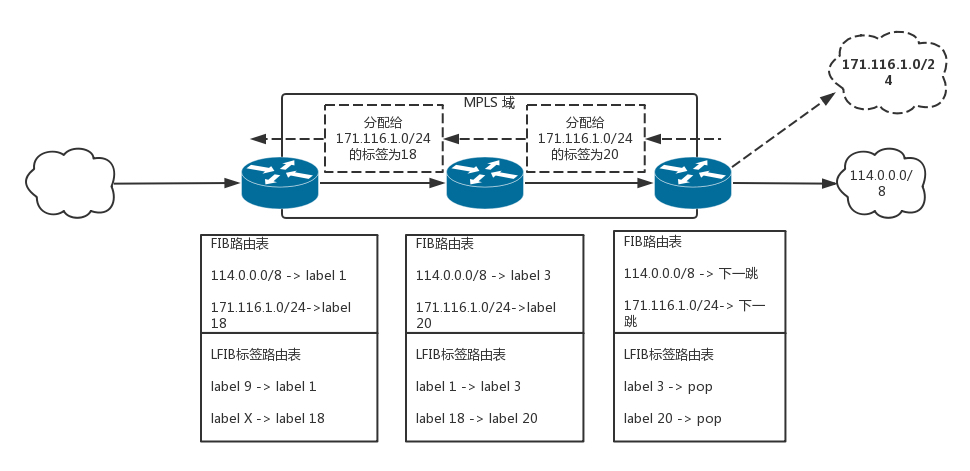
MPLS VPN
在 MPLS VPN 中,网络中的路由器分成以下几类: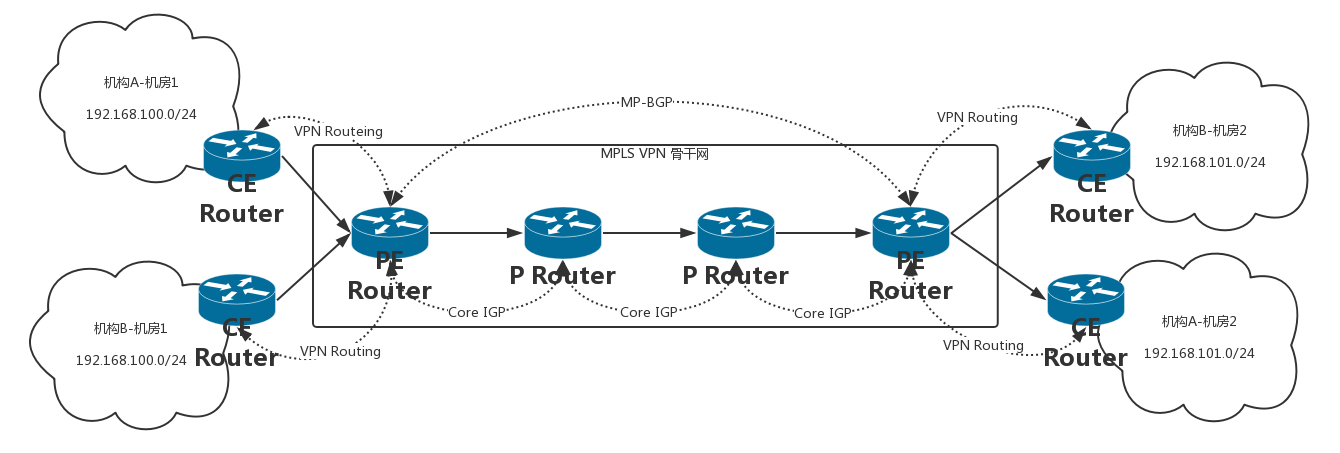
- PE(Provider Edge):运营商网络与客户网络相连的边缘网络设备
- CE(Customer Edge):客户网络与 PE 相连接的边缘设备
- P(Provider):这里特指运营商网络中除 PE 之外的其他运营商网络设备
两个问题与解决方案
- 传统 BGP 无法正确处理地址空间重叠的 VPN 的路由。
如上图,假设机构 A 和机构 B 都使用了 192.168.101.0/24 网段的地址,并各自发布了一条去往此网段的路由,BGP 将只会选择其中一条路由,从而导致去往另一个 VPN 的路由丢失。
- PE 路由器之间使用特殊的 MP-BGP 来发布 VPN 路由,在相互沟通的消息中,在一般 32 位 IPv4 的地址之前加上一个客户标示的区分符用于客户地址的区分,这种称为 VPN-IPv4 地址族。
- 路由表无法处理网段重叠的地址,当两个客户的 IP 包到达 PE 的时候,PE 就困惑了,因为网段是重复的。
- 在 PE 上,可以通过 VRF(VPN Routing&Forwarding Instance)建立每个客户一个路由表,与其它 VPN 客户路由和普通路由相互区分。
远端 PE 通过 MP-BGP 协议把业务路由放到近端 PE,近端 PE 根据不同的客户选择出相关客户的业务路由放到相应的 VRF 路由表中。因此,VPN 报文转发采用两层标签方式:
- 第一层(外层)标签在骨干网内部进行交换,指示从 PE 到对端 PE 的一条 LSP。VPN 报文利用这层标签,可以沿 LSP 到达对端 PE。
- 第二层(内层)标签在从对端 PE 到达 CE 时使用,在 PE 上,通过查找 VRF 表项,指示报文应被送到哪个 VPN 用户,或者更具体一些,到达哪一个 CE。这样,对端 PE 根据内层标签可以找到转发报文的接口。
MPLS VPN 发包过程
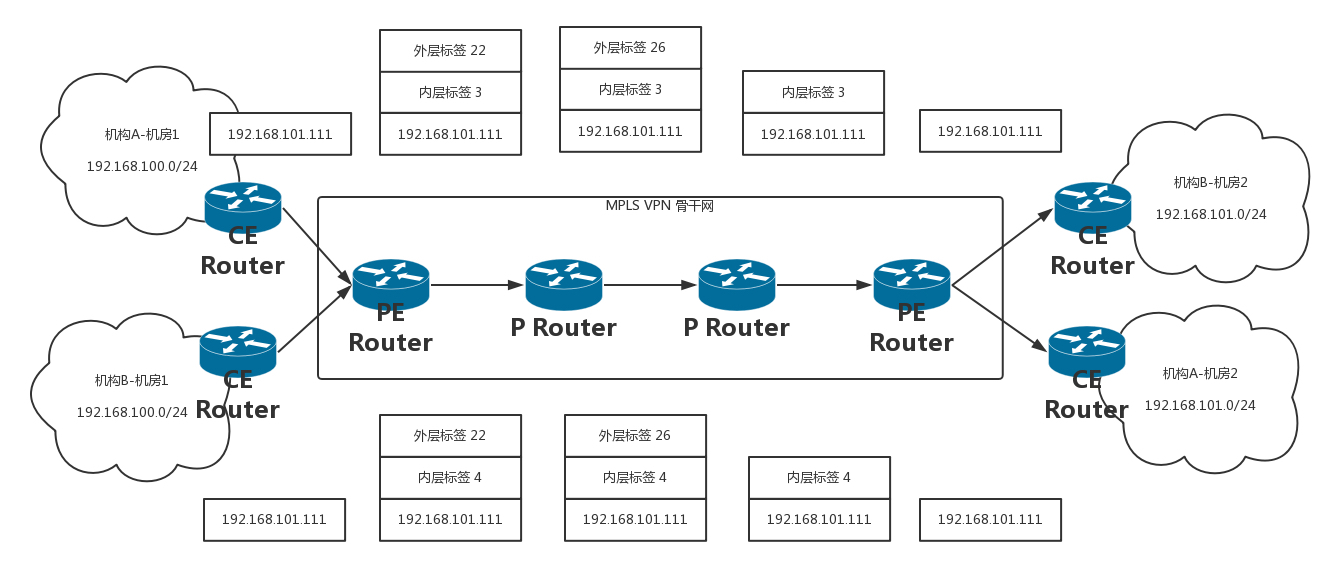
- 机构 A 和机构 B 都发出一个目的地址为 192.168.101.0/24 的 IP 报文,分别由各自的 CE 将报文发送至 PE。
- PE 会根据报文到达的接口及目的地址查找 VPN 实例表项 VRF,匹配后将报文转发出去,同时打上内层和外层两个标签。假设通过 MP-BGP 配置的路由,两个报文在骨干网走相同的路径。
- MPLS 网络利用报文的外层标签,将报文传送到出口 PE,报文在到达出口 PE 2 前一跳时已经被剥离外层标签,仅含内层标签。
- 出口 PE 根据内层标签和目的地址查找 VPN 实例表项 VRF,确定报文的出接口,将报文转发至各自的 CE。
- CE 根据正常的 IP 转发过程将报文传送到目的地。
第23讲 | 移动网络:去巴塞罗那,手机也上不了脸书
2G 网络
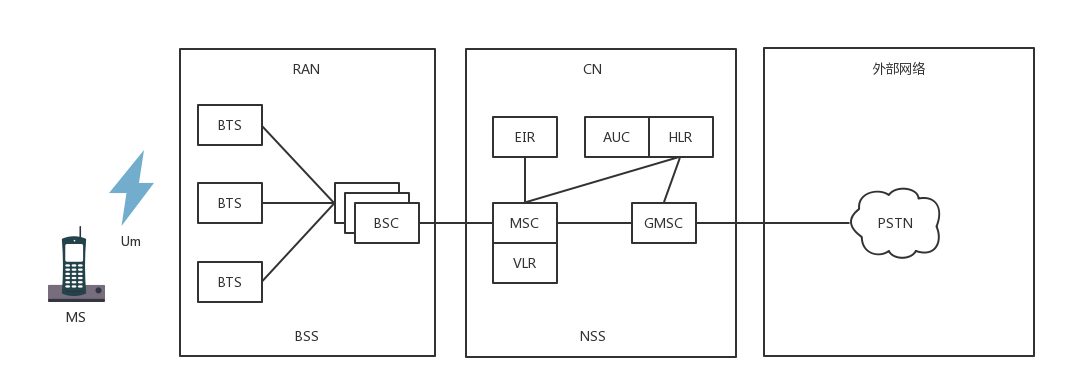
- 在 2G 时代,上网使用的不是 IP 网络,而是电话网络,走模拟信号,专业名称为公共交换电话网(PSTN,Public Switched Telephone Network)。
- 手机是通过收发无线信号来通信的,专业名称是 Mobile Station,简称 MS,需要嵌入 SIM。手机是客户端,而无线信号的服务端,就是基站子系统(BSS,Base Station SubsystemBSS)。
- 基站子系统分两部分,一部分对外提供无线通信,叫作基站收发信台(BTS,Base Transceiver Station),另一部分对内连接有线网络,叫作基站控制器(BSC,Base Station Controller)。基站收发信台通过无线收到数据后,转发给基站控制器。
2,3 两部分属于无线的部分,统称为无线接入网(RAN,Radio Access Network)。
- 基站控制器通过有线网络,连接到提供手机业务的运营商的数据中心,这部分称为核心网(CN,Core Network)。
- 基站数据的首先进入移动业务交换中心(MSC,Mobile Service Switching Center),它是进入核心网的入口,但是它不会让你直接连接到互联网上。
- 在让你的手机真正进入互联网之前,提供手机业务的运营商,需要认证是不是合法的手机接入。鉴权中心(AUC,Authentication Center)和设备识别寄存器(EIR,Equipment Identity Register)主要是负责安全性的。
- 需要看你是本地的号,还是外地的号,这个牵扯到计费的问题。访问位置寄存器(VLR,Visit Location Register)是看你目前在的地方,归属位置寄存器(HLR,Home Location Register)是看你的号码归属地。
- 当你的手机卡既合法又有钱的时候,才允许你上网,这个时候需要一个网关,连接核心网和真正的互联网。网关移动交换中心(GMSC ,Gateway Mobile Switching Center)就是干这个的,然后是真正的互连网。在 2G 时代,还是电话网络 PSTN。
数据中心里面的这些模块统称为网络子系统(NSS,Network and Switching Subsystem)。
2G 时代总结:
- 手机通过无线信号连接基站;
- 基站一面朝前接无线,一面朝后接核心网;
- 核心网一面朝前接到基站请求,一是判断你是否合法,二是判断你是不是本地号,还有没有钱,一面通过网关连接电话网络。
2.5G 网络
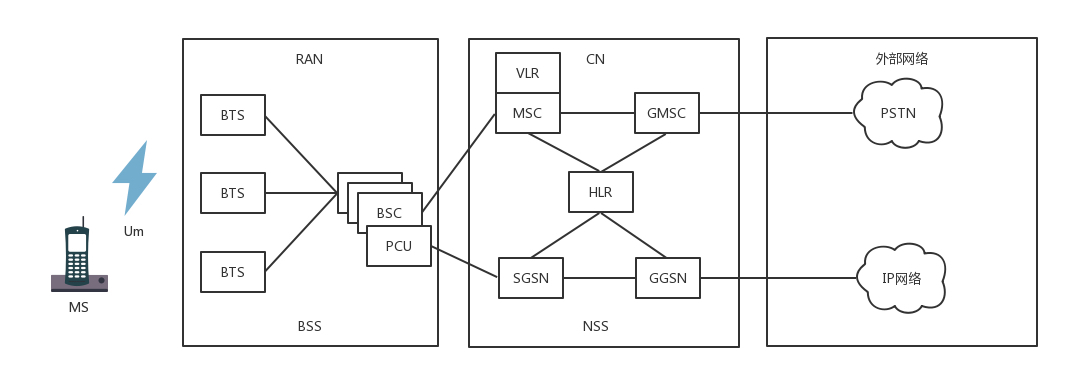
在原来 2G 电路交换的基础上,加入了分组交换业务,支持 Packet 的转发,从而支持 IP 网络。
- 在上述网络的基础上,基站一面朝前接无线,一面朝后接核心网。在朝后的组件中,多了一个分组控制单元(PCU,Packet Control Unit),用以提供分组交换通道。
- 在核心网里面,有个朝前的接待员(SGSN,Service GPRS Supported Node)和朝后连接 IP 网络的网关型 GPRS 支持节点(GGSN,Gateway GPRS Supported Node)。
3G 网络
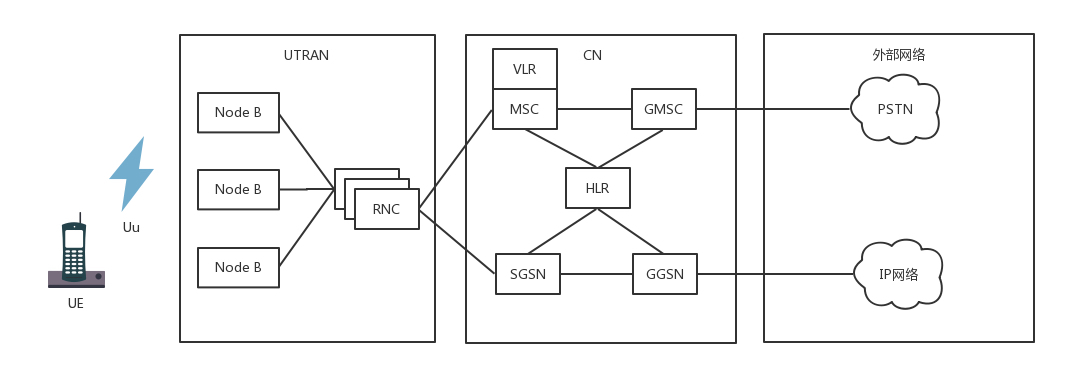
3G 时代,主要是无线通信技术有了改进,大大增加了无线的带宽。
- 以 W-CDMA 为例,理论最高 2M 的下行速度,因而基站改变了。一面朝外的是 Node B,一面朝内连接核心网的是无线网络控制器(RNC,Radio Network Controller)。
- 核心网以及连接的 IP 网络没有什么变化。
4G 网络
- 基站为 eNodeB,包含了原来 Node B 和 RNC 的功能,下行速度向百兆级别迈进。
- 核心网实现了控制面和数据面的分离
- HSS 用于存储用户签约信息的数据库,其实就是你这个号码归属地是哪里的,以及一些认证信息。
- MME 是核心控制网元,是控制面的核心,当手机通过 eNodeB 连上的时候,MME 会根据 HSS 的信息,判断你是否合法。如果允许连上来,MME 不负责具体的数据的流量,而是 MME 会选择数据面的 SGW 和 PGW,然后告诉 eNodeB 允许设备连接。
- 之后手机直接通过 eNodeB 连接 SGW,连上核心网,SGW 相当于数据面的接待员,并通过 PGW 连到 IP 网络。PGW 就是出口网关。在出口网关,有一个组件 PCRF,称为策略和计费控制单元,用来控制上网策略和流量的计费。
在前面的核心网里面,有接待员 MSC 或者 SGSN,你会发现检查是否合法是它负责,转发数据也是它负责,也即控制面和数据面是合二为一的,这样灵活性比较差,因为控制面主要是指令,多是小包,往往需要高的及时性;数据面主要是流量,多是大包,往往需要吞吐量。
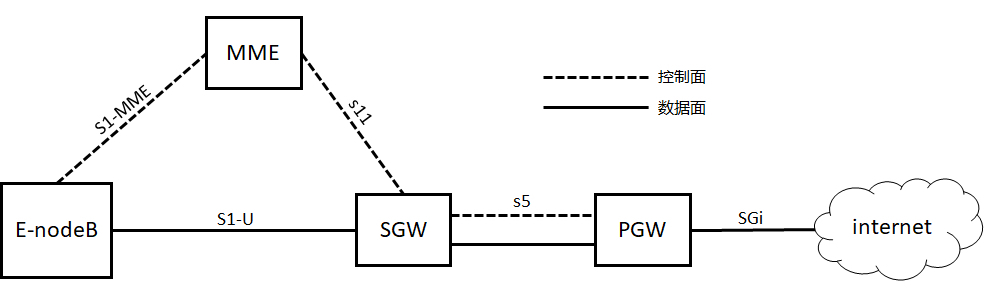
4G 网络协议解析
控制面协议(上图中虚线部分是控制面的协议)
- 当一个手机想上网的时候,先要连接 eNodeB,并通过 S1-MME 接口,请求 MME 对这个手机进行认证和鉴权。
- eNodeB 和 MME 之间的连接就是很正常的 IP 网络,但在传输层使用的是 SCTP 协议。
- SCTP 继承了 TCP 较为完善的拥塞控制并改进 TCP 的一些不足之处。
- SCTP 的第一个特点是多宿主,一台机器可以有多个网卡。SCTP 引入了联合(association)的概念,将多个接口、多条路径放到一个联合中来。当检测到一条路径失效时,协议就会通过另外一条路径来发送通信数据。
TCP 虽然服务端可以监听 0.0.0.0,也就是从哪个网卡来的连接都能接受,但是一旦建立了连接,就建立了四元组,也就选定了某个网卡。
- SCTP 的第二个特点是将一个联合分成多个流。一个联合中的所有流都是独立的,但均与该联合相关。每个流都给定了一个流编号,它被编码到 SCTP 报文中,通过联合在网络上传送。SCTP 的多个流不会相互阻塞。
- SCTP 的第三个特点是四次握手,防止 SYN 攻击。
在 TCP 中是三次握手,当服务端收到客户的 SYN 之后,返回一个 SYN-ACK 之前,就建立数据结构,并记录下状态,等待客户端发送 ACK 的 ACK。当恶意客户端使用虚假的源地址来伪造大量 SYN 报文时,服务端需要分配大量的资源,最终耗尽资源,无法处理新的请求。
SCTP 可以通过四次握手引入 Cookie 的概念,来有效地防止这种攻击的产生。在 SCTP 中,客户机使用一个 INIT 报文发起一个连接。服务器使用一个 INIT-ACK 报文进行响应,其中就包括了 Cookie。然后客户端就使用一个 COOKIE-ECHO 报文进行响应,其中包含了服务器所发送的 Cookie。这个时候,服务器为这个连接分配资源,并通过向客户机发送一个 COOKIE-ACK 报文对其进行响应。 - SCTP 的第四个特点是将消息分帧。SCTP 借鉴了 UDP 的机制,在数据传输中提供了消息分帧功能。当一端对一个套接字执行写操作时,可确保对等端读出的数据大小与此相同。
TCP 是面向流的,也即发送的数据没头没尾,没有明显的界限。这对于发送一个个消息类型的数据会不太方便。有可能客户端写入 10 个字节,然后再写入 20 个字节。二服务端读入 25 个字节,再读入 5 个字节,需要业务层去组合成消息。
- SCTP 的第五个特点是断开连接是三次挥手。在 TCP 里面,断开连接是四次挥手,允许另一端处于半关闭的状态。SCTP 选择放弃这种状态,当一端关闭自己的套接字时,对等的两端全部需要关闭,将来任何一端都不允许再进行数据的移动了。
- MME 通过认证鉴权后,需要建立一个数据面的数据通路。建立通路的过程还是控制面的事情,使用的是控制面的协议 GTP-C。
建设的数据通路分两段路,其实是两个隧道。一段是从 eNodeB 到 SGW,这个数据通路由 MME 通过 S1-MME 协议告诉 eNodeB,它是隧道的一端,通过 S11 告诉 SGW,它是隧道的另一端。第二端是从 SGW 到 PGW,SGW 通过 S11 协议知道自己是其中一端,并主动通过 S5 协议,告诉 PGW 它是隧道的另一端。
- GTP-C 协议是基于 UDP 的。如果看 GTP 头,我们可以看到,这里面有隧道的 ID,还有序列号。
- 通过序列号,不用 TCP,GTP-C 自己就可以实现可靠性,为每个输出信令消息分配一个依次递增的序列号,以确保信令消息的按序传递,并便于检测重复包。对于每个输出信令消息启动定时器,在定时器超时前未接收到响应消息则进行重发。
数据面协议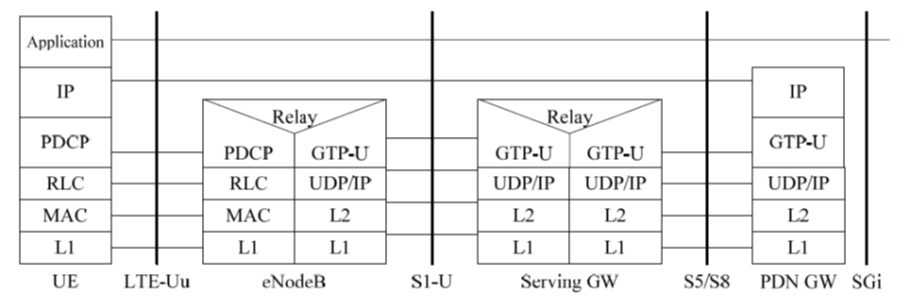
- 当两个隧道都打通,接在一起的时候,PGW 会给手机分配一个 IP 地址,这个 IP 地址是隧道内部的 IP 地址,可以类比为 IPsec 协议里面的 IP 地址。这个 IP 地址是归手机运营商管理的。
- 手机使用这个 IP 地址,连接 eNodeB,从 eNodeB 经过 S1-U 协议,通过第一段隧道到达 SGW,再从 SGW 经过 S8 协议,通过第二段隧道到达 PGW,然后通过 PGW 连接到互联网。
- 数据面都是通过 GTP-U 隧道协议封装起来,其格式如下
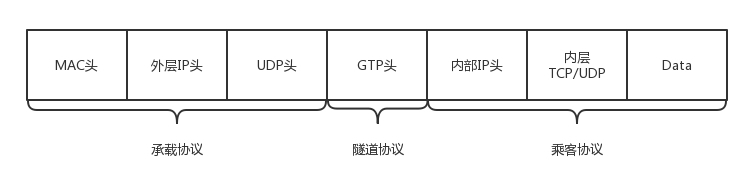
- 乘客协议: 数据是手机发出来的包,IP 是手机的 IP
- 隧道协议: 隧道协议里面有隧道 ID,不同的手机上线会建立不同的隧道,因而需要隧道 ID 来标识
- 承载协议: 承载协议的 IP 地址是 SGW 和 PGW 的 IP 地址
手机上网流程
一个手机开机之后上网的过程称为Attach。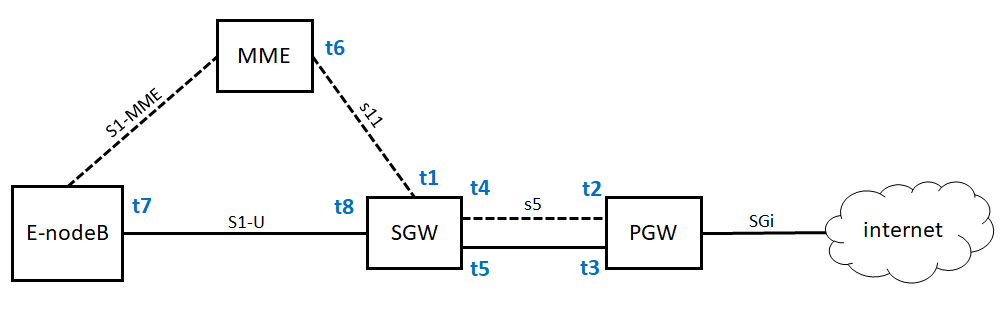
- 手机开机以后,在附近寻找基站 eNodeB,找到后给 eNodeB 发送 Attach Request,说“我来啦,我要上网”。
- eNodeB 将请求发给 MME,说“有个手机要上网”。
- MME 去请求手机,一是认证,二是鉴权,还会请求 HSS 看看有没有钱,看看是在哪里上网。
- 当 MME 通过了手机的认证之后,开始分配隧道,先告诉 SGW,说要创建一个会话(Create Session)。在这里面,会给 SGW 分配一个隧道 ID t1,并且请求 SGW 给自己也分配一个隧道 ID。
- SGW 转头向 PGW 请求建立一个会话,为 PGW 的控制面分配一个隧道 ID t2,也给 PGW 的数据面分配一个隧道 ID t3,并且请求 PGW 给自己的控制面和数据面分配隧道 ID。
- PGW 回复 SGW 说“创建会话成功”,使用自己的控制面隧道 ID t2,回复里面携带着给 SGW 控制面分配的隧道 ID t4 和控制面的隧道 ID t5,至此 SGW 和 PGW 直接的隧道建设完成。双方请求对方,都要带着对方给自己分配的隧道 ID,从而标志是这个手机的请求。
- 接下来 SGW 回复 MME 说“创建会话成功”,使用自己的隧道 ID t1 访问 MME,回复里面有给 MME 分配隧道 ID t6,也有 SGW 给 eNodeB 分配的隧道 ID t7。
- 当 MME 发现后面的隧道都建设成功之后,就告诉 eNodeB,“后面的隧道已经建设完毕,SGW 给你分配的隧道 ID 是 t7,你可以开始连上来了,但是你也要给 SGW 分配一个隧道 ID”。
- eNodeB 告诉 MME 自己给 SGW 分配一个隧道,ID 为 t8。
- MME 将 eNodeB 给 SGW 分配的隧道 ID t8 告知 SGW,从而前面的隧道也建设完毕。
异地上网问题
- 如果你在巴塞罗那,周围搜寻到的肯定是巴塞罗那的 eNodeB。
- 通过 MME 去查寻国内运营商的 HSS,看你是否合法,是否还有钱。
- 如果允许上网,你的手机和巴塞罗那的 SGW 会建立一个隧道,然后巴塞罗那的 SGW 和国内运营商的 PGW 建立一个隧道,然后通过国内运营商的 PGW 上网。
- 判断你是否能上网的在国内运营商的 HSS,控制你上网策略的是国内运营商的 PCRF,给手机分配的 IP 地址也是国内运营商的 PGW 负责的,给手机分配的 IP 地址也是国内运营商里统计的。
- 运营商由于是在 PGW 里面统计的,这样你的上网流量全部通过国内运营商即可,只不过巴塞罗那运营商也要和国内运营商进行流量结算。
综上,因此需要分 SGW 和 PGW 两个 GW。
由于你的上网策略是由国内运营商在 PCRF 中控制的,因而你还是上不了脸书。
第24讲 | 云中网络:自己拿地成本高,购买公寓更灵活
传统数据中心的问题
- 采购不灵活:如果客户需要一台电脑,那就需要自己采购、上架、插网线、安装操作系统,周期非常长。一旦采购了,一用就 N 年,不能退货,哪怕业务不做了,机器还在数据中心里留着。
- 运维不灵活:一旦需要扩容 CPU、内存、硬盘,都需要去机房手动弄,非常麻烦。
- 规格不灵活:采购的机器往往动不动几百 G 的内存,而每个应用往往可能只需要 4 核 8G,所以很多应用混合部署在上面,端口各种冲突,容易相互影响。
- 复用不灵活:一台机器,一旦一个用户不用了,给另外一个用户,那就需要重装操作系统。因为原来的操作系统可能遗留很多数据,非常麻烦。
从物理机到虚拟机
为了解决上述这些问题,人们发明了一种叫虚拟机的东西,并基于它产生了云计算技术。
- 个人桌面系统有一些虚拟机软件,可以方便的创建虚拟机
- 在数据中心中,有一种类似的开源技术 qemu-kvm,能让你在一台巨大的物理机里,掏出一台台小小的虚拟机,它用的是软件模拟硬件的方式。
虚拟网卡的原理
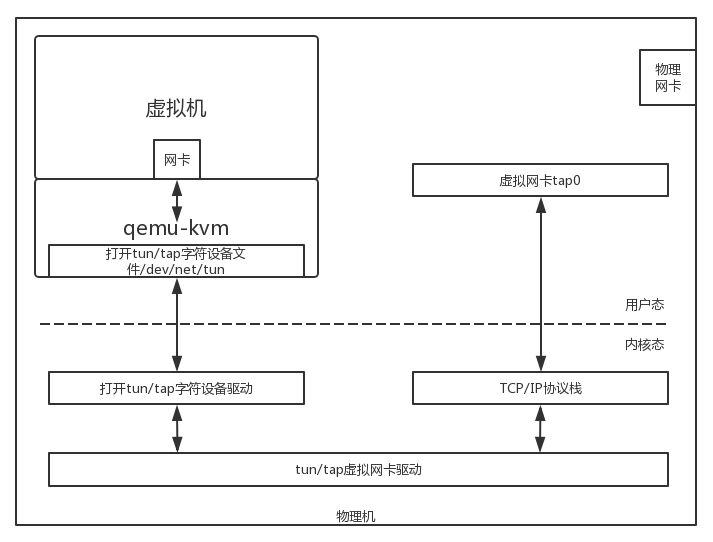
虚拟机要有一张网卡。对于 qemu-kvm 来说,这是通过 Linux 上的一种 TUN/TAP 技术来实现的。
- 虚拟机软件打开一个称为 TUN/TAP 的 Char Dev(字符设备文件)。打开了这个字符设备文件之后,在物理机上就能看到一张虚拟 TAP 网卡。
- 虚拟化软件会将打开的这个文件,在虚拟机里面虚拟出一张网卡,让虚拟机里面的应用觉得它们真有一张网卡。于是,所有的网络包都往这里发。
- 网络包会到虚拟化软件这里,它会将网络包转换成为文件流,写入字符设备。
- 内核中 TUN/TAP 字符设备驱动会收到这个写入的文件流,交给 TUN/TAP 的虚拟网卡驱动。
- 虚拟网卡驱动将文件流再次转成网络包,交给 TCP/IP 协议栈,最终从虚拟 TAP 网卡发出来,成为标准的网络包。至此,网络包就从虚拟机里面发到了虚拟机外面。
虚拟网卡连接到数据中心(云中),需要注意的问题
- 共享
- 尽管每个虚拟机都会有一个或者多个虚拟网卡,但是物理机上可能只有有限的网卡。那这么多虚拟网卡如何共享同一个出口?
- 隔离
- 安全隔离,两个虚拟机可能属于两个用户,那怎么保证一个用户的数据不被另一个用户窃听?
- 流量隔离,两个虚拟机,如果有一个疯狂下片,会不会导致另外一个上不了网?
- 互通
- 如果同一台机器上的两个虚拟机,属于同一个用户的话,这两个如何相互通信?
- 如果不同物理机上的两个虚拟机,属于同一个用户的话,这两个如何相互通信?
- 灵活
- 虚拟机和物理不同,会经常创建、删除,从一个机器漂移到另一台机器,有的互通、有的不通等等,灵活性比物理网络要好得多,需要能够灵活配置。
共享与互通问题
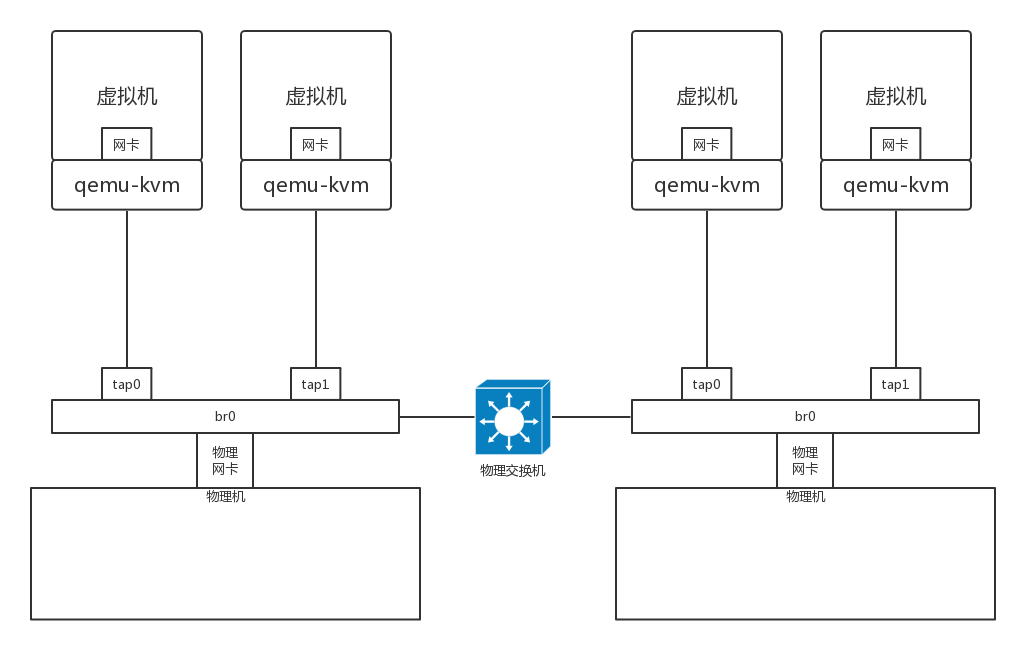
- 通过虚拟交换机连接虚拟交换机。在 Linux 上有一个命令叫作 brctl,可以创建虚拟的网桥 brctl addbr br0。将两个虚拟机的虚拟网卡,都连接到虚拟网桥 brctl addif br0 tap0 上,再将两个虚拟机配置相同的子网网段,两台虚拟机就能够相互通信了。
- 虚拟机网络访问外部的方式
- 桥接
- 桥接结构如下,虚拟交换机将虚拟机连接在一起,物理网卡也连接到这个虚拟交换机上。
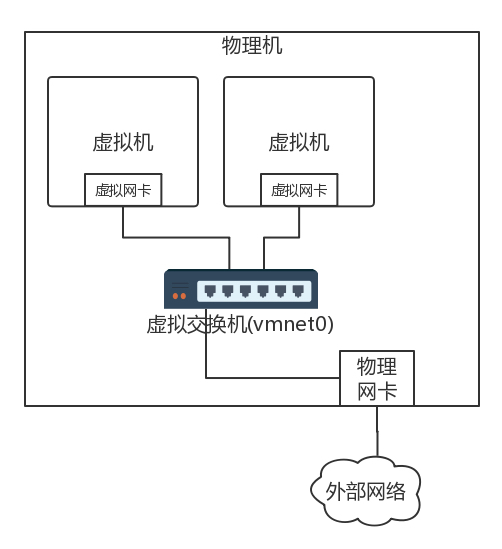
- 相当于将物理机和虚拟机放在同一个网桥上,是一个网段的,如下图。
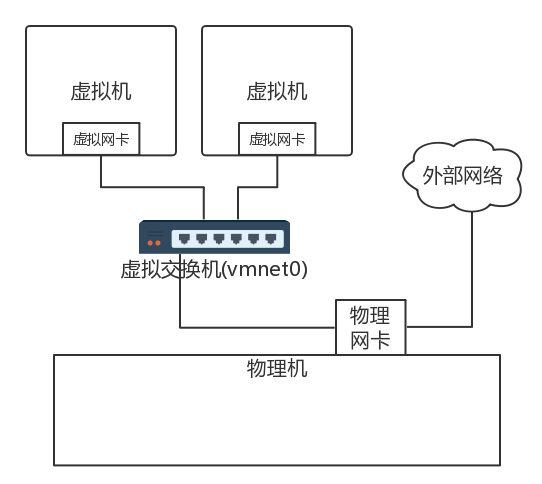
- 在数据中心里面,采取的也是类似的技术,只不过都是 Linux,在每台机器上都创建网桥 br0,虚拟机的网卡都连到 br0 上,物理网卡也连到 br0 上,所有的 br0 都通过物理网卡出来连接到物理交换机上。
- 优劣: 这种方式不但解决了同一台机器的互通问题,也解决了跨物理机的互通问题,因为都在一个二层网络里面。
- 劣势: 在一个二层网络里面,当虚拟机数量非常多时,广播会很严重。
- 桥接结构如下,虚拟交换机将虚拟机连接在一起,物理网卡也连接到这个虚拟交换机上。
- NAT
- NAT 模式的网络结构如下。它会在你的笔记本电脑里内置一个 DHCP 服务器,为笔记本电脑上的虚拟机动态分配 IP 地址。
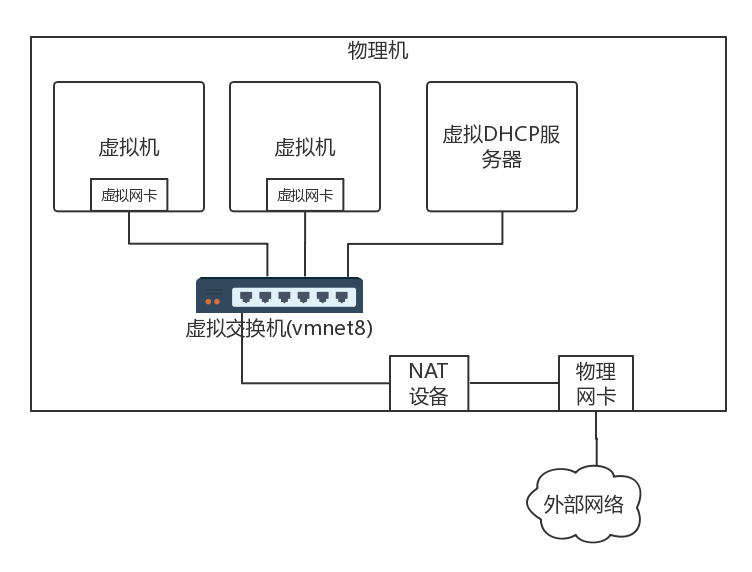
- 虚拟机与物理机分属不同网段,虚拟机要想访问物理机的时候,需要将地址 NAT 成为物理机的地址。
- 在数据中心里面,也是使用类似的方式。所有电脑都通过内网网口连接到一个网桥 br0 上,虚拟机要想访问互联网,需要通过 br0 连到路由器上,然后通过路由器将请求 NAT 成为物理网络的地址,转发到物理网络。
- 优势: 一台物理上的虚拟机在同一个网段中,可以直接互通;跨物理机可以通过路由器互通;且虚拟机非常多时,不会有广播问题。
- NAT 模式的网络结构如下。它会在你的笔记本电脑里内置一个 DHCP 服务器,为笔记本电脑上的虚拟机动态分配 IP 地址。
- 桥接
隔离问题
- 一台物理机上的两台虚拟机的隔离
- brctl 创建的网桥支持 VLAN 功能,可以设置两个虚拟机的 tag,这样在这个虚拟网桥上,两个虚拟机是不互通的。
- 跨物理机的虚拟机隔离
- 有一个命令vconfig,可以基于物理网卡 eth0 创建带 VLAN 的虚拟网卡,所有从这个虚拟网卡出去的包,都带这个 VLAN,如果这样,跨物理机的互通和隔离就可以通过这个网卡来实现。
- 遗留问题(改进空间)
- VLAN 的隔离,数目太少,VLAN ID 只有 4096 个,在机器数多了之后,明显不够用。
- 这个配置不够灵活。谁和谁通,谁和谁不通,流量的隔离也没有实现。
第25讲 | 软件定义网络:共享基础设施的小区物业管理办法
软件定义网络(SDN)
传统配置的问题: 灵活性差,且缺少统一的视图,统一的管理。配置整个云平台的网络通路,你需要登录到这台机器上配置这个,再登录到另外一个设备配置那个,才能成功。
SDN 则解决了上述问题。它有三个特点。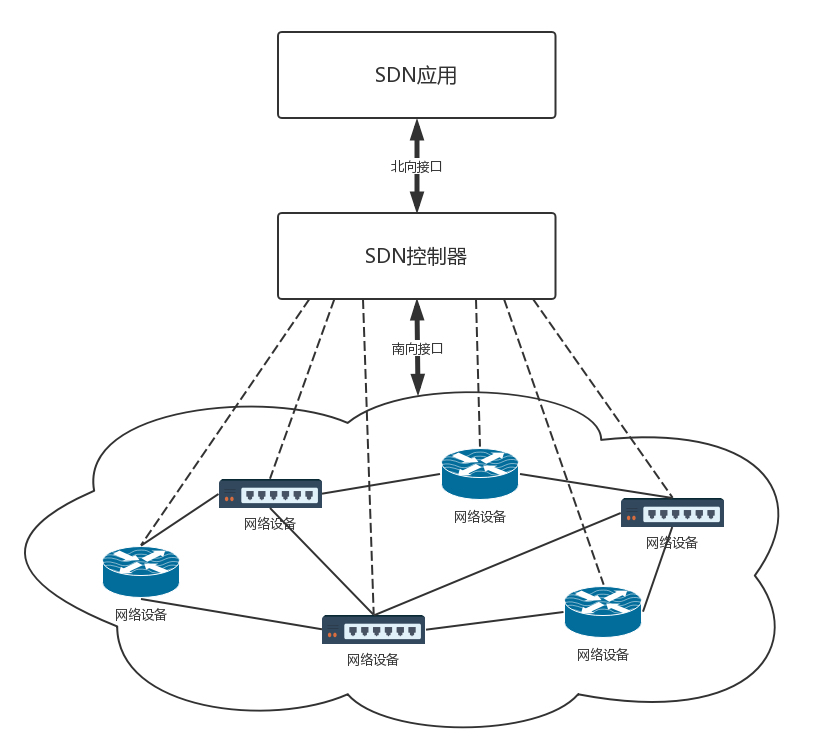
- 控制与转发分离:转发平面就是一个个虚拟或者物理的网络设备,控制平面就是统一的控制中心。
- 控制平面与转发平面之间的开放接口:控制器向上提供接口,被应用层调用,被称为北向接口。控制器向下调用接口,来控制网络设备,被称为南向接口。
- 逻辑上的集中控制:逻辑上集中的控制平面可以控制多个转发面设备,也就是控制整个物理网络,因而可以获得全局的网络状态视图,并根据该全局网络状态视图实现对网络的优化控制。
OpenFlow 和 OpenvSwitch
SDN 有很多种实现方式,OpenFlow 是 SDN 控制器和网络设备之间互通的南向接口协议的一个开源实现,OpenvSwitch 用于创建软件的虚拟交换机。OpenvSwitch 是支持 OpenFlow 协议的。它们都可以被统一的 SDN 控制器管理,从而实现物理机和虚拟机的网络连通。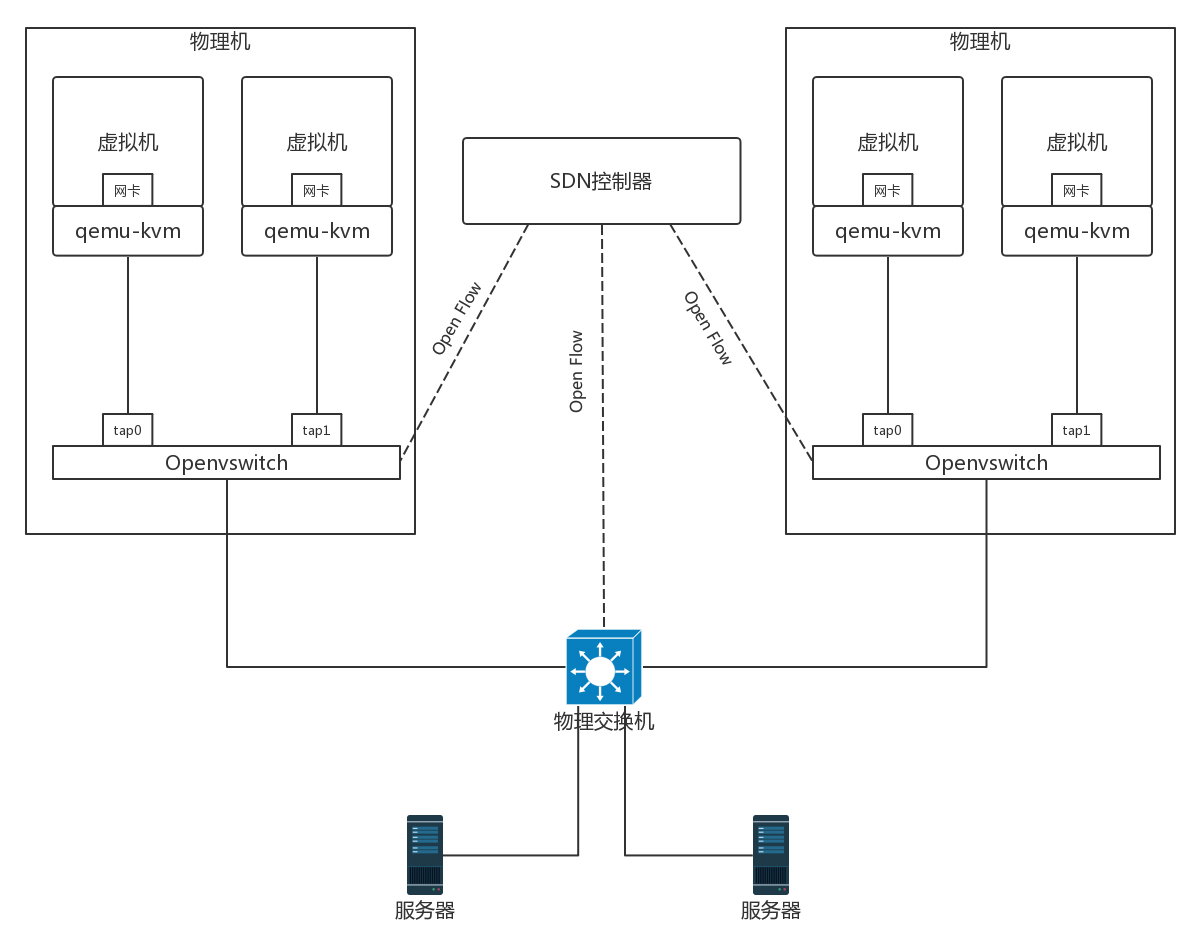
在 OpenvSwitch 里面,有一个流表规则,任何通过这个交换机的包,都会经过这些规则进行处理,从而接收、转发、放弃。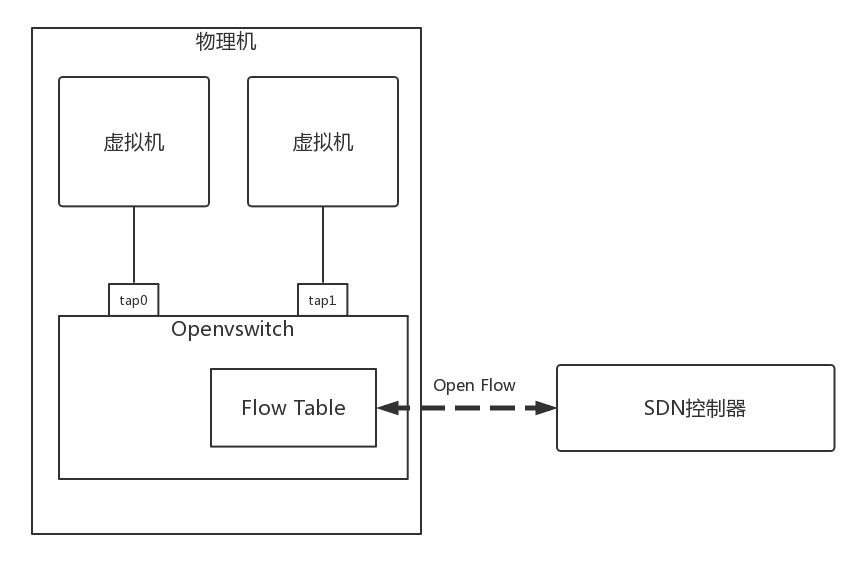
流表其实就是一个个表格,每个表格好多行,每行都是一条规则。每条规则都有优先级,先看高优先级的规则,再看低优先级的规则。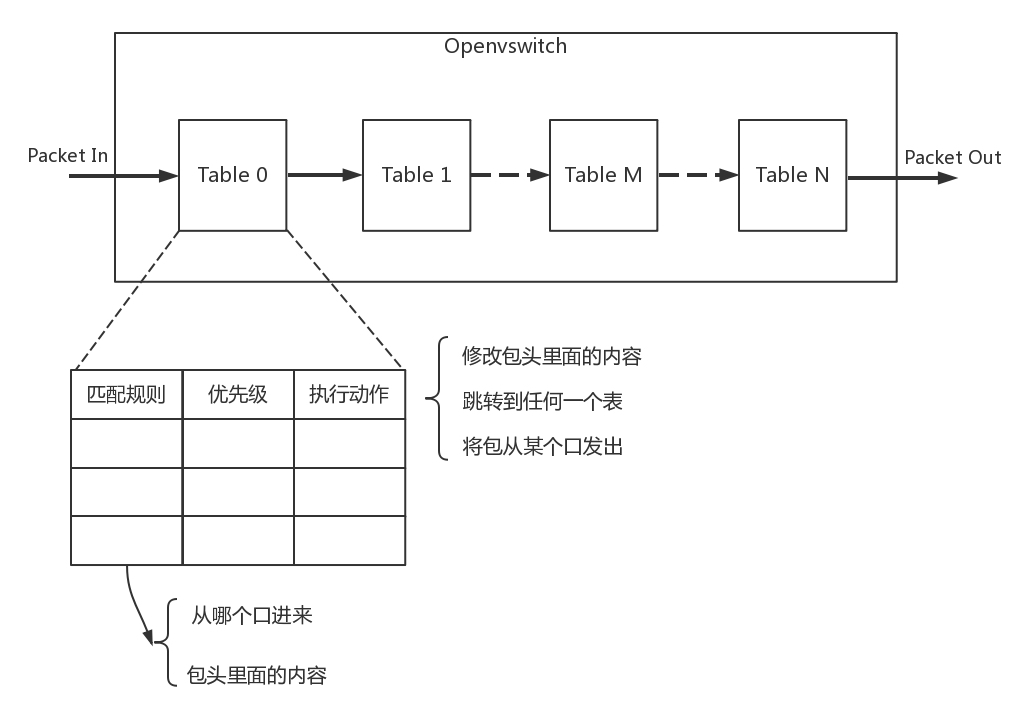
具体来说,流表的处理可以覆盖 TCP/IP 协议栈的四层。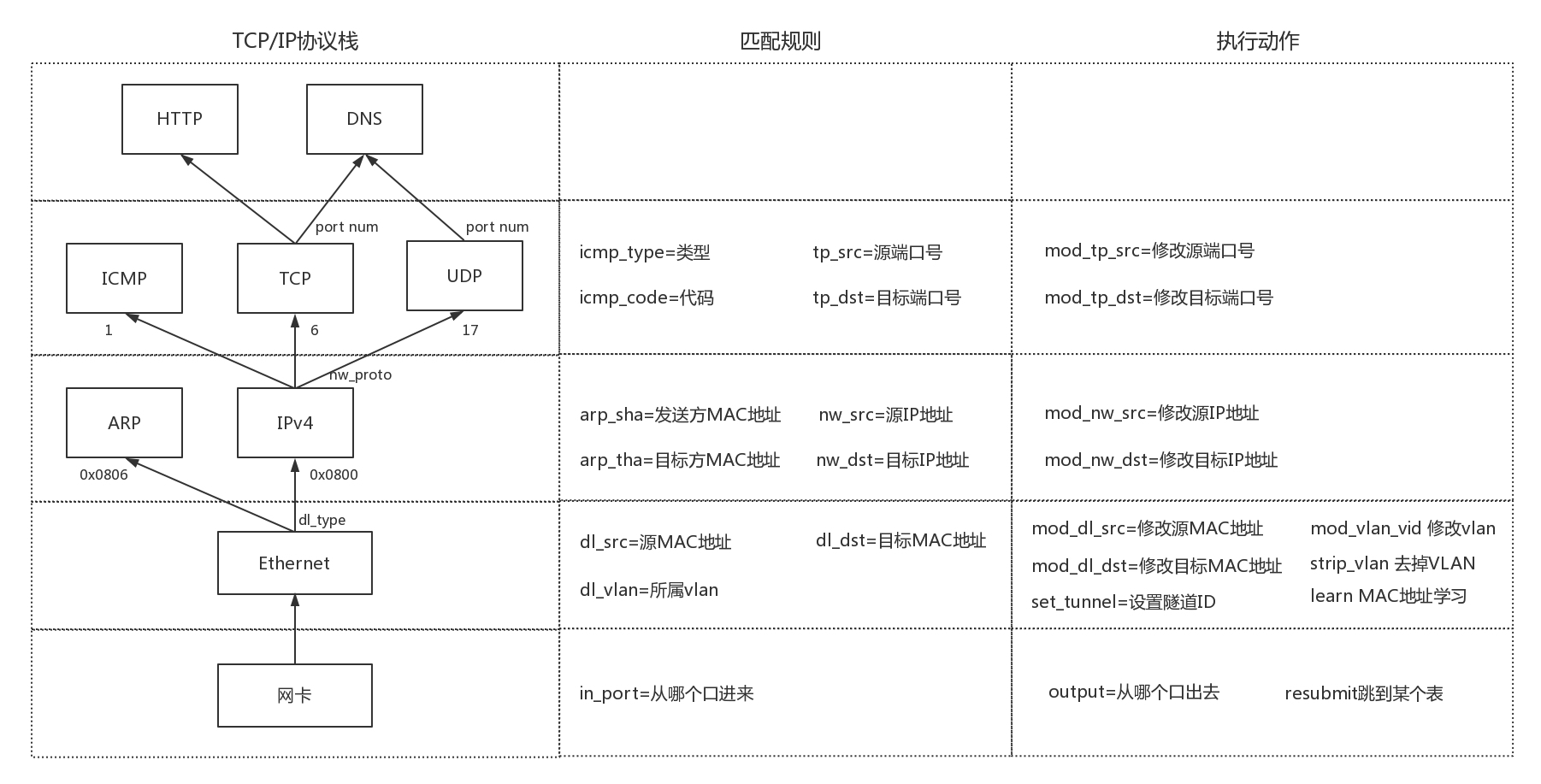
- 物理层
- 匹配规则
- 从哪个口进来
- 执行动作
- 从哪个口出去
- 匹配规则
- MAC 层
- 匹配规则
- 源 MAC(dl_src)
- 目标 MAC(dl_dst)
- 所属 vlan(dl_vlan)
- 执行动作
- 修改源 MAC(mod_dl_src)
- 修改目标 MAC(mod_dl_dst)
- 修改 VLAN(mod_vlan_vid)
- 删除 VLAN(strip_vlan)
- MAC 地址学习(learn)
- 匹配规则
- 网络层
- 匹配规则
- 源 IP(nw_src)
- 目标 IP(nw_dst)
- 执行动作
- 修改源 IP(mod_nw_src)
- 修改目标 IP(mod_nw_dst)
- 匹配规则
- 传输层
- 匹配规则
- 源端口(tp_src)
- 目标端口(tp_dst)
- 执行动作
- 修改源端口(mod_tp_src)
- 修改目标端口(mod_tp_dst)
- 匹配规则
实验一:用 OpenvSwitch 实现 VLAN 的功能
在 OpenvSwitch 中端口 port 分两种。
- access port
- 这个端口配置 tag,从这个端口进来的包会被打上这个 tag
- 如果网络包本身带有的 VLAN ID 等于 tag,则会从这个 port 发出
- 从 access port 发出的包不带 VLAN ID
- trunk port
- 这个 port 不配置 tag,配置 trunks
- 如果 trunks 为空,则所有的 VLAN 都 trunk,也就意味着对于所有 VLAN 的包,本身带什么 VLAN ID,就是携带着什么 VLAN ID,如果没有设置 VLAN,就属于 VLAN 0,全部允许通过
- 如果 trunks 不为空,则仅仅带着这些 VLAN ID 的包通过
我们创建一个如下的网络进行说明(注意这里禁止了 MAC 地址学习)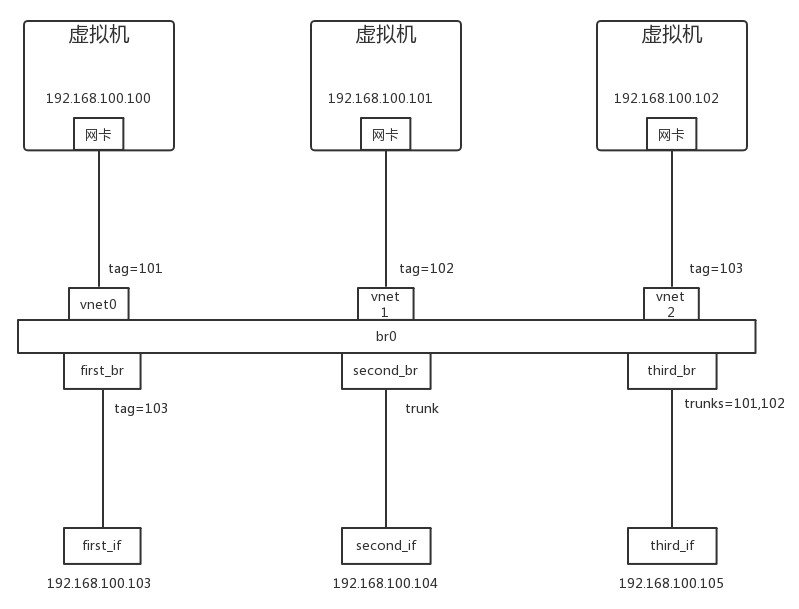
- 从 192.168.100.102 来 ping 192.168.100.103
- first_if 收到包了,从 first_br 出来的包头是没有 VLAN ID 的。因为从 vnet 2 中出来的包被打上了 VLAN ID 103,匹配了 first_br 的 tag,之后通过 first_br 后 VLAN ID 被删除。
- second_if 收到包了,且带有 VLAN ID。因为 second_br 是 trunk port,因而出来的包头是有 VLAN ID 的,这个 VLAN ID 是在通过 vnet 2 时被加上的。
- third_if 收不到包。因为 trunks 不匹配网络包的 VLAN ID=103。
- 从 192.168.100.100 来 ping 192.168.100.105,
- first_if 收不到包。
- second_if 收到包了,且带有 VLAN ID=101。
- third_if 收到包了,且带有 VLAN ID=101。
- 从 192.168.100.101 来 ping 192.168.100.104
- first_if 收不到包。
- second_if 收到包了,且带有 VLAN ID=102。
- third_if 收到包了,且带有 VLAN ID=102。
实验二:用 OpenvSwitch 模拟网卡绑定,连接交换机
在 OpenvSwitch 里面,有个 bond_mode,可以设置为以下三个值:
- active-backup:一个连接是 active,其他的是 backup,当 active 失效的时候,backup 顶上
- balance-slb:流量安装源 MAC 和 output VLAN 进行负载均衡
- balance-tcp:必须在支持 LACP 协议的情况下才可以,可根据 L2, L3, L4 进行负载均衡
我们搭建一个如下的环境进行说明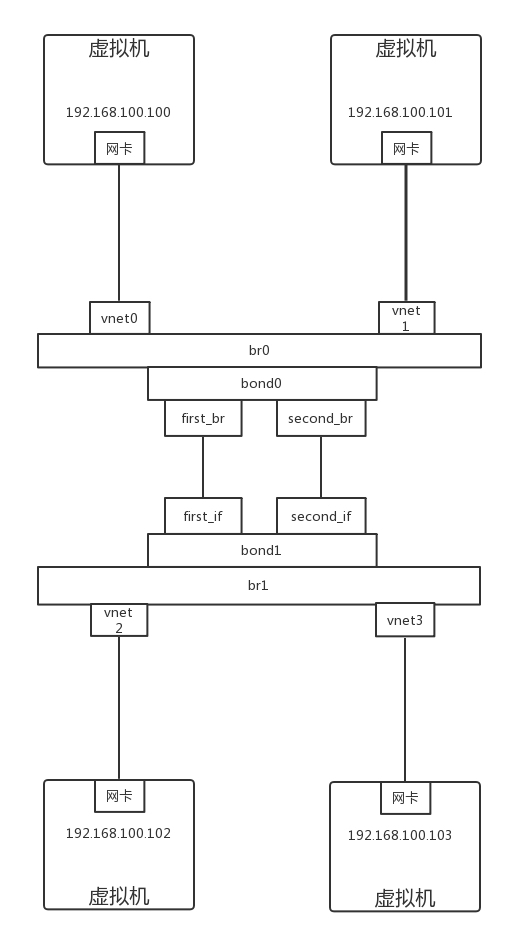
- 默认情况下 bond_mode 是 active-backup 模式,一开始 active 的是 first_br 和 first_if。
- 从 192.168.100.100 ping 192.168.100.102,以及从 192.168.100.101 ping 192.168.100.103 的时候,所有的包都是从 first_if 通过。
- 把 first_if 设成 down,则 second_if 开始有流量,对于 192.168.100.100 和 192.168.100.101 是没有受到影响的。
- 把 bond_mode 设为 balance-slb。
- 同时在 192.168.100.100 ping 192.168.100.102,在 192.168.100.101 ping 192.168.100.103,则包会被分流。
OpenvSwitch 架构
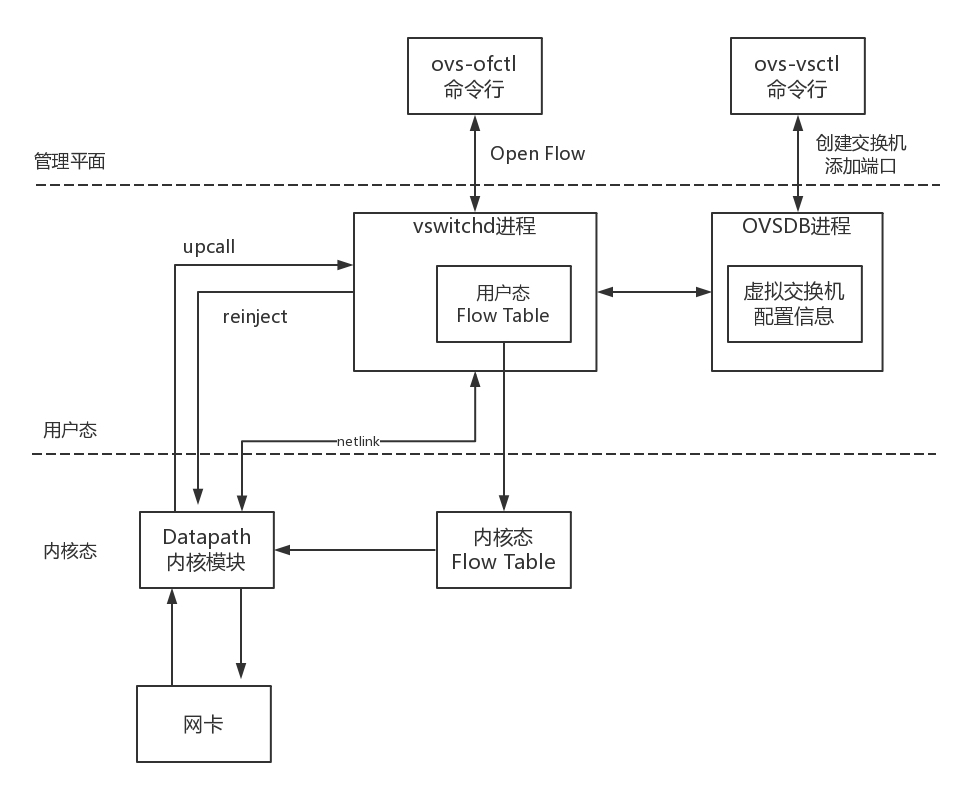
- 在用户态有两个重要的进程,也有两个重要的命令行工具。
- OVSDB 进程。ovs-vsctl 命令行会和这个进程通信,去创建虚拟交换机,创建端口,将端口添加到虚拟交换机上,OVSDB 会将这些拓扑信息保存在一个本地的文件中。
- vswitchd 进程。ovs-ofctl 命令行会和这个进程通信,去下发流表规则,规则里面会规定如何对网络包进行处理,vswitchd 会将流表放在用户态 Flow Table 中。
- 在内核态,有内核模块 OpenvSwitch.ko,对应图中的 Datapath 部分。在网卡上注册一个函数,每当有网络包到达网卡的时候,这个函数就会被调用。并在这个函数中拿到网络包,将各个层次的重要信息拿出来,例如:
- 在物理层,in_port 即包进入的网口的 ID
- 在 MAC 层,源和目的 MAC 地址
- 在 IP 层,源和目的 IP 地址
- 在传输层,源和目的端口号
- 在内核中,有一个内核态 Flow Table。接下来内核模块在这个内核流表中匹配规则,如果匹配上了,则执行操作、修改包,或者转发或者放弃。如果内核没有匹配上,则需要进入用户态,用户态和内核态之间通过 Linux 的一个机制 Netlink 相互通信。
- 内核通过 upcall,告知用户态进程 vswitchd 在用户态 Flow Table 里面去匹配规则,这里面的规则是全量的流表规则,而内核 Flow Table 里面的只是为了快速处理,保留了部分规则,内核里面的规则过一阵就会过期。
- 当在用户态匹配到了流表规则之后,就在用户态执行操作,同时将这个匹配成功的流表通过 reinject 下发到内核,从而接下来的包都能在内核找到这个规则。
- 这里调用 openflow 协议的,是本地的命令行工具,也可以是远程的 SDN 控制器,一个重要的 SDN 控制器是 OpenDaylight。如下图所示:
如何在云计算中使用 OpenvSwitch?
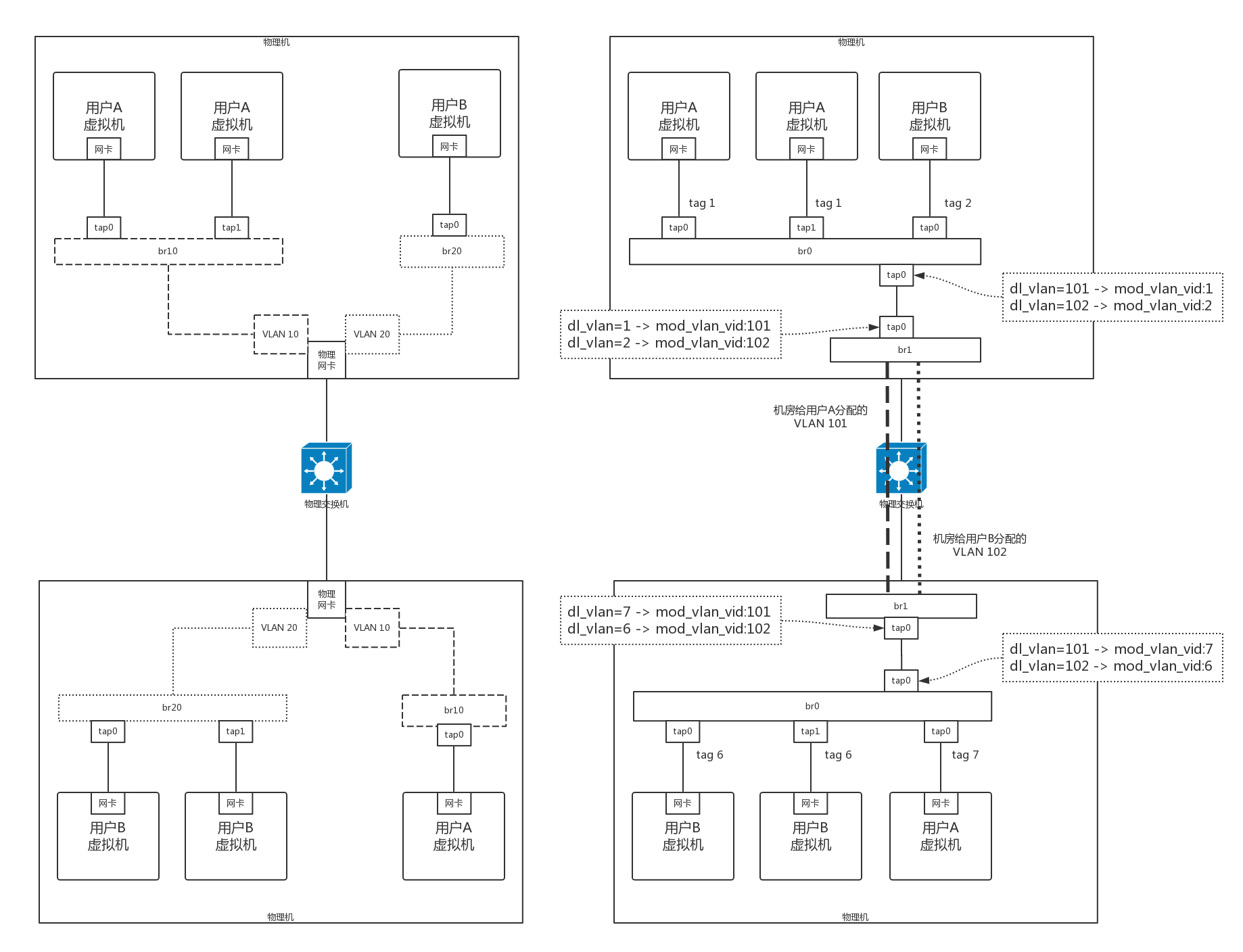
- 左边是传统场景
- 如果要使用一个新的 VLAN,还需要创建一个属于新的 VLAN 的虚拟网卡,并且为这个租户创建一个单独的虚拟网桥,这样用户越来越多的时候,虚拟网卡和虚拟网桥会越来越多,管理非常复杂。
- 虚拟机的 VLAN 和物理环境的 VLAN 是透传的,也即从一开始规划的时候,就需要匹配起来,将物理环境和虚拟环境强绑定,本来就不灵活。
- 右边是基于 OpenvSwitch 的场景
- 所有的虚拟机都可以放在一个网桥 br0 上,通过不同的用户配置不同的 tag,就能够实现隔离。
- 还可以创建一个虚拟交换机 br1,将物理网络和虚拟网络进行隔离。物理网络有物理网络的 VLAN 规划,虚拟机在一台物理机上,所有的 VLAN 都是从 1 开始的。由于一台机器上的虚拟机不会超过 4096 个,所以 VLAN 在一台物理机上如果从 1 开始,肯定够用了。
- OpenvSwitch 可以对包的内容进行修改。例如通过匹配 dl_vlan,然后执行 mod_vlan_vid 来改进进出出物理机的网络包。以此可以实现物理机的网络和虚拟机的网络的解耦与分别管理。
尽管租户多了,物理环境的 VLAN 还是不够用,但是有了 OpenvSwitch 的映射,将物理和虚拟解耦,从而可以让物理环境使用其他技术,而不影响虚拟机环境,这个我们后面再讲。
第26讲 | 云中的网络安全:虽然不是土豪,也需要基本安全和保障
对于公有云上的虚拟机,建议仅仅开放需要的端口,而将其他的端口一概关闭。
- 采用的方式常常是用ACL(Access Control List,访问控制列表)来控制 IP 和端口。
- 设置好了这些规则,只有指定的 IP 段能够访问指定的开放接口,在云平台上,这些规则的集合常称为安全组。
Netfilter 与 ip_tables
在 Linux 内核中,有一个框架叫 Netfilter。它可以在一些网络层节点插入 hook 函数。这些函数可以截获数据包,对数据包进行干预。
- 节点分类如图
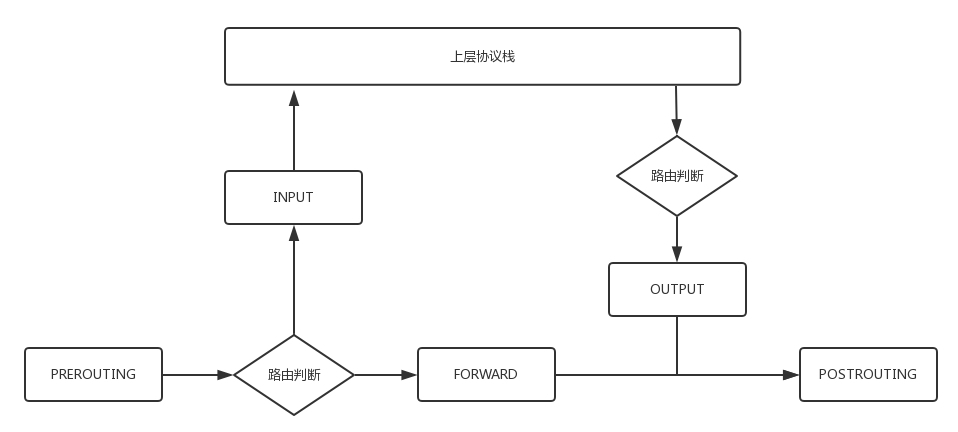
- 首先拿下 MAC 头看看,是不是我的。如果是,则拿下 IP 头来。得到目标 IP 之后呢,就开始进行路由判断。在路由判断之前,这个节点我们称为PREROUTING。
- 如果发现 IP 是我的,包就应该是我的,就发给上面的传输层,这个节点叫作INPUT。
- 如果发现 IP 不是我的,就需要转发出去,这个节点称为FORWARD。
- 如果是我的,上层处理完毕完毕后,一般会返回一个处理结果,这个处理结果会发出去,这个节点称为OUTPUT。
无论是 FORWARD 还是 OUTPUT,都是路由判断之后发生的
- 最后一个节点是POSTROUTING。
- 可以做的干预如下
- 做一定的修改,然后决策是否接着交给 TCP/IP 协议栈处理;或者可以交回给协议栈,那就是ACCEPT
- 过滤掉,不再传输,就是DROP
- 发送给某个用户态进程处理,就是QUEUE
Netfilter 的一个著名的实现,就是内核模块 ip_tables。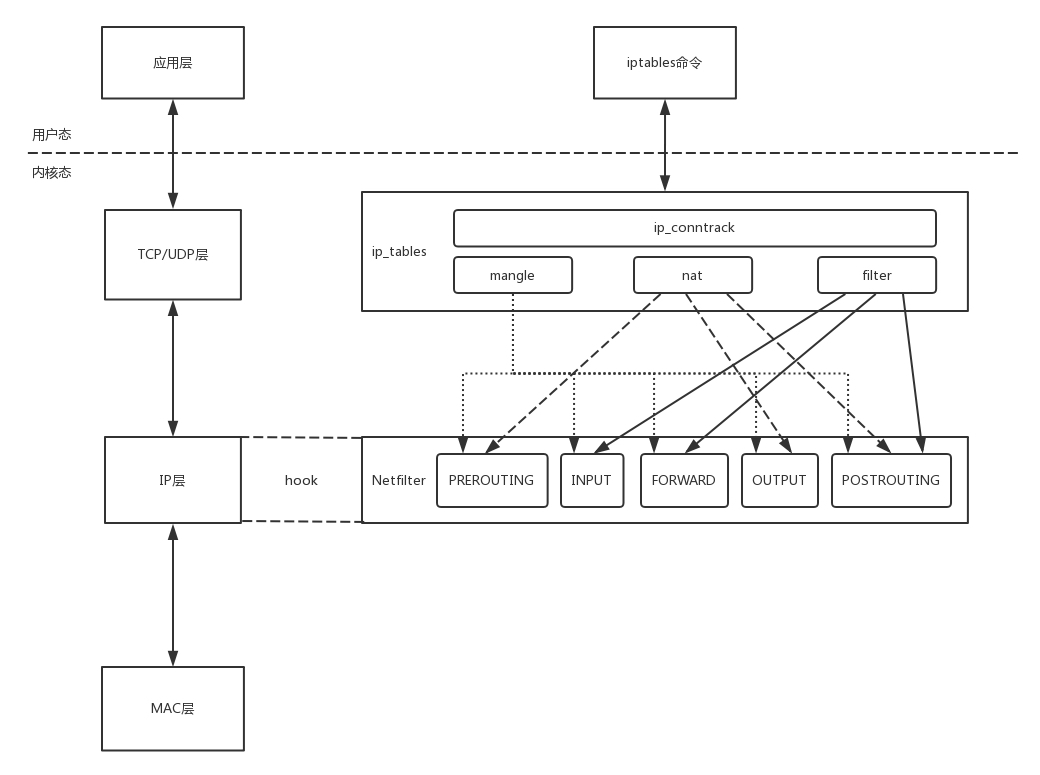
- 内核模块 ip_tables 在上述五个节点上埋下函数,从而可以根据规则进行包的处理。按功能可分为四大类:
- 连接跟踪(conntrack)
- 数据包的过滤(filter)
- 网络地址转换(nat)
- 数据包的修改(mangle)
其中连接跟踪是基础功能,被其他功能所依赖。
- 在用户态,有一个客户端程序 iptables,用命令行来干预内核模块 ip_tables 的规则。内核的功能对应 iptables 的命令行来讲,就是表和链的概念。
- iptables 的表分为四种:raw–>mangle–>nat–>filter。这四个优先级依次降低,raw 不常用,所以主要功能都在其他三种表里实现。每个表可以设置多个链。
- filter 表处理过滤功能,主要包含三个链:
- INPUT 链:过滤所有目标地址是本机的数据包
- FORWARD 链:过滤所有路过本机的数据包
- OUTPUT 链:过滤所有由本机产生的数据包
- nat 表主要是处理网络地址转换,可以进行 Snat(改变数据包的源地址)、Dnat(改变数据包的目标地址),包含三个链:
- PREROUTING 链:可以在数据包到达防火墙时改变目标地址
- OUTPUT 链:可以改变本地产生的数据包的目标地址
- POSTROUTING 链:在数据包离开防火墙时改变数据包的源地址
- mangle 表主要是修改数据包,包含:
- PREROUTING 链
- INPUT 链
- FORWARD 链
- OUTPUT 链
- POSTROUTING 链
- filter 表处理过滤功能,主要包含三个链:
最终,基于 iptables 实现的 Netfilter 框架如下。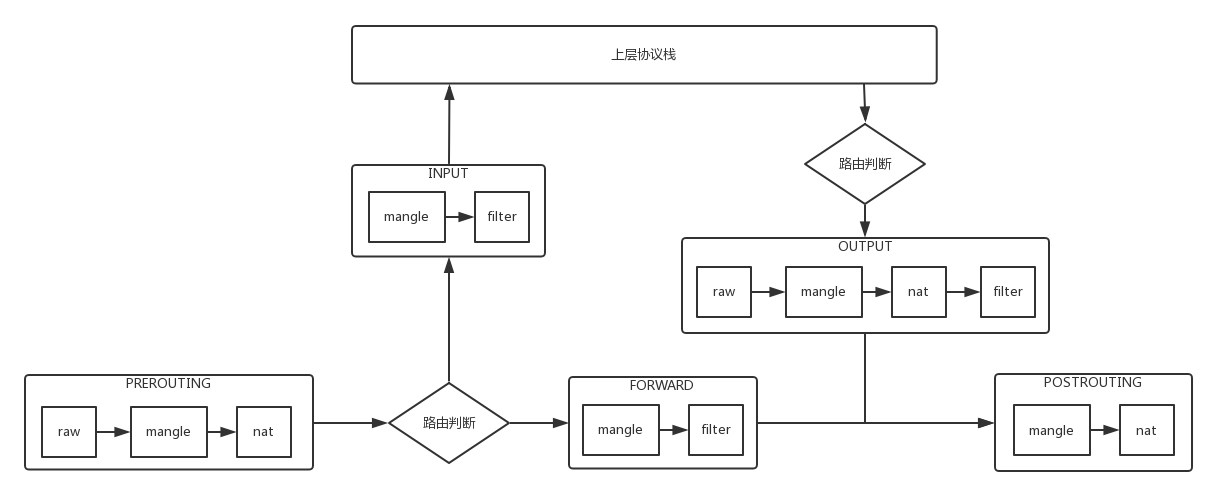
- 数据包进入的时候,先进 mangle 表的 PREROUTING 链。在这里可以根据需要,改变数据包头内容之后,进入 nat 表的 PREROUTING 链,在这里可以根据需要做 Dnat,也就是目标地址转换。
- 进入路由判断,要判断是进入本地的还是转发的。
- 进入本地
- 先进入 INPUT 链,之后按条件过滤限制进入。
- 之后进入本机,再进入 OUTPUT 链,按条件过滤限制出去,离开本地。
- 转发
- 就进入 FORWARD 链,根据条件过滤限制转发。
- 进入本地
- 之后进入 POSTROUTING 链,这里可以做 Snat,离开网络接口。
安全组
在云平台上,一般允许一个或者多个虚拟机属于某个安全组,而属于不同安全组的虚拟机之间的访问以及外网访问虚拟机,都需要通过安全组进行过滤。
举例,我们会创建一系列的网站,都是前端在 Tomcat 里面,对外开放 8080 端口。数据库使用 MySQL,开放 3306 端口。则可以按照下图配置安全组。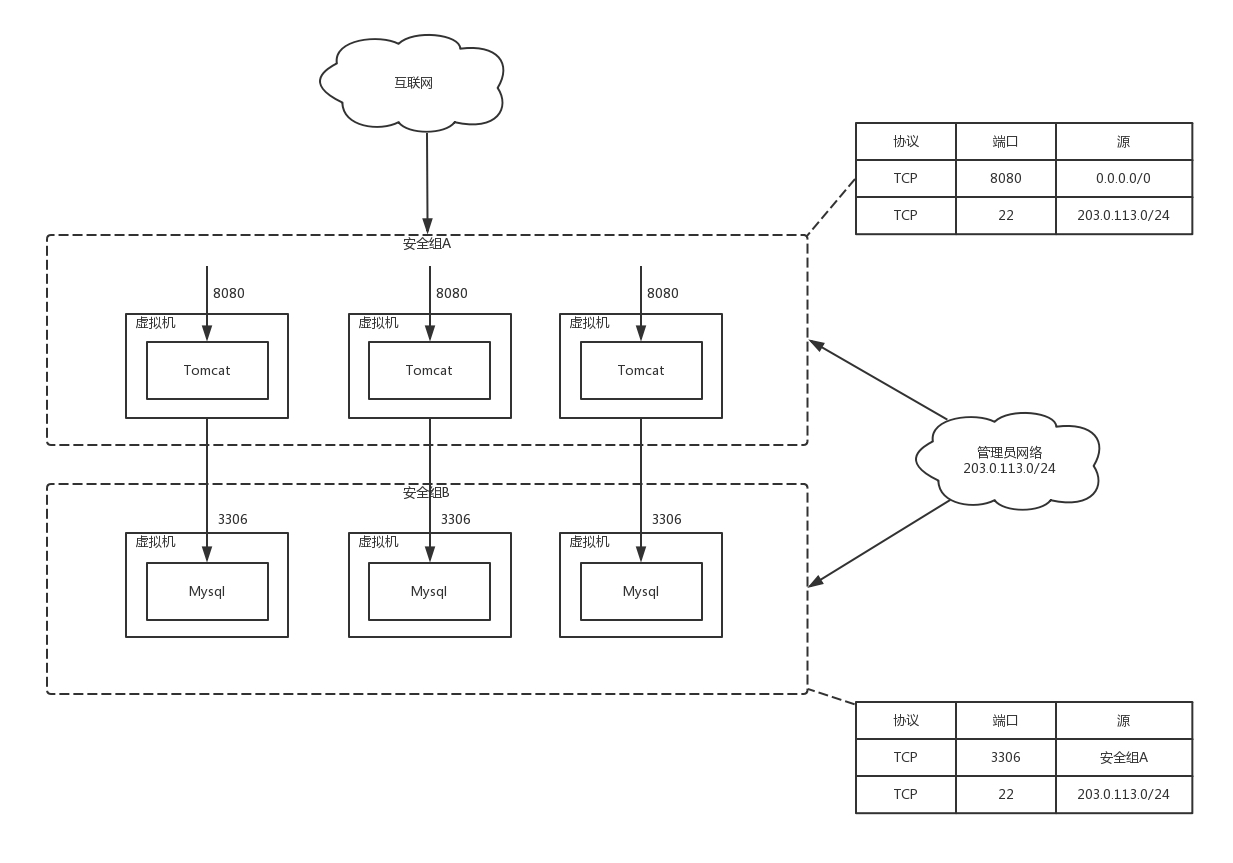
我们创建两个安全组
- 将 Tomcat 所在的虚拟机放在安全组 A 里面。在安全组 A 里面,允许任意 IP 地址 0.0.0.0/0 访问 8080 端口,但是对于 ssh 的 22 端口,仅仅允许管理员网段 203.0.113.0/24 访问。
- 我们将 MySQL 所在的虚拟机在安全组 B 里面。在安全组 B 里面,仅仅允许来自安全组 A 的机器访问 3306 端口,但是对于 ssh 的 22 端口,同样允许管理员网段 203.0.113.0/24 访问。
基于 iptables 的安全组的实现
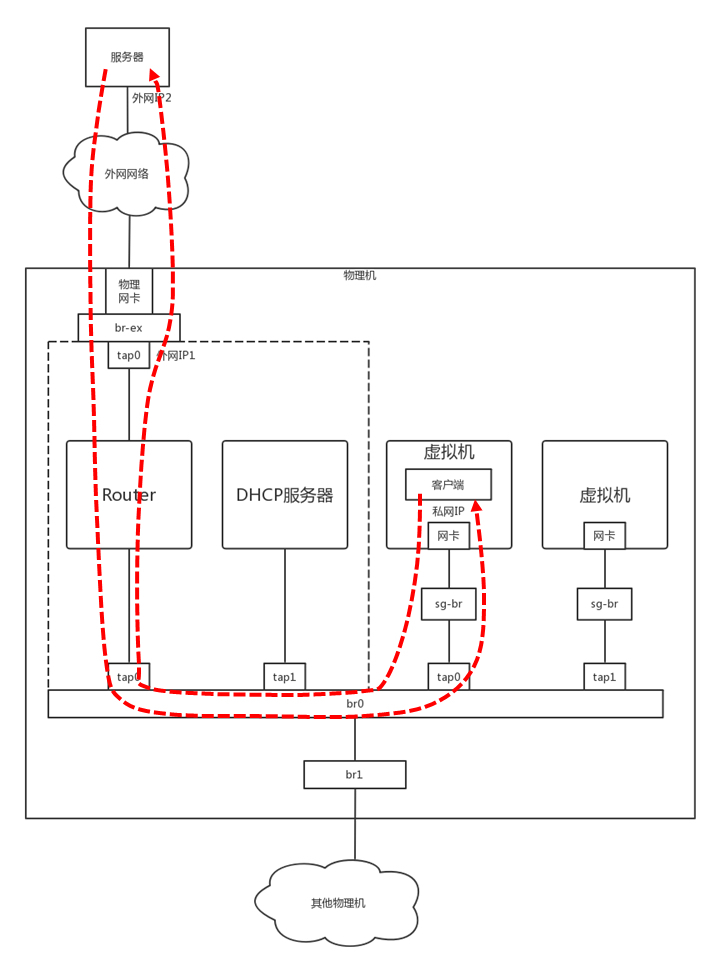
如上图,两个 VM 都通过 tap 网卡连接到一个网桥上,但是网桥是二层的,两个 VM 之间是可以随意互通的,因而需要有一个地方统一配置这些 iptables 规则。
- 可以多加一个网桥,在这个网桥上配置 iptables 规则,将在用户在界面上配置的规则,放到这个网桥上。
- 然后在每台机器上跑一个 Agent,将用户配置的安全组变成 iptables 规则,配置在这个网桥上。
基于 iptables 解决外网访问问题
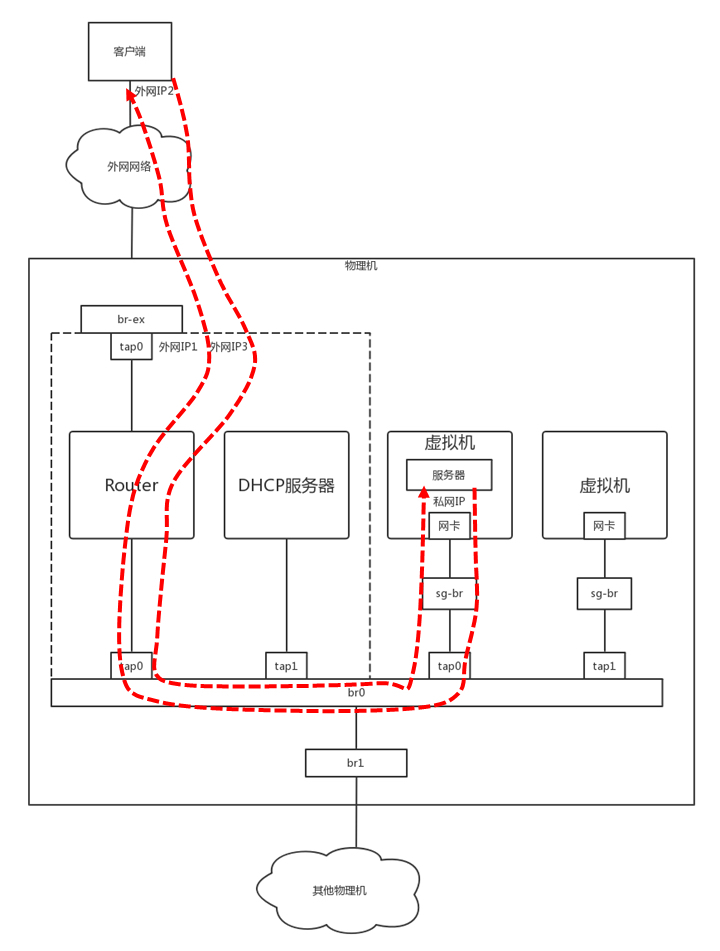
上图是虚拟机做客户端的场景,云平台里面的虚拟机只有私网 IP 地址,到达外网网口要做一次 Snat,转换成为机房网 IP,然后出数据中心的时候,再转换为公网 IP。
- 这里的 Snat 是一种特殊的 Snat,称为 MASQUERADE(地址伪装)。这种方式下,所有的虚拟机共享一个机房网和公网的 IP 地址,所有从外网网口出去的,都转换成为这个 IP 地址。
- Netfilter 的连接跟踪(conntrack)功能会用 “源 / 目的 IP+ 源 / 目的端口” 唯一标识一条连接,并将它放在 conntrack 表里面。当时是这台机器去请求网站的,虽然源地址已经 Snat 成公网 IP 地址了,但是 conntrack 表里面还是有这个连接的记录的。当网站返回数据的时候,会找到记录,从而找到正确的私网 IP 地址。
当虚拟机做服务端时,需要给这个网站配置固定的物理网的 IP 地址和公网 IP 地址。这时候就需要显示的配置 Snat 规则和 Dnat 规则了。
- 当外部访问进来的时候,外网网口会通过 Dnat 规则将公网 IP 地址转换为私网 IP 地址,到达虚拟机,虚拟机里面是网站。
- 返回结果时,外网网口会通过 Snat 规则,将私网 IP 地址转换为那个分配给它的固定的公网 IP 地址。
第27讲 | 云中的网络QoS:邻居疯狂下电影,我该怎么办?
在云平台上,有一种流量控制的技术,可以实现 QoS(Quality of Service),从而保障大多数用户的服务质量。
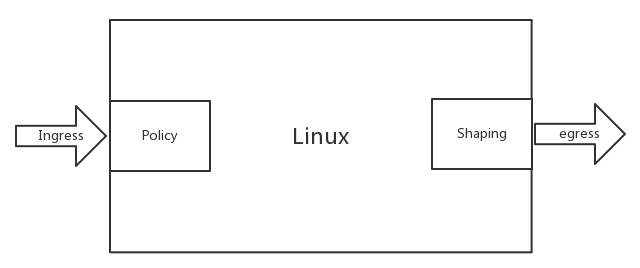
对于控制一台机器的网络的 QoS,分两个方向:
- 一个是入方向,流量无法控制,只能通过 Policy 将包丢弃。
- 一个是出方向,通过 Shaping,将出的流量控制成自己想要的模样。
控制网络的 QoS 有哪些方式?
在 Linux 下,可以通过 TC 控制网络的 QoS,主要就是通过队列的方式。
- 无类别排队规则
- pfifo_fast,这是一种不把网络包分类的技术
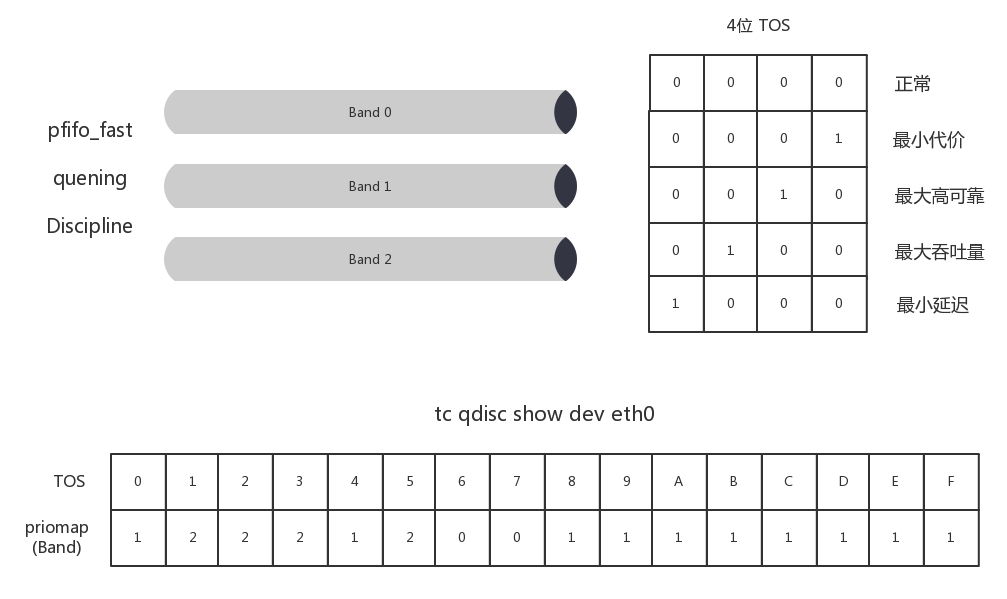
- pfifo_fast 分为三个先入先出的队列,称为三个 Band。优先级为 Band0,Band1,Band2。
- 根据网络包里面 TOS,看这个包到底应该进入哪个队列。TOS 总共四位,每一位表示的意思不同,总共十六种类型。
- 通过命令行 tc qdisc show dev eth0,可以输出结果 priomap,也是十六个数字。在 0 到 2 之间,和 TOS 的十六种类型对应起来,表示不同的 TOS 对应的不同的队列。
- 随机公平队列(Stochastic Fair Queuing)
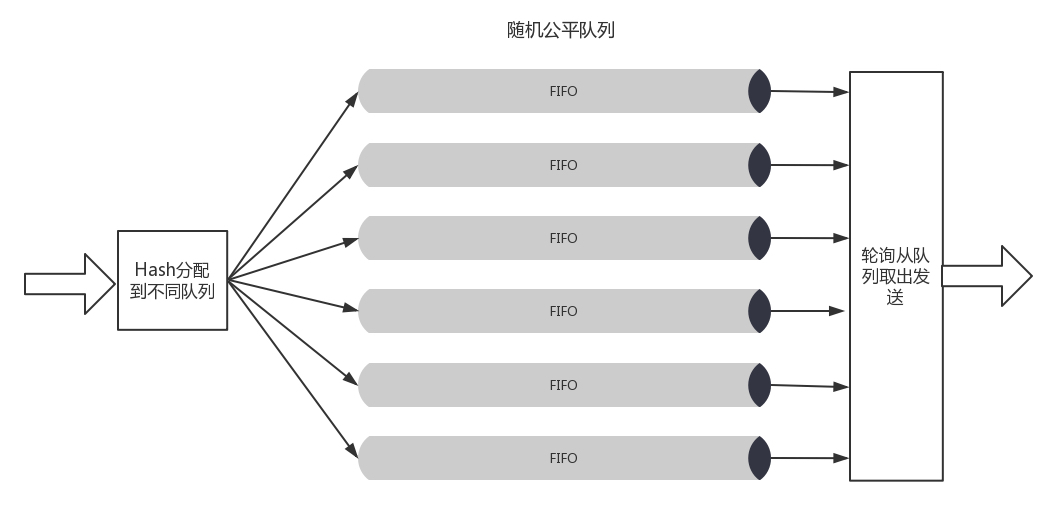
- 它会建立很多的 FIFO 的队列,TCP Session 会计算 hash 值,通过 hash 值分配到某个队列。
- 在队列的另一端,网络包会通过轮询策略从各个队列中取出发送。这样不会有一个 Session 占据所有的流量。
- 当然如果两个 Session 的 hash 是一样的,会共享一个队列,也有可能互相影响。hash 函数会经常改变,从而 session 不会总是相互影响。
- 令牌桶规则(TBF,Token Bucket Filte)
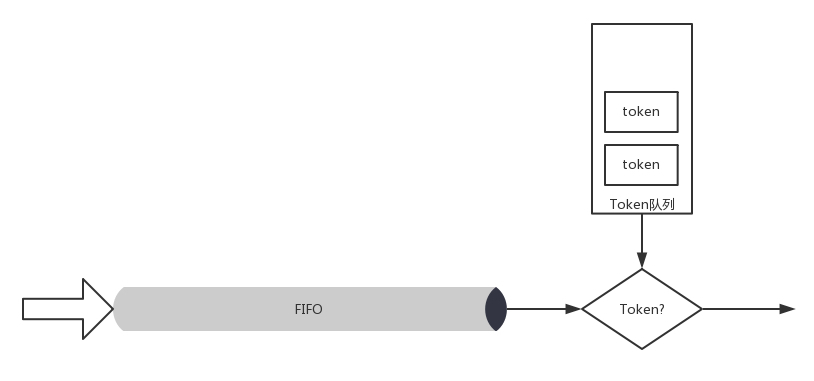
- 所有的网络包排成队列进行发送,但是需要拿到令牌才能发送。
- 令牌根据设定的速度生成,所以即便队列很长,也是按照一定的速度进行发送的。
- 当没有包在队列中的时候,令牌还是以既定的速度生成,但是不是无限累积的,而是放满了桶为止。
设置桶的大小为了避免下面的情况:当长时间没有网络包发送的时候,积累了大量的令牌,突然来了大量的网络包,每个都能得到令牌,造成瞬间流量大增。
- pfifo_fast,这是一种不把网络包分类的技术
- 基于类别的队列规则
- 分层令牌桶规则(HTB, Hierarchical Token Bucket)
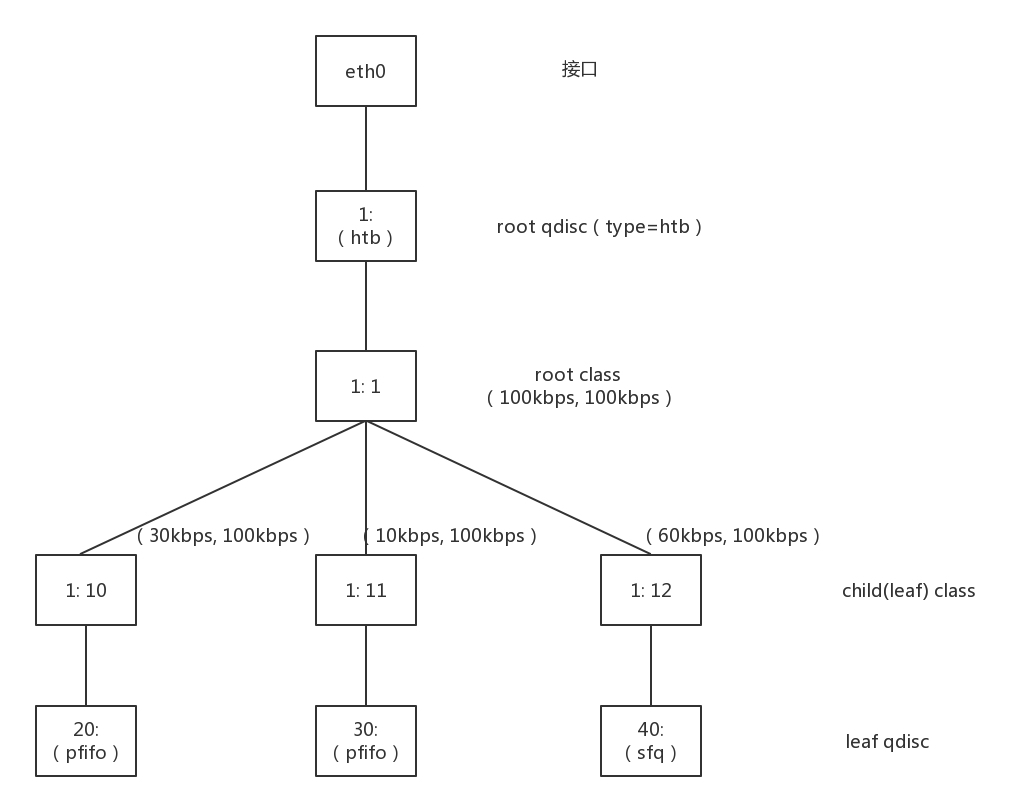
- HTB 往往是一棵树。使用 TC 可以为某个网卡 eth0 创建一个 HTB 的队列规则,需要付给它一个句柄为(1:),这是整棵树的根节点。接下来会有分支。例如图中有三个分支,句柄分别为(:10)、(:11)、(:12)。最后的参数 default 12,表示默认发送给 1:12,也即发送给第三个分支。
- 速度配置
- 类型
- rate,表示一般情况下的速度
- ceil,表示最高情况下的速度
- 效果
- 对于根节点来讲,这两个速度是一样的
- 对于子节点来讲,同一个根节点下的子节点可以相互借流量,从而不浪费带宽,使带宽发挥最大的作用
- 类型
- 子节点规则配置
- fifo
- sfq(随机公平队列)
参考上面的无类别排队规则
- 发送规则配置: 基于子节点规则,还可以设定发送规则。比如,从 1.2.3.4 来的,发送给 port 80 的包,从第一个分支 1:10 走;其他从 1.2.3.4 发送来的包从第二个分支 1:11 走;其他的走默认分支。
- 分层令牌桶规则(HTB, Hierarchical Token Bucket)
OpenvSwitch 中的 QoS
可以通过 OpenvSwitch 中 ovs-vsctl 与 ovs-ofctl 提供的相关指令进行配置,以实现OpenvSwitch 中的 QoS
第28讲 | 云中网络的隔离GRE、VXLAN:虽然住一个小区,也要保护隐私
VLAN 数量不够用怎么办?
- 一种方式是修改这个协议。但当协议形成一定标准后,设备上跑的程序都要按这个规则来,这样修改协议往往不可行。
- 另一种方式是扩展,在原来包的格式的基础上扩展出一个头,里面包含足够用于区分租户的 ID。
- 外层的包的格式尽量和传统的一样,依然兼容原来的格式。
- 在需要区分用户的地方,用特殊的程序,来处理特殊的包的格式。
GRE
GRE,全称 Generic Routing Encapsulation,它是一种 IP-over-IP 的隧道技术。它将 IP 包封装在 GRE 包里,外面加上 IP 头,在隧道的一端封装数据包,并在通路上进行传输,到另外一端的时候解封装。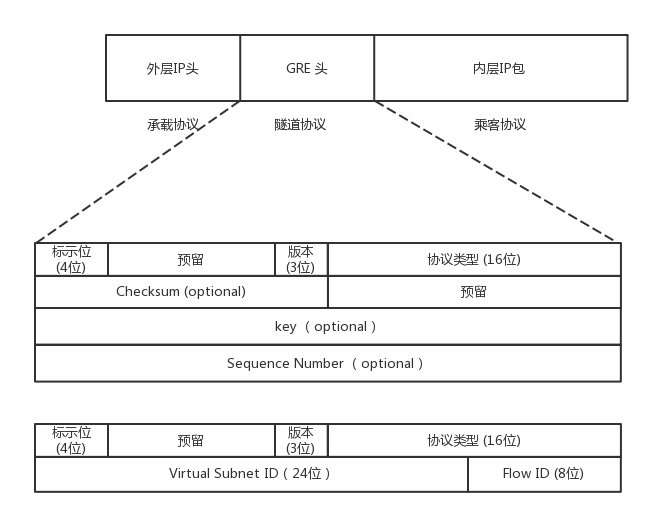
在一个 GRE 头中:
- 前 32 位是一定会有的,后面的都是可选的
- 前 4 位标识位里面,有标识后面到底有没有可选项
- key 字段是一个 32 位的字段,里面存放的往往就是用于区分用户的 32 位的 Tunnel ID
- 下面的格式类型专门用于网络虚拟化的 GRE 包头格式,称为NVGRE,给网络 ID 号 24 位。
GRE 还需要有一个地方来封装和解封装 GRE 的包,这个地方往往是路由器或者有路由功能的 Linux 机器。
使用 GRE 隧道,传输的过程就像下面这张图。这里面有两个网段、两个路由器,中间要通过 GRE 隧道进行通信。当隧道建立之后,会多出两个 Tunnel 端口,用于封包、解封包。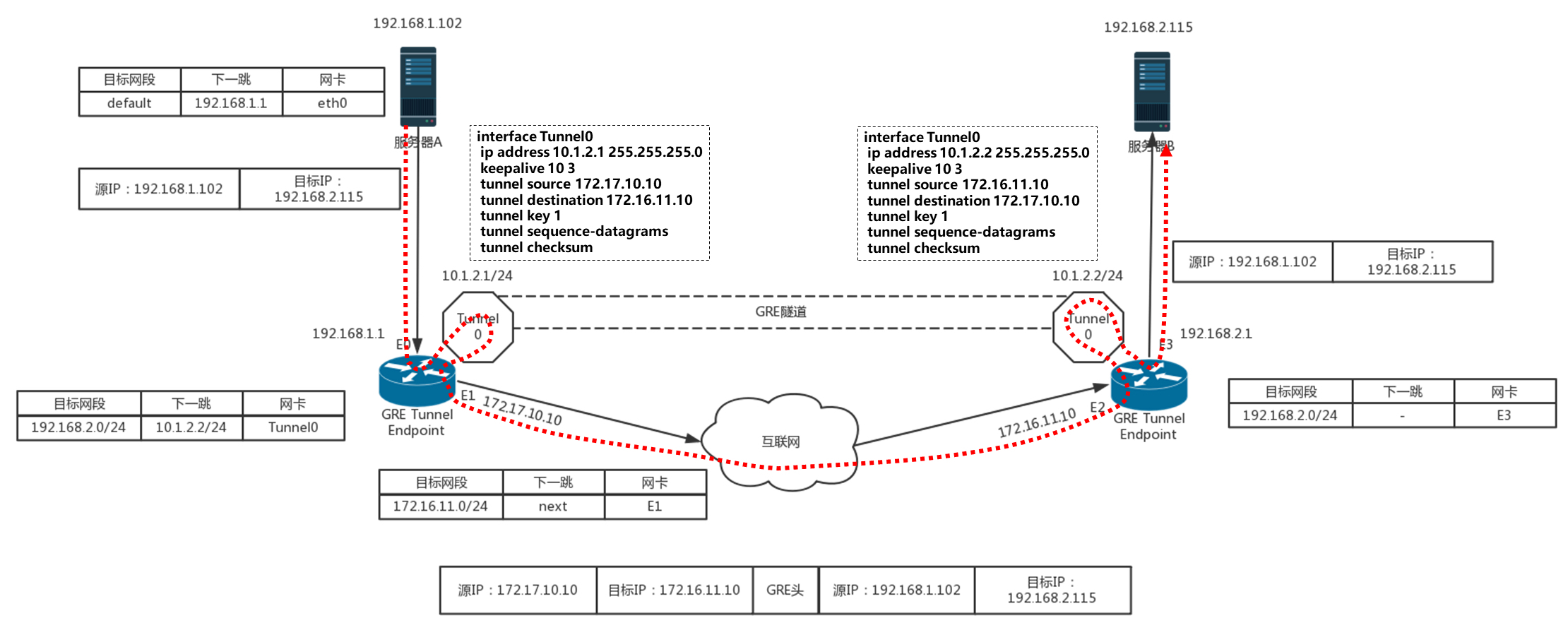
- 主机 A 在左边的网络,IP 地址为 192.168.1.102,主机 B 在右边的网络,IP 地址为 192.168.2.115。A 发送一个包至 B,源地址为 192.168.1.102,目标地址为 192.168.2.115。
- 因为要跨网段访问,于是根据默认的 default 路由表规则,要发给默认的网关 192.168.1.1,也即左边的路由器。
- 根据路由表,从左边的路由器,去 192.168.2.0/24 这个网段,应该走一条 GRE 的隧道,从隧道一端的网卡 Tunnel0 进入隧道。
- 在 Tunnel 隧道的端点进行包的封装,在内部的 IP 头之外加上 GRE 头,然后从 E1 的物理网卡发送到公共网络里。
- 对于 NVGRE 来讲,是在 MAC 头之外加上 GRE 头,然后加上外部的 IP 地址,也即路由器的外网 IP 地址。源 IP 地址为 172.17.10.10,目标 IP 地址为 172.16.11.10。
- 在公共网络里面,沿着路由器一跳一跳地走,全部都按照外部的公网 IP 地址进行。
- 当网络包到达对端路由器的时候,也要到达对端的 Tunnel0,然后开始解封装,将外层的 IP 头取下来,然后根据里面的网络包,根据路由表,从 E3 口转发出去到达服务器 B。
GRE 的弊端
- Tunnel 的数量问题。GRE 是一种点对点隧道,如果有三个网络,就需要在每两个网络之间建立一个隧道。如果网络数目增多,这样隧道的数目会呈指数性增长。
- GRE 不支持组播。一个网络中的一个虚机发出一个广播帧后,GRE 会将其广播到所有与该节点有隧道连接的节点。
- 实用性问题。目前还是有很多防火墙和三层网络设备无法解析 GRE,因此它们无法对 GRE 封装包做合适地过滤和负载均衡。
VXLAN
VXLAN 是在二层外面套了一个 VXLAN 的头。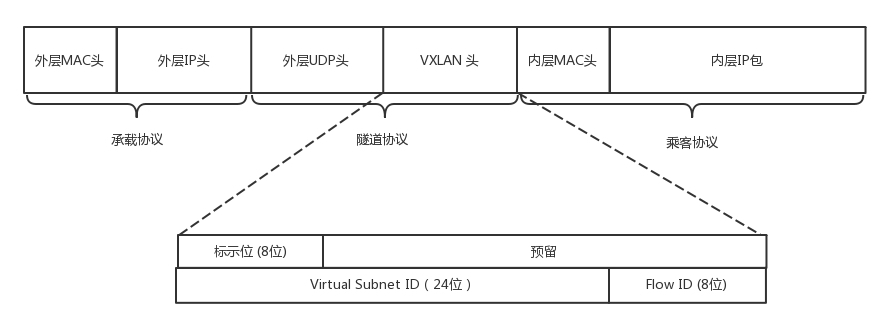
- VXLAN ID 为 24 位。
- 在 VXLAN 头外面还封装了 UDP、IP,以及外层的 MAC 头。
与 GRE 对比,GRE 是三层外面再套三层,VXLAN 是二层外面套二层。
VXLAN 作为扩展性协议,也需要一个地方对 VXLAN 的包进行封装和解封装,实现这个功能的点称为VTEP(VXLAN Tunnel Endpoint)。
- 每台物理机上都可以有一个 VTEP。
- 每个虚拟机启动的时候,都需要向这个 VTEP 注册,每个 VTEP 都知道自己上面注册了多少个虚拟机。
- 当虚拟机要跨 VTEP 进行通信的时候,需要通过 VTEP 代理进行,由 VTEP 进行包的封装和解封装。
- VXLAN 支持通过组播的来定位目标机器。当一个 VTEP 启动的时候,它们都需要通过 IGMP 协议,加入一个组播组。就像加入一个邮件列表,所有发到这个邮件列表里面的邮件,大家都能收到。
如图,虚拟机 1、2、3 属于云中同一个用户的虚拟机,因而需要分配相同的 VXLAN ID=101。在云的界面上,就可以知道它们的 IP 地址。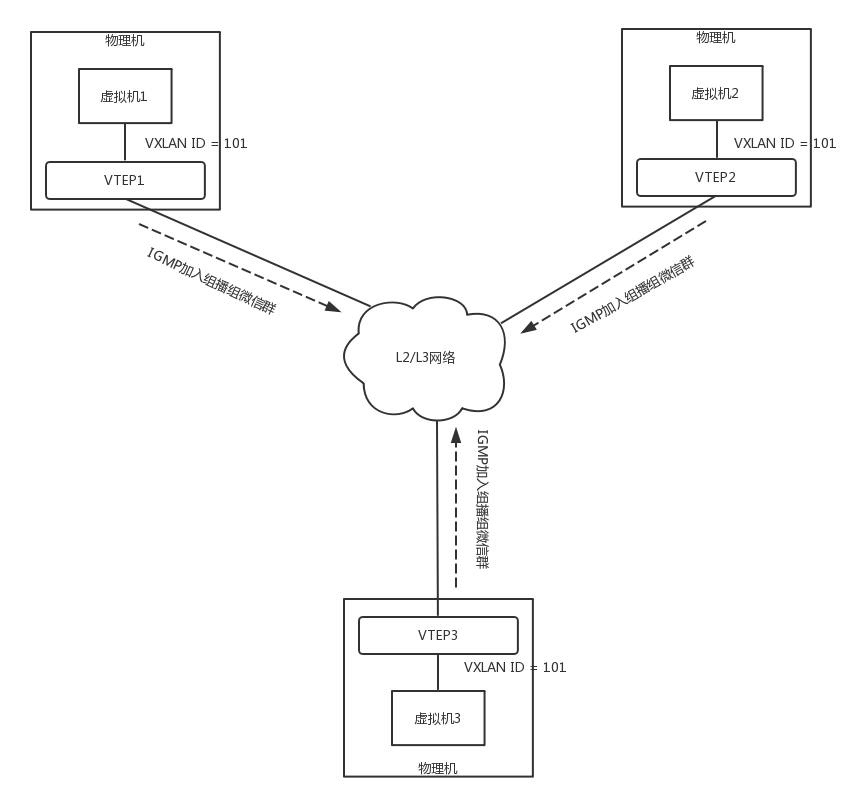
这里以在虚拟机 1 上 ping 虚拟机 2 举例
- 虚拟机 1 发现,它不知道虚拟机 2 的 MAC 地址,因而包没办法发出去,于是要发送 ARP 广播。
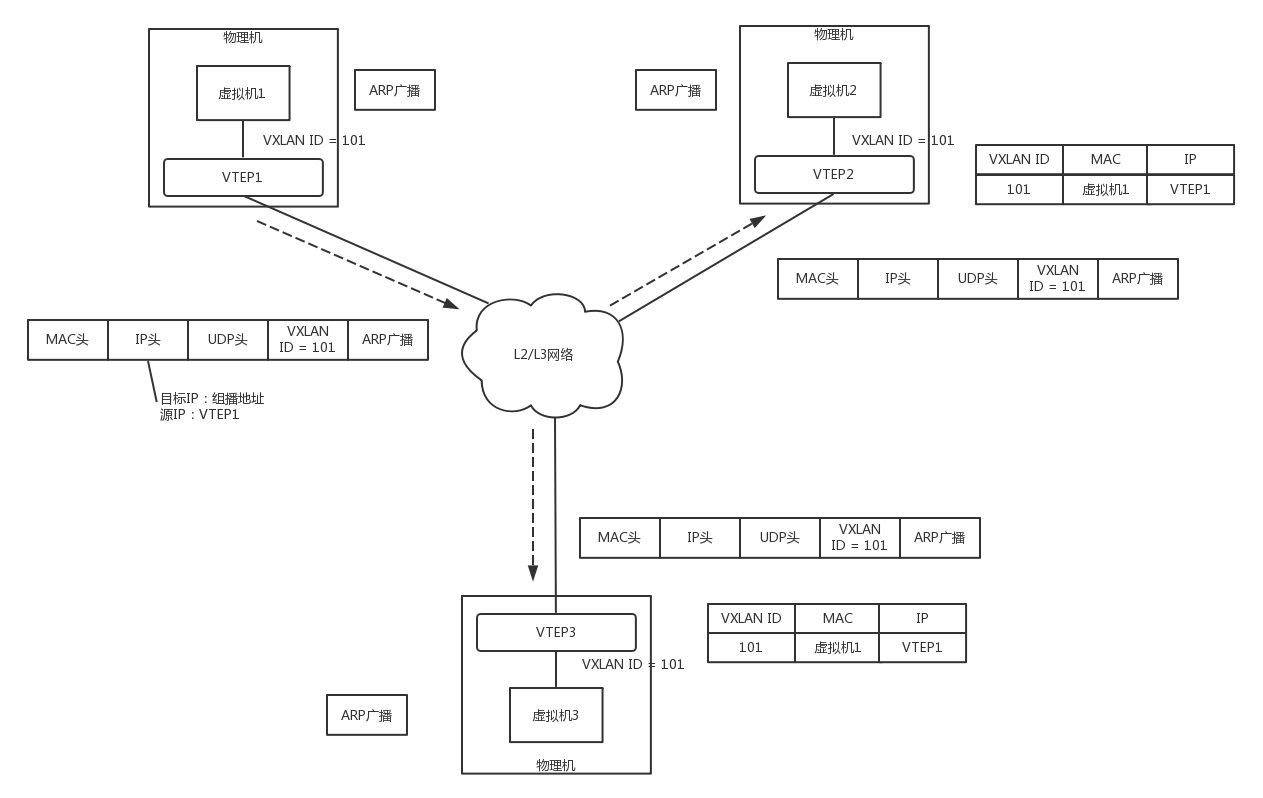
- ARP 请求到达 VTEP1 的时候,VTEP1 知道,我这里有一台虚拟机,要访问一台不归我管的虚拟机,需要知道 MAC 地址,于是 VTEP1 将 ARP 请求封装在 VXLAN 里面,组播出去。
- VTEP2 和 VTEP3 都收到了消息,因而都会解开 VXLAN 包看,里面是一个 ARP。
- VTEP3 在本地广播后,没有收到回复。
- VTEP2 在本地广播后,虚拟机 2 回了,说虚拟机 2 归我管,MAC 地址是这个。
通过这次通信,VTEP2 也学到了,虚拟机 1 归 VTEP1 管,以后要找虚拟机 1,去找 VTEP1 就可以了。
- VTEP2 将 ARP 的回复封装在 VXLAN 里面,直接发回给 VTEP1。
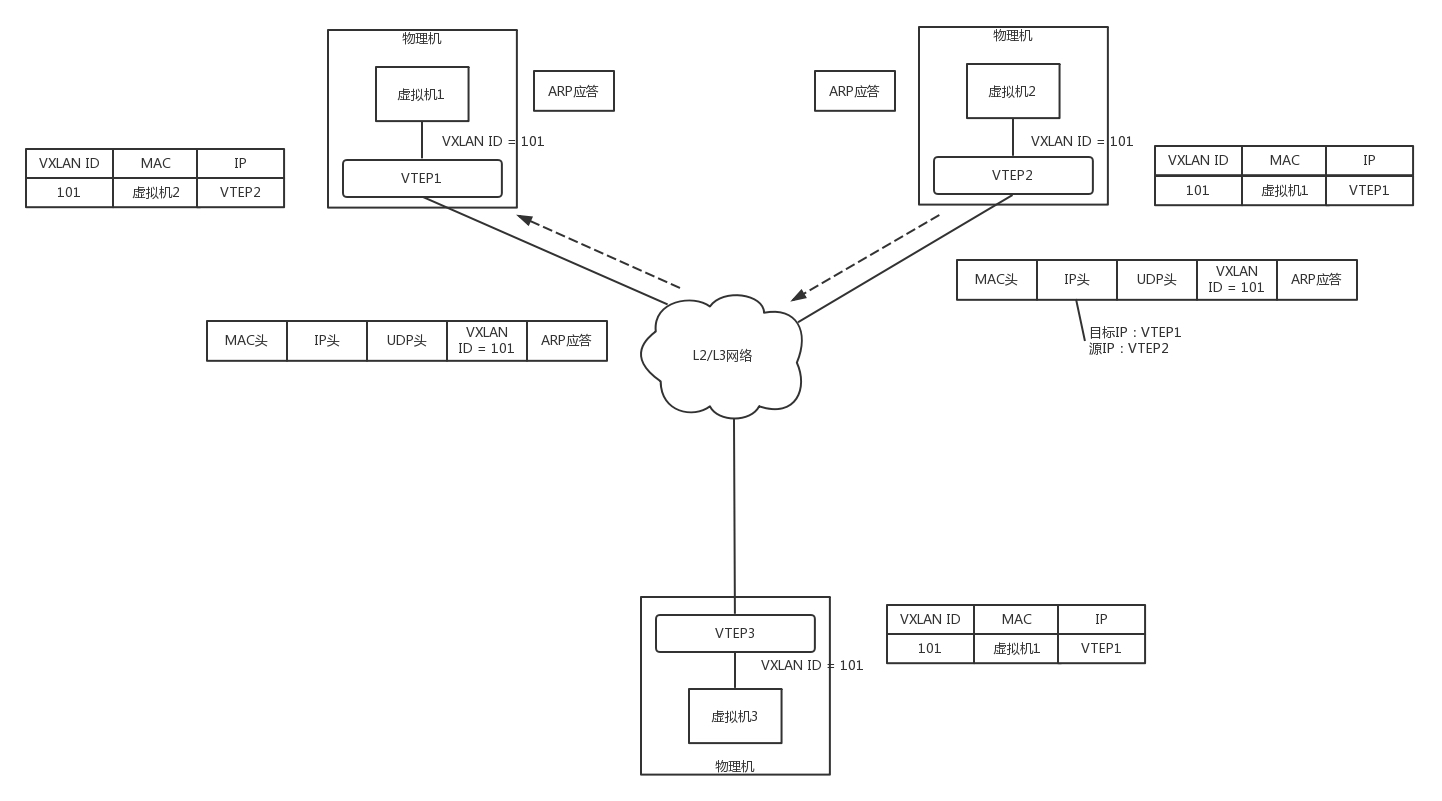
- VTEP1 解开 VXLAN 的包,发现是 ARP 的回复,于是发给虚拟机 1。
通过这次通信,VTEP1 也学到了,虚拟机 2 归 VTEP2 管,以后找虚拟机 2,去找 VTEP2 就可以了。
- 虚拟机 1 的 ARP 得到了回复,知道了虚拟机 2 的 MAC 地址,于是就可以发送包了。
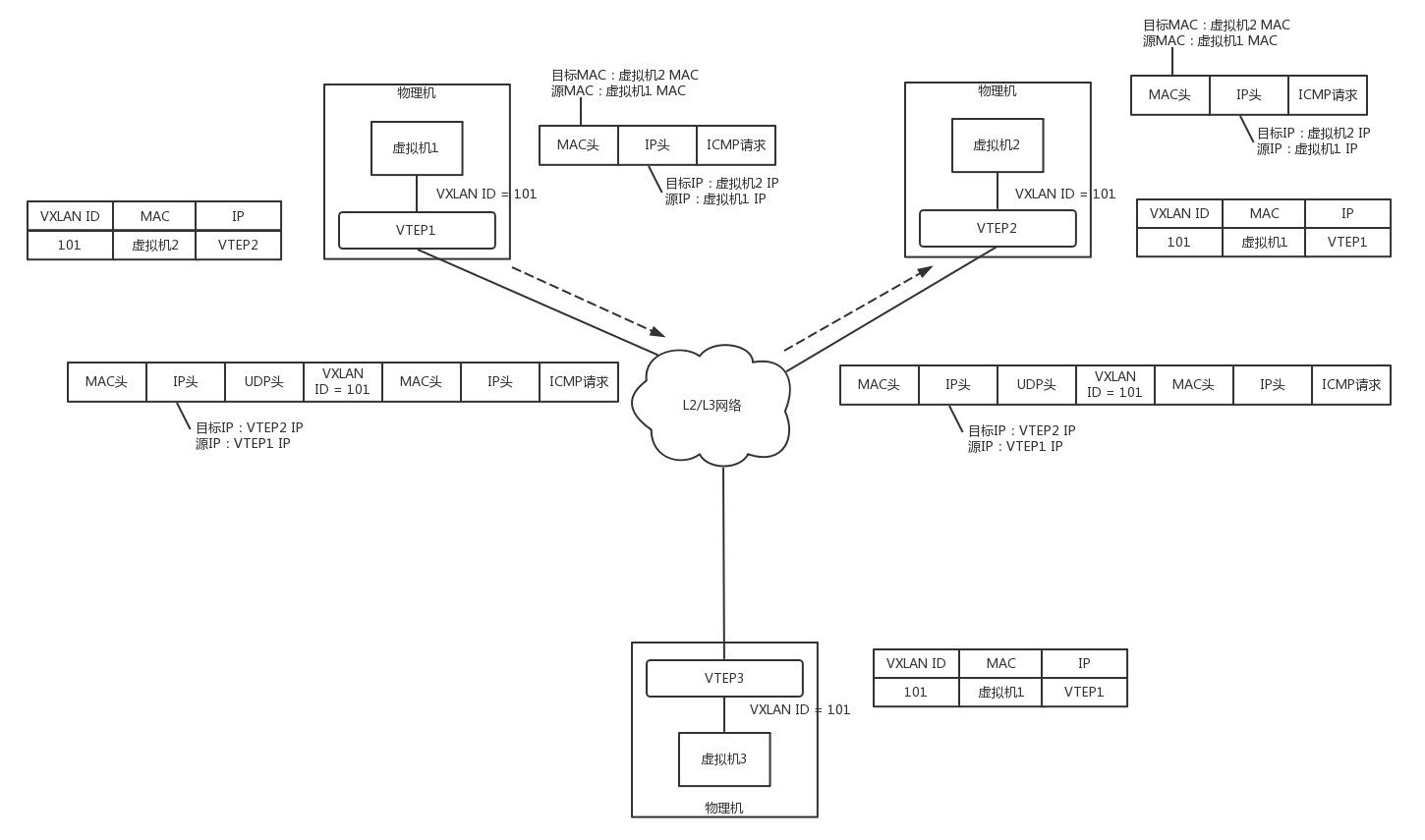
- 虚拟机 1 发给虚拟机 2 的包到达 VTEP1,它在上次通信中已经学习到虚拟机 2 在 VTEP2 组中,于是将包封装在 VXLAN 里面,外层加上 VTEP1 和 VTEP2 的 IP 地址,发送出去。
- 网络包到达 VTEP2 之后,VTEP2 解开 VXLAN 封装,将包转发给虚拟机 2。
- 虚拟机 2 回复的包,到达 VTEP2 的时候,它在上次通信中已经学习到虚拟机 1 在 VTEP1 组中,于是将包封装在 VXLAN 里面,外层加上 VTEP1 和 VTEP2 的 IP 地址,也发送出去。
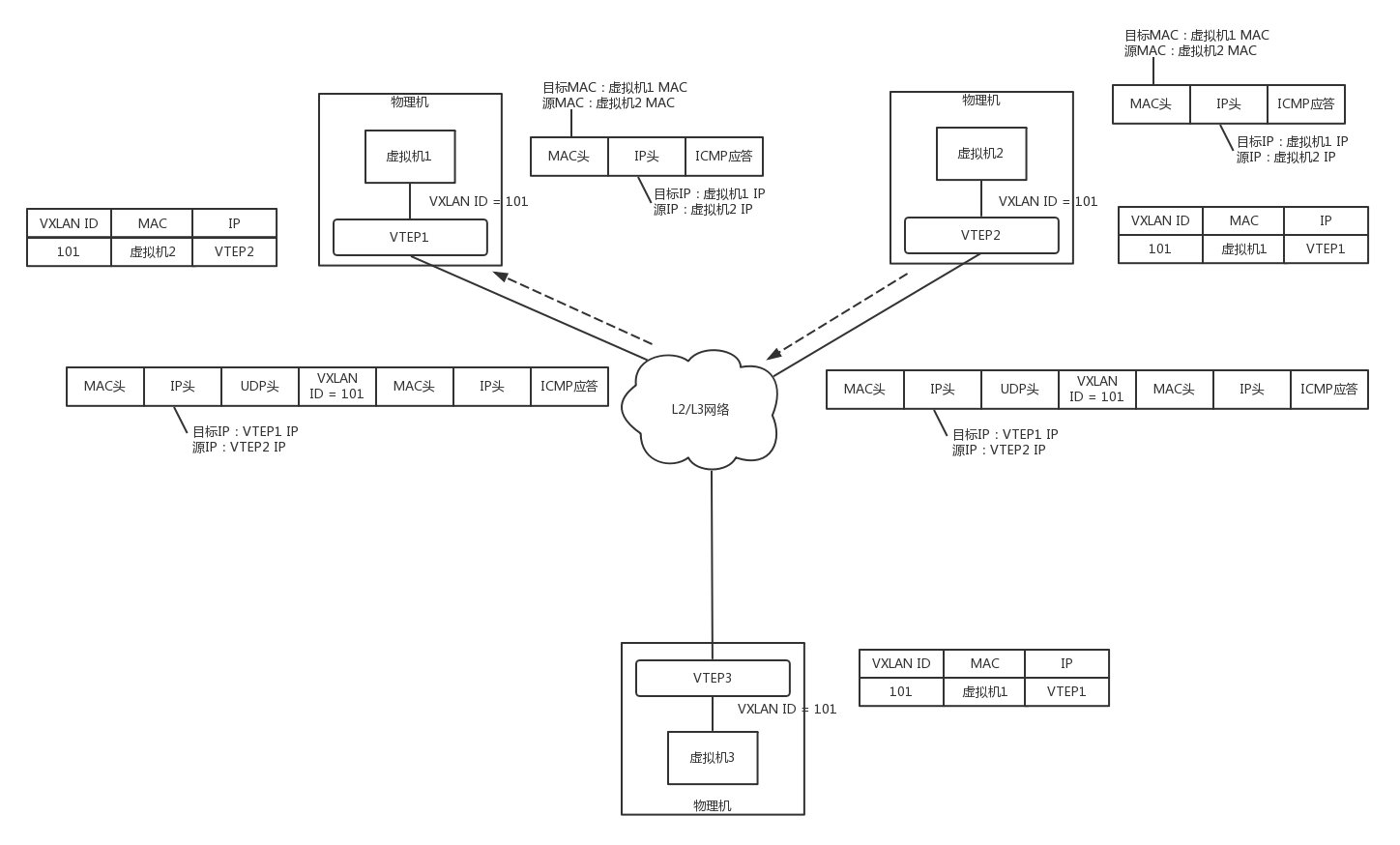
- 网络包到达 VTEP1 之后,VTEP1 解开 VXLAN 封装,将包转发给虚拟机 1。
和 GRE 端到端的隧道不同,VXLAN 不是点对点的,而是支持通过组播的来定位目标机器的,而非一定是这一端发出,另一端接收。
OpenvSwitch 中的隧道
OpenvSwitch 支持三类隧道:
- GRE
- VXLAN
- IPsec_GRE
在使用 OpenvSwitch 的时候,虚拟交换机就相当于 GRE 和 VXLAN 封装的端点。
第29讲 | 容器网络:来去自由的日子,不买公寓去合租
容器的思想就是要变成软件交付的集装箱。它有两个特点:
- 打包
- 标准
实现容器的两种主要技术
- 命名空间(namespace)。这是一种看起来是隔离的技术,也即每个 namespace 中的应用看到的是不同的 IP 地址、用户空间、程号等。
- Linux 上允许将进程放在独立的 namespace 里面,这样就可以独立配置网络了。
- 网络的 namespace 由 ip netns 命令操作。它可以创建、删除、查询 namespace。
- 机制网络(cgroup)。这是一种用起来是隔离的技术,也即明明整台机器有很多的 CPU、内存,而一个应用只能用其中的一部分。cgroup 有很多子系统:
- CPU 子系统使用调度程序为进程控制 CPU 的访问
- cpuset,如果是多核心的 CPU,这个子系统会为进程分配单独的 CPU 和内存
- memory 子系统,设置进程的内存限制以及产生内存资源报告
- blkio 子系统,设置限制每个块设备的输入输出控制
- net_cls,这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包
容器网络内部如何实现互通
如果你使用 docker run 运行一个容器,你应该能看到这样一个拓扑结构。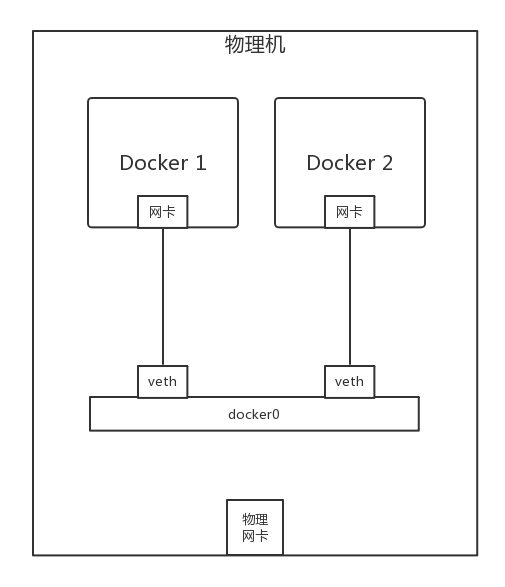
- 在 Linux 下,可以创建一对 veth pair 的网卡,从一边发送包,另一边就能收到。
- 一张网卡绑定至容器(通过 namespace)
- 另一张网卡连接至网桥
- 网桥实现了两边网卡的互通,即容器的互通
容器网络中如何融入物理网络?
Docker 支持桥接模式和 NAT 模式,默认使用 NAT 模式。NAT 模式分为 SNAT 和 DNAT,如果是容器内部访问外部,就需要通过 SNAT。
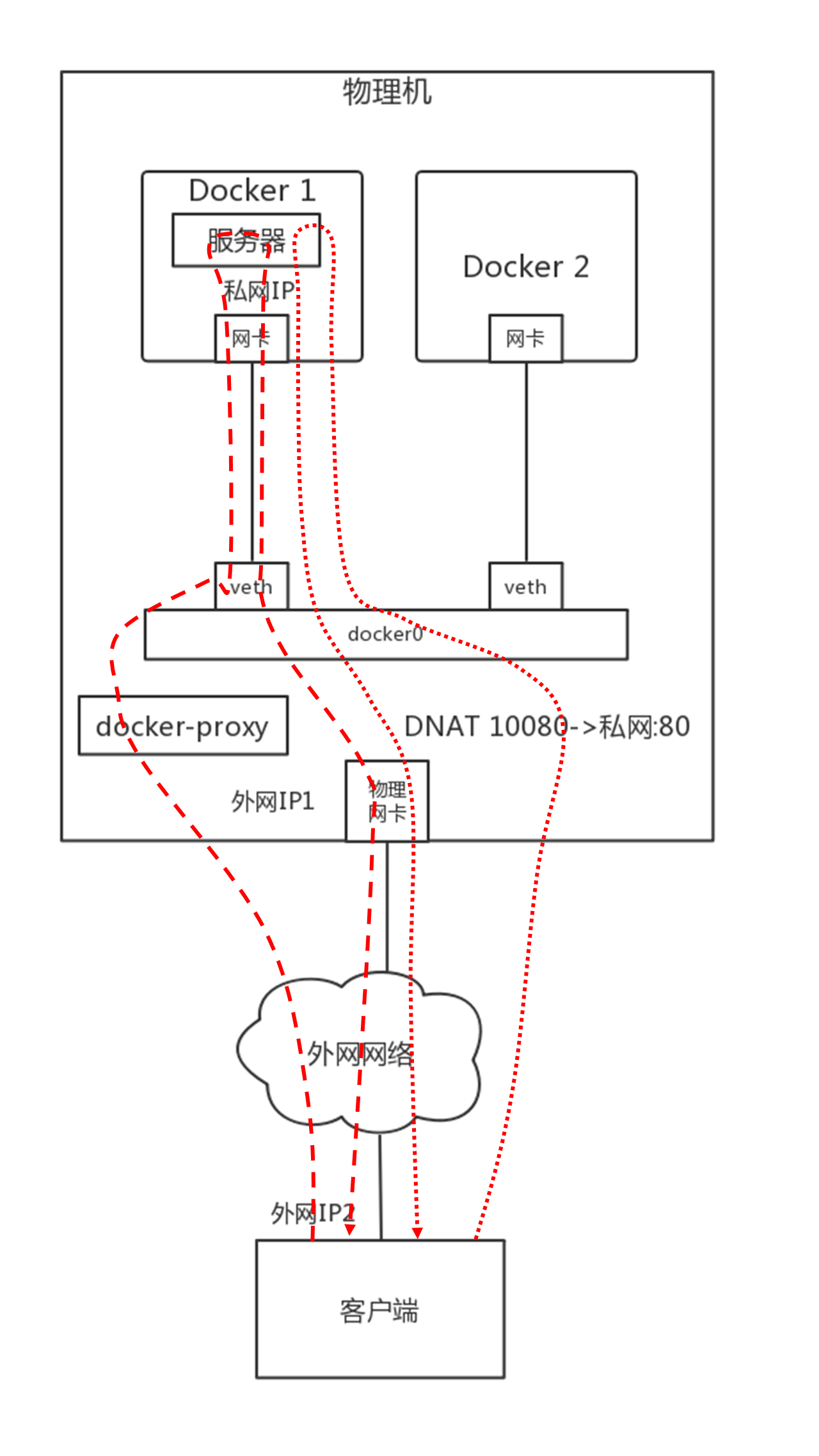
- 所有从容器内部发出来的包,都要做地址伪装,将源 IP 地址,转换为物理网卡的 IP 地址。如果有多个容器,所有的容器共享一个外网的 IP 地址,但是在 conntrack 表中,记录下这个出去的连接。
- 当服务器返回结果的时候,到达物理机,会根据 conntrack 表中的规则,取出原来的私网 IP,通过 DNAT 将地址转换为私网 IP 地址,通过网桥 docker0 实现对内的访问。
- 如果在容器内部属于一个服务,例如部署一个网站,提供给外部进行访问,需要通过 Docker 的端口映射技术,将容器内部的端口映射到物理机上来。Docker 支持两种端口映射的方式:
- 通过一个进程docker-proxy的方式,监听 10080,转换为 80 端口。
- 通过DNAT方式,在 -A PREROUTING 阶段加一个规则,将到端口 10080 的 DNAT 称为容器的私有网络。
第30讲 | 容器网络之Flannel:每人一亩三分地
Kubernetes 可以灵活地将一个容器调度到任何一台机器上,并且当某个应用扛不住的时候,只要在 Kubernetes 上修改容器的副本数,一个应用马上就能变八个,而且都能提供服务。
Kubernetes 要解决的两个问题:
- 各应用之间如何知道对方的位置
- 有一个被称为注册中心的地方可以统一管理应用。当一个应用启动时,将自己所在环境的 IPp 和端口,注册到注册中心。当应用挂了,容器要迁移到另一台机器时,会重新启动,也会重新注册。各个应用之间互相访问时,能够从注册中心得到其位置。
- 各应用之间如何通信
- Flannel 是一种解决方案
Kubernetes 平台只提出说网络模型要变平,但是没说怎么实现,因此业界涌现了大量的方案。
- Flannel 是一种解决方案
Flannel 解决的两个问题
- IP 冲突问题
- 从大网段中分出一个个小网段,每一台物理机使用一个网段。
例如物理机 A 是网段 172.17.8.0/24,物理机 B 是网段 172.17.9.0/24,这样两台机器上启动的容器 IP 肯定不一样,而且就看 IP 地址,我们就一下子识别出,这个容器是本机的,还是远程的,如果是远程的,也能从网段一下子就识别出它归哪台物理机管。
- 从大网段中分出一个个小网段,每一台物理机使用一个网段。
- 两台物理机上的容器应用跨物理机互通的问题
- 方案1: Flannel 使用 UDP 实现 Overlay 网络的方案,在每台物理机上,都会跑一个 flanneld 进程,这个进程打开一个 /dev/net/tun 字符设备的时候,就出现了一个网卡 flannel.1,由这张网卡实现路由策略。
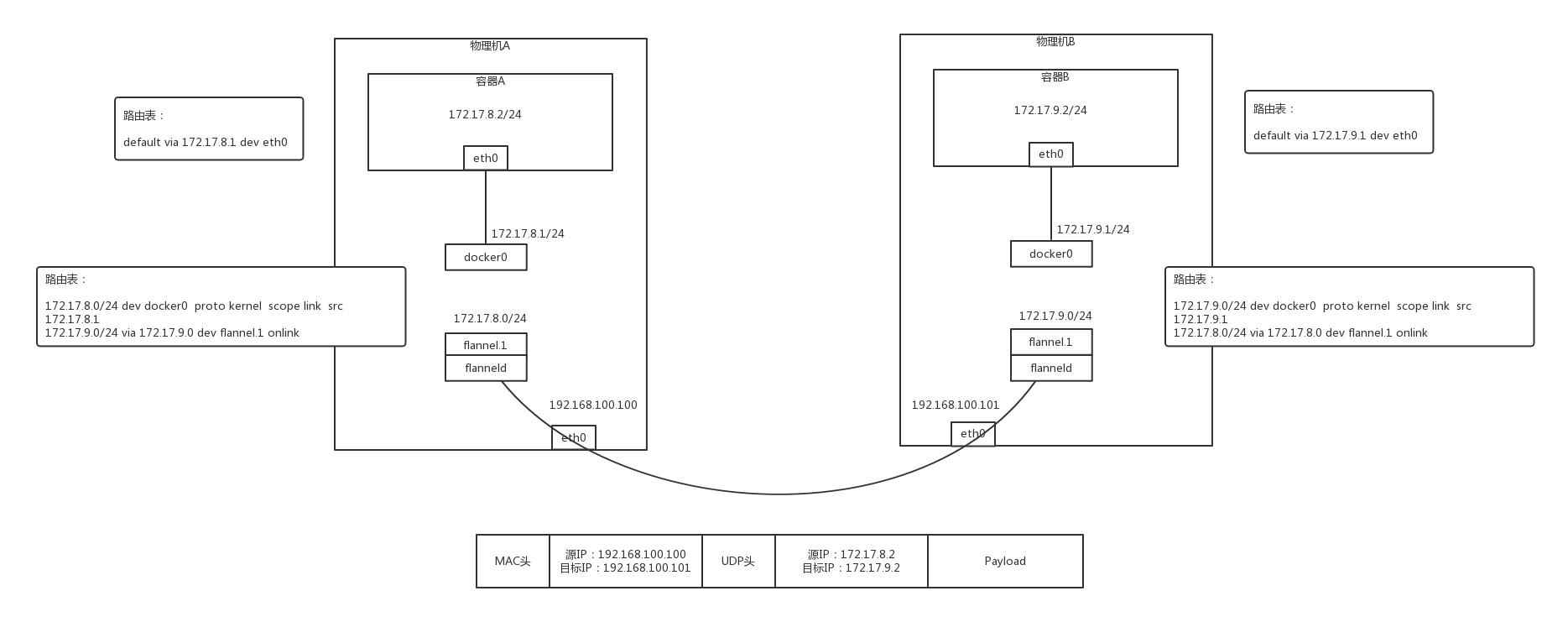
- 在物理机 A 上的容器 A 里面,能看到的容器的 IP 地址是 172.17.8.2/24,里面设置了默认的路由规则 default via 172.17.8.1 dev eth0。
- 如果容器 A 要访问 172.17.9.2,就会发往这个默认的网关 172.17.8.1。172.17.8.1 就是物理机上面 docker0 网桥的 IP 地址,这台物理机上的所有容器都是连接到这个网桥的。
- 在物理机上面,查看路由策略,会有这样一条 172.17.0.0/24 via 172.17.0.0 dev flannel.1,也就是说发往 172.17.9.2 的网络包会被转发到 flannel.1 这个网卡。
- 物理机 A 上的 flanneld 进程会将网络包封装在 UDP 包里面,然后外层加上物理机 A 和物理机 B 的 IP 地址,发送给物理机 B 上的 flanneld 进程。
为什么是 UDP 呢?因为不想在 flanneld 之间建立两两连接,而 UDP 没有连接的概念,任何一台机器都能发给另一台。
- 物理机 B 上的 flanneld 收到包之后,解开 UDP 的包,将里面的网络包拿出来,从物理机 B 的 flannel.1 网卡发出去。
- 在物理机 B 上,有路由规则 172.17.9.0/24 dev docker0 proto kernel scope link src 172.17.9.1。
- 将包发给 docker0,docker0 将包转给容器 B。通信成功。
上面的过程全部在用户态,所以性能差了一些。
- 方案2: 使用 Flannel + VXLAN,可以通过 netlink 通知内核建立一个 VTEP 的网卡 flannel.1。
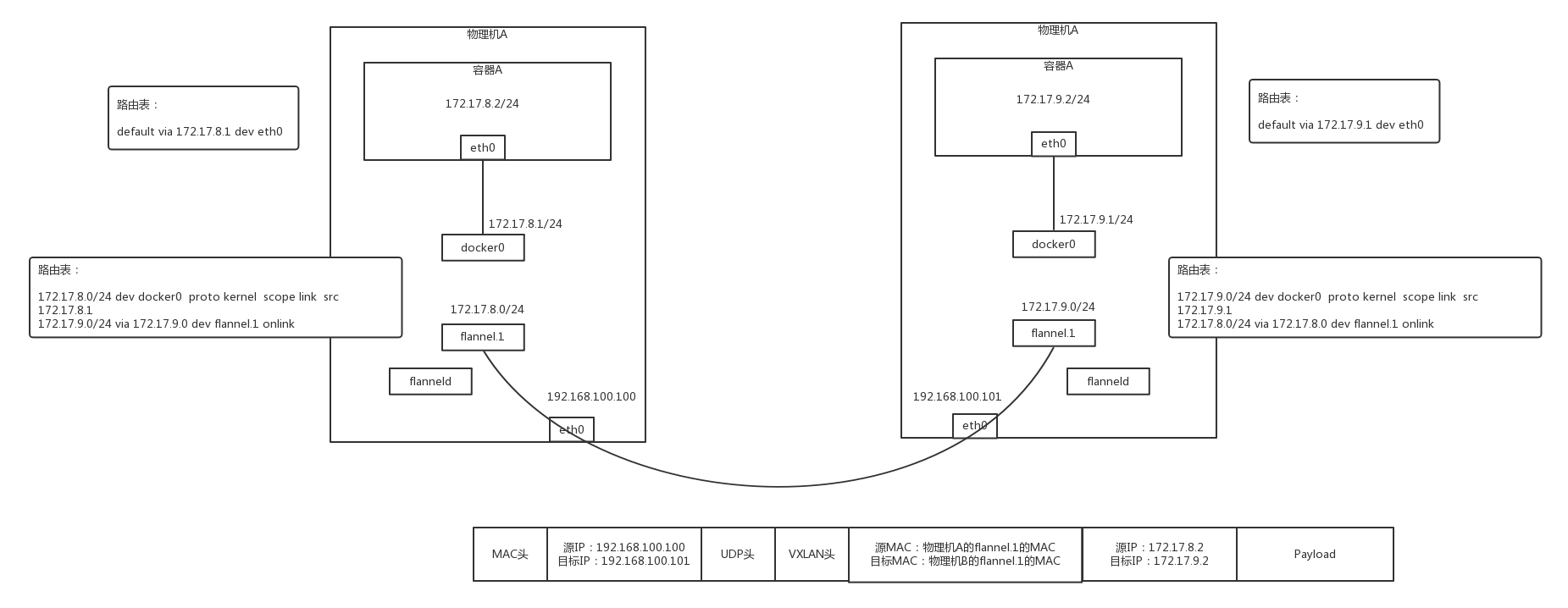
- 当网络包从物理机 A 上的容器 A 发送给物理机 B 上的容器 B,在容器 A 里面通过默认路由到达物理机 A 上的 docker0 网卡,然后根据路由规则,在物理机 A 上,将包转发给 flannel.1。
- flannel.1 是一个 VXLAN 的 VTEP,它将网络包进行封装。
- 内部的 MAC 地址这样写:源为物理机 A 的 flannel.1 的 MAC 地址,目标为物理机 B 的 flannel.1 的 MAC 地址,在外面加上 VXLAN 的头。
- 外层的 IP 地址这样写:源为物理机 A 的 IP 地址,目标为物理机 B 的 IP 地址,外面加上物理机的 MAC 地址。
- 这样就能通过 VXLAN 将包转发到另一台机器,从物理机 B 的 flannel.1 上解包,变成内部的网络包,通过物理机 B 上的路由转发到 docker0,然后转发到容器 B 里面。通信成功。
- 方案1: Flannel 使用 UDP 实现 Overlay 网络的方案,在每台物理机上,都会跑一个 flanneld 进程,这个进程打开一个 /dev/net/tun 字符设备的时候,就出现了一个网卡 flannel.1,由这张网卡实现路由策略。
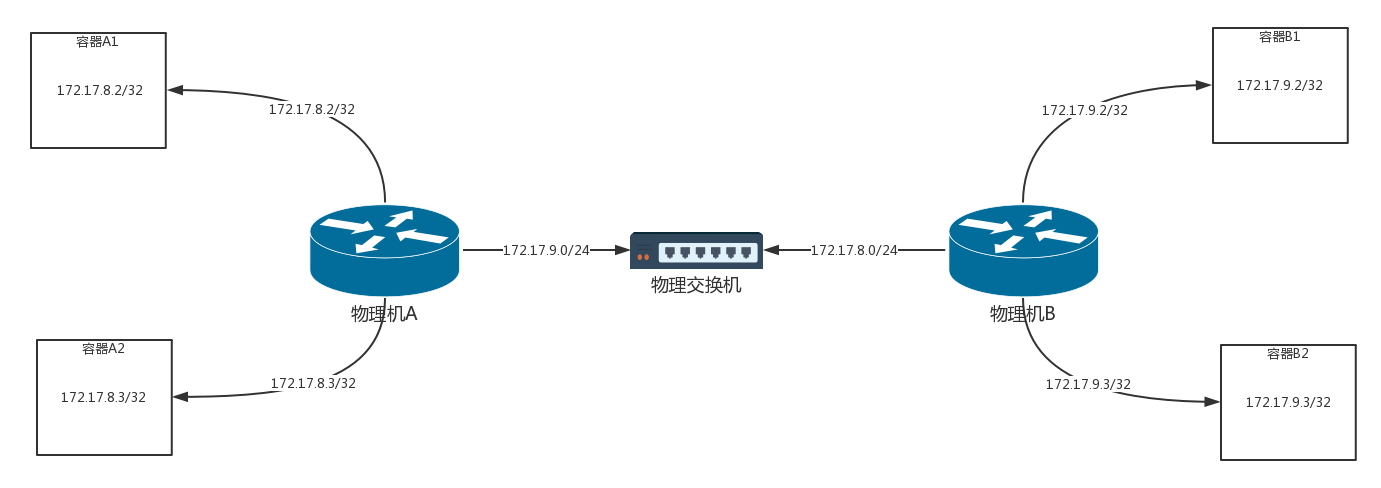
第31讲 | 容器网络之Calico:为高效说出善意的谎言
Calico 网络的大概思路,即不走 Overlay 网络,不引入另外的网络性能损耗,而是将转发全部用三层网络的路由转发来实现。
Calico 网络的转发细节
以下图为例。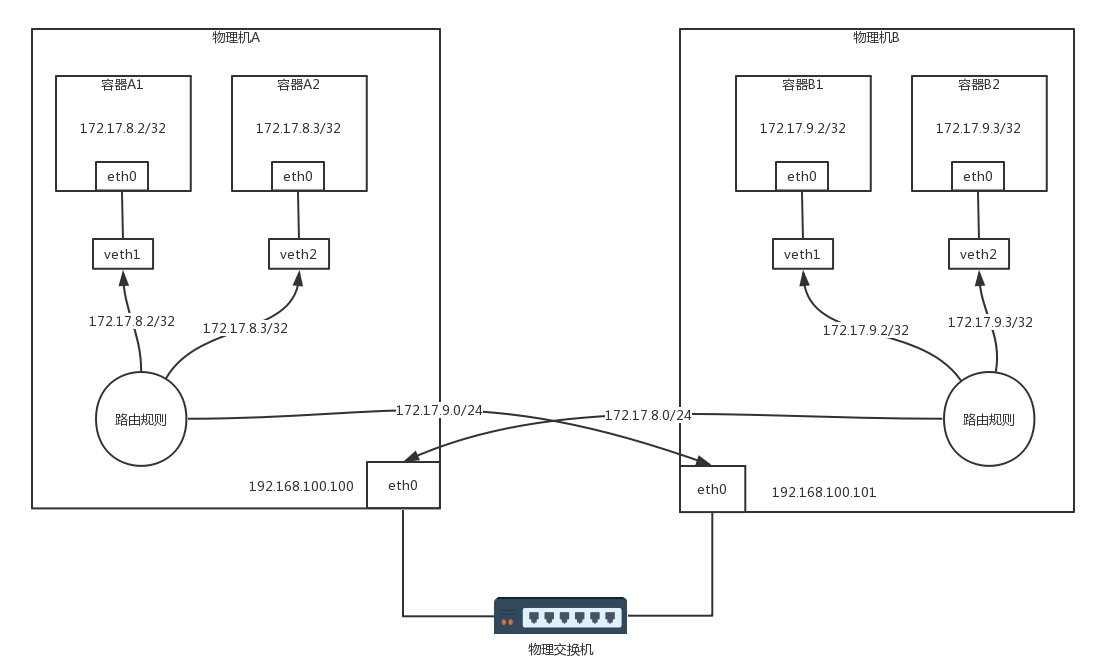
- 容器 A1 的 IP 地址为 172.17.8.2/32,不是 /24,即将容器 A1 作为一个单点的局域网了。
- 容器 A1 里面的默认路由,Calico 的配置如下。 这个 IP 地址 169.254.1.1 是默认的网关,但是整个拓扑图中没有一张网卡是这个地址,它的作用只是 Calico 插入的一个可以响应 ARP 的节点。它对应的 MAC 地址可以通过 ARP 本地缓存查看(ip neigh 命令)
1
2default via 169.254.1.1 dev eth0
169.254.1.1 dev eth0 scope link这个 MAC 地址是 Calico 硬塞进去的,它能响应 ARP。1
169.254.1.1 dev eth0 lladdr ee:ee:ee:ee:ee:ee STALE
- 在物理机 A 上查看所有网卡的 MAC 地址的时候,我们会发现 veth1 就是上述这个 MAC 地址。所以容器 A1 里发出的网络包,第一跳就是这个 veth1 这个网卡,也就到达了物理机 A 这个路由器。
- 物理机上的路由规则配置
- 物理机 A 上有三条路由规则,分别是去两个本机的容器的路由,以及去 172.17.9.0/24,下一跳为物理机 B。
- 物理机 B 上也有三条路由规则,分别是去两个本机的容器的路由,以及去 172.17.8.0/24,下一跳为物理机 A。
- 最终上面的拓扑结构图可以转换为下图,物理机当做路由器使用,直接将包转发至目的地。在这个过程中,没有隧道封装解封装,仅仅是单纯的路由转发,性能会好很多。
Calico 的架构
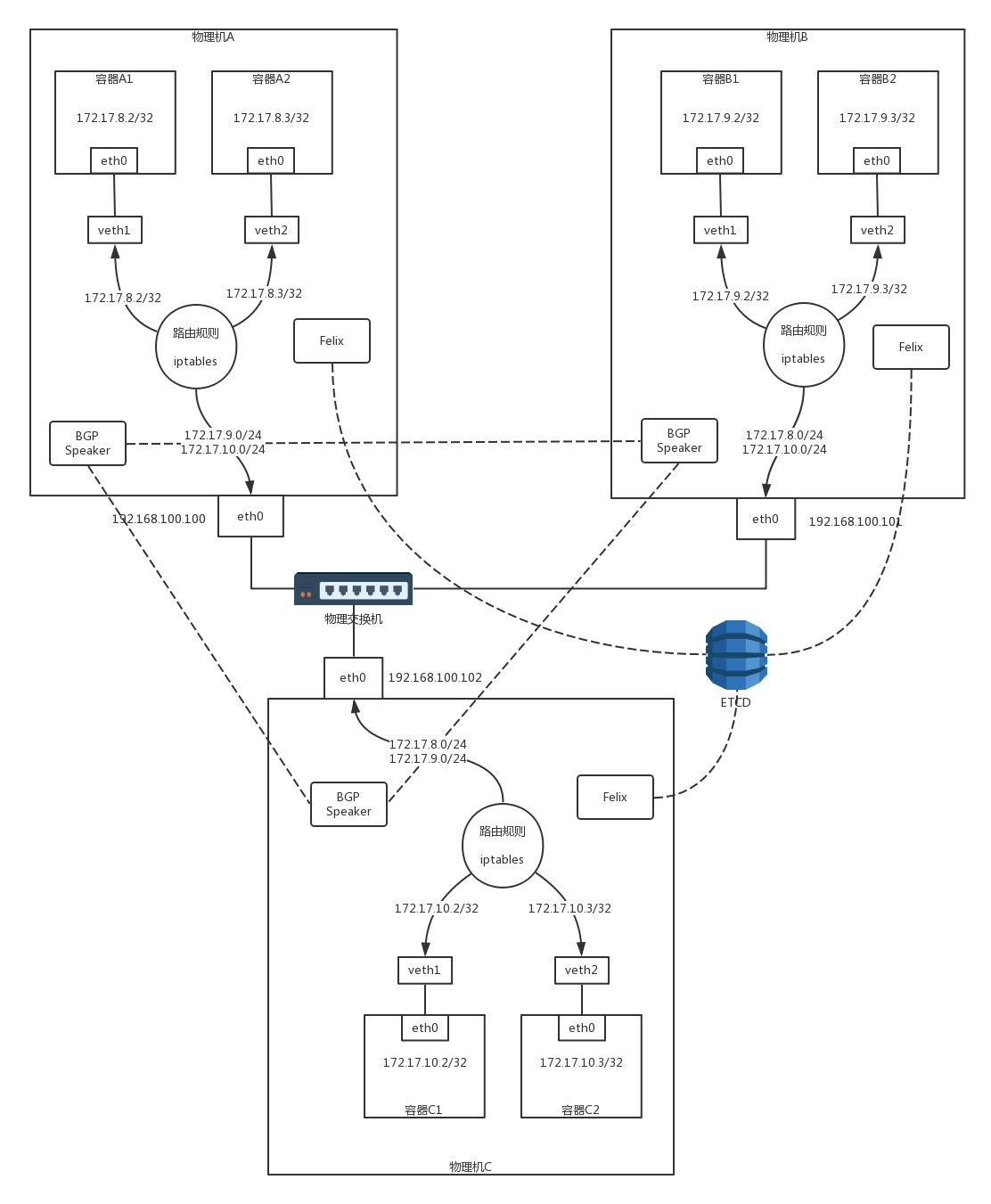
- 路由配置组件 Felix
- 每台物理机上有一个 agent,当创建和删除容器的时候,自动做路由配置的事情。这个 agent 在 Calico 中称为 Felix。
- 路由广播组件 BGP Speaker
- 在 Calico 中,每个 Node 上运行一个软件 BIRD,作为 BGP 的客户端,或者叫作 BGP Speaker,将“如何到达我这个 Node,访问我这个 Node 上的容器”的路由信息广播出去。所有 Node 上的 BGP Speaker 都互相建立连接,就形成了全互连的情况,这样每当路由有所变化的时候,所有节点就都能够收到了。
- 安全策略组件
- Calico 中也是用 iptables 实现的。因此在 iptables 在内核处理网络包的过程中嵌入的处理点,Calico 也可以设置相应的规则,当然也可以设置安全组。
全连接复杂性与规模问题
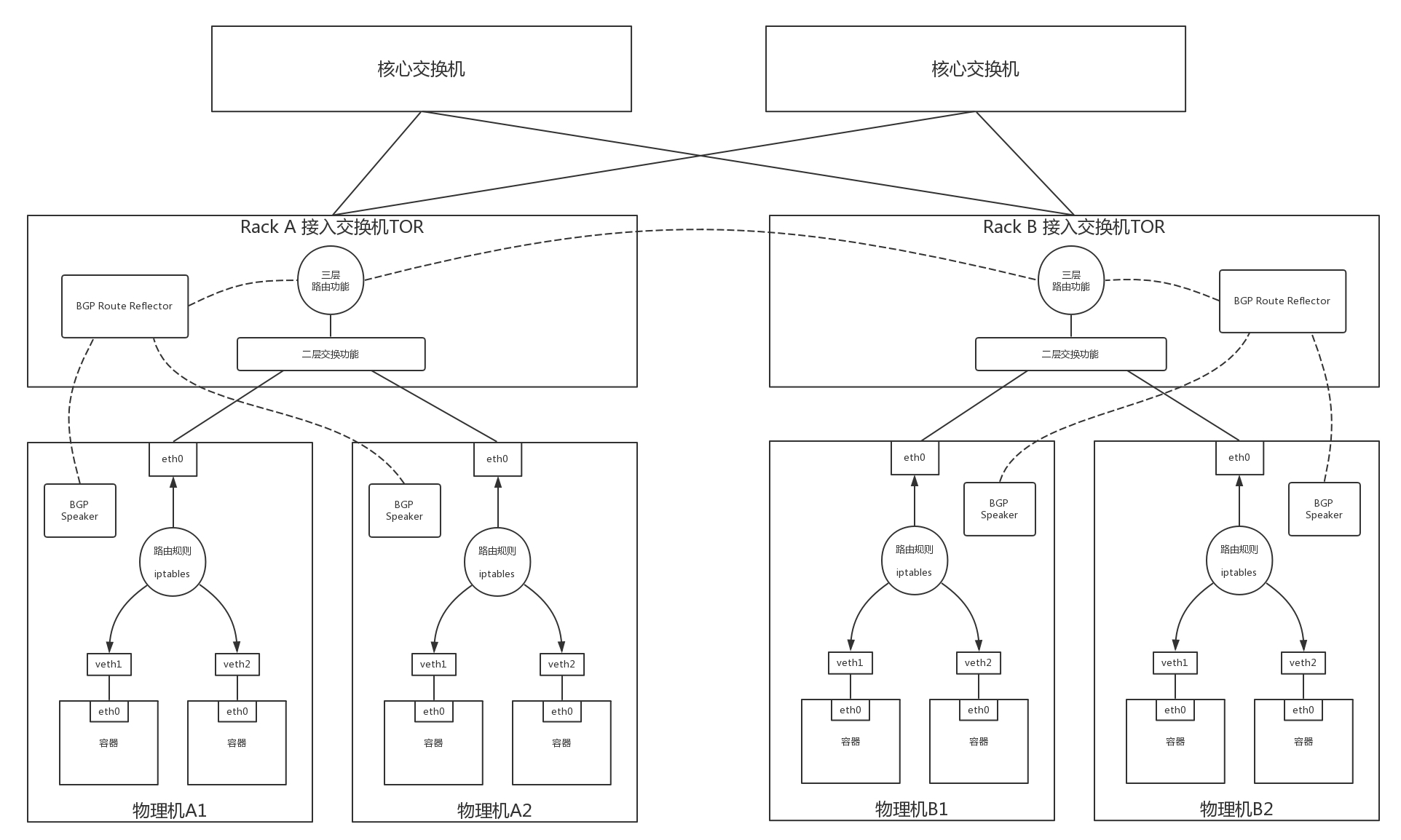
BGP Route Reflector 组件,它也是用 BIRD 实现的。
- BGP Speaker 都直连它,它负责将全网的路由信息广播出去。
- 一个网络中有多个 BGP Router Reflector,每个 BGP Router Reflector 管一部分。
- 每个机架作为一个单元,由一个 BGP Router Reflector 来管理。
- 一个机架就像一个数据中心,可以把它设置为一个自治系统(AS,Autonomous System)。BGP Router Reflector 有点儿像数据中心的边界路由器。
- 在一个 AS 内部,也即服务器和 BGP Router Reflector 之间使用的是数据中心内部的路由协议 iBGP。
- BGP Router Reflector 之间使用的是数据中心之间的路由协议 eBGP。
跨网段访问问题
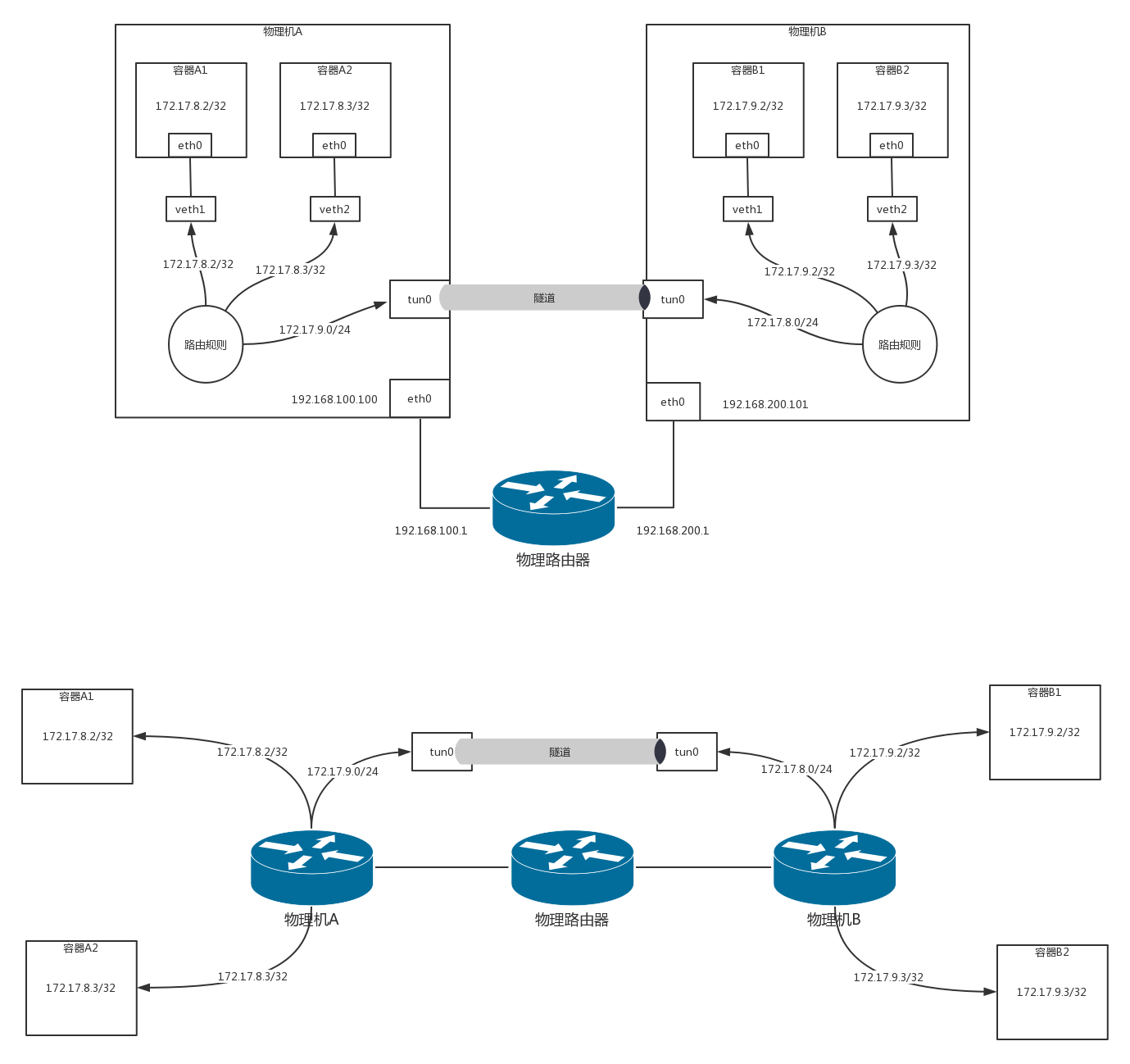
在物理机 A 和物理机 B 之间打一个隧道,这个隧道有两个端点,在端点上进行封装,将容器的 IP 作为乘客协议放在隧道里面,而物理主机的 IP 放在外面作为承载协议。这样不管外层的 IP 通过传统的物理网络,走多少跳到达目标物理机,从隧道两端看起来,物理机 A 的下一跳就是物理机 B。
这就是 Calico 的IPIP 模式。使用了 IPIP 模式之后,在物理机 A 上,我们能看到这样的路由表:
1 | 172.17.8.2 dev veth1 scope link |
和原来的区别在于,下一跳不再是同一个网段的物理机 B 了,IP 为 192.168.200.101,并且不是从 eth0 跳,而是建立一个隧道的端点 tun0,从这里才是下一跳。
以容器 A1 中的 172.17.8.2,去 ping 容器 B1 中的 172.17.9.2 举例
- 首先会到物理机 A。在物理机 A 上根据上面的规则,会转发给 tun0,并在这里对包做封装。
- 内层源 IP 为 172.17.8.2;
- 内层目标 IP 为 172.17.9.2;
- 外层源 IP 为 192.168.100.100;
- 外层目标 IP 为 192.168.200.101。
- 将这个包从 eth0 发出去,在物理网络上会使用外层的 IP 进行路由,最终到达物理机 B。
- 在物理机 B 上,tun0 会解封装,将内层的源 IP 和目标 IP 拿出来,转发给相应的容器。
第32讲 | RPC协议综述:远在天边,近在眼前
容器应用之间相互调用的五个问题
- 如何规定远程调用的语法?
- 如何传递参数?
- 如何表示数据?
- 如何知道一个服务端都实现了哪些远程调用?从哪个端口可以访问这个远程调用?
- 发生了错误、重传、丢包、性能等问题怎么办?
协议约定问题
上述的前三个问题统称为协议约定问题,解决方案有如下两个思路。
- 方法1:定制化,自己实现一个统一的库,让其他业务来调用,业务开发人员不需要知道中间传输的细节。
- 弊端
- 通信双方的语法、语义、格式、端口、错误处理等,都需要调用方和被调用方开会商量,双方达成一致。一旦有一方改变,要及时通知对方,否则通信就会有问题。
- 这样的实现需要较高的技术门槛,并不是每一个公司都有这种大牛团队。
- 弊端
- 方法2:使用成熟的框架,比如使用基于 RPC 的调用标准实现的 RPC 框架。
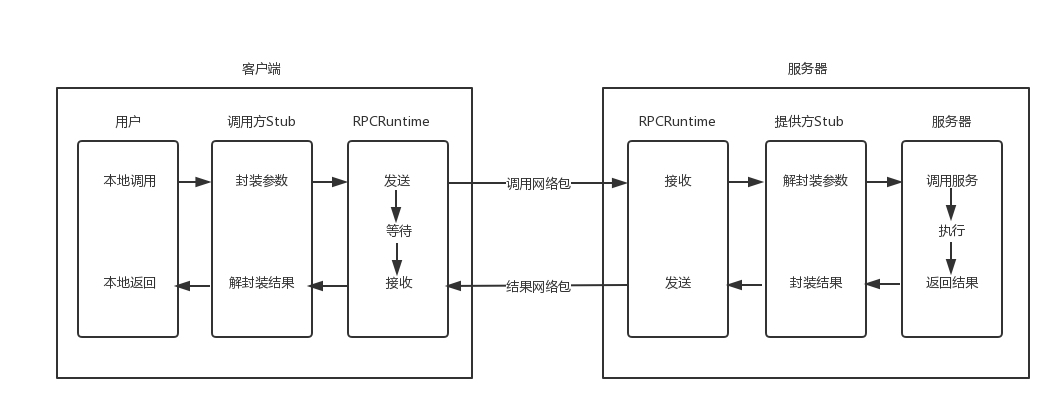
- RPC 调用流程
- 当客户端的应用想发起一个远程调用时,它实际是通过本地调用本地调用方的 Stub。
- 本地方 Stub 负责将调用的接口、方法和参数,通过约定的协议规范进行编码,并通过本地的 RPCRuntime 进行传输,将调用网络包发送到服务器。
- 服务器端的 RPCRuntime 收到请求后,交给提供方 Stub。
- 提供方 Stub 进行解码,然后调用服务端的方法,服务端执行方法,返回结果。
- 提供方 Stub 将返回结果编码后,发送给客户端。
- 客户端的 RPCRuntime 收到结果,发给调用方 Stub。
- 调用方 Stub 解码得到结果,返回给客户端。
- RPC 三层结构
- 对于用户层和服务端,都像是本地调用一样,专注于业务逻辑的处理就可以了。
- 对于 Stub 层,处理双方约定好的语法、语义、封装、解封装。
- 对于 RPCRuntime,主要处理高性能的传输,以及网络的错误和异常。
- RPC 调用流程
接下来以 ONC RPC(也叫 Sun RPC)下,实现一个加法操作的调用来举例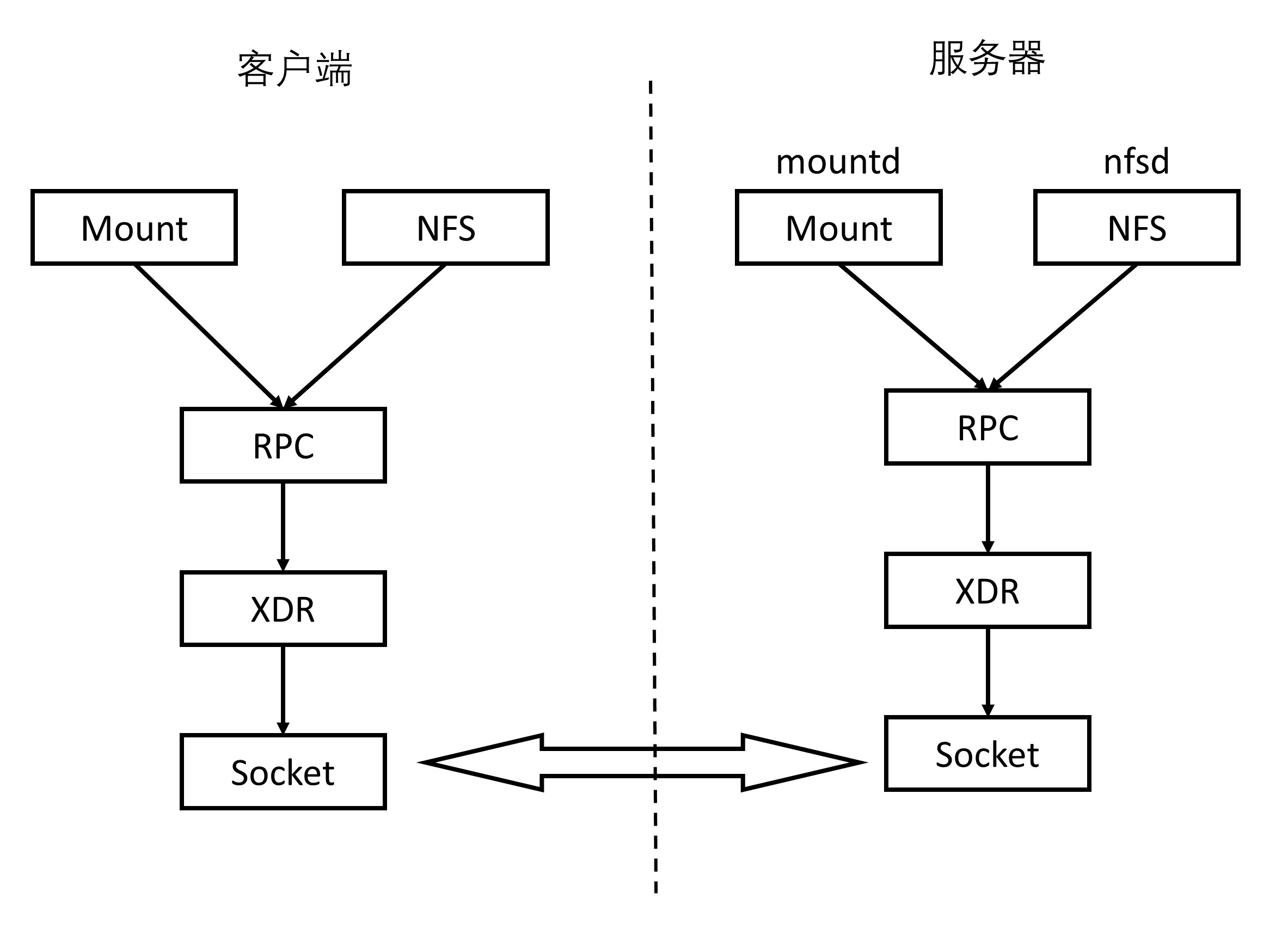
- NFS(Network File System)就是网络文件系统。要使 NFS 成功运行,要启动两个服务端,一个是 mountd,用来挂载文件路径;一个是 nfsd,用来读写文件。NFS 可以在本地 mount 一个远程的目录到本地的一个目录,从而本地的用户在这个目录里面写入、读出任何文件的时候,其实操作的是远程另一台机器上的文件。
NFS 协议就是基于 RPC 实现的
- XDR(External Data Representation,外部数据表示法)是一个标准的数据压缩格式,可以表示基本的数据类型,也可以表示结构体。如图是几种基本数据类型,在 RPC 的调用过程中,所有的数据类型都要封装成类似的格式。
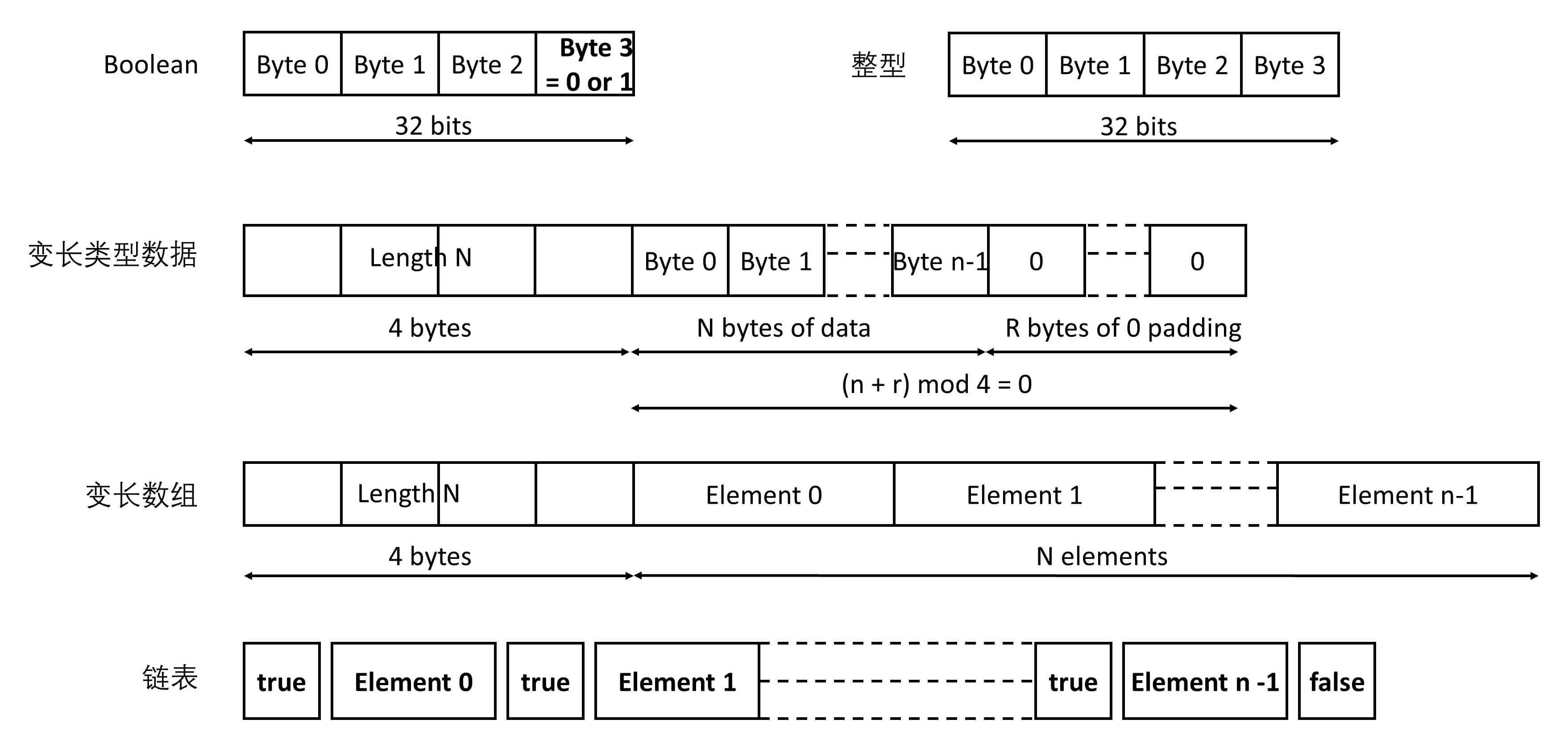
- 无论是什么 RPC,底层都是 Socket 编程。
- RPC 的调用和结果返回,也有严格的格式。
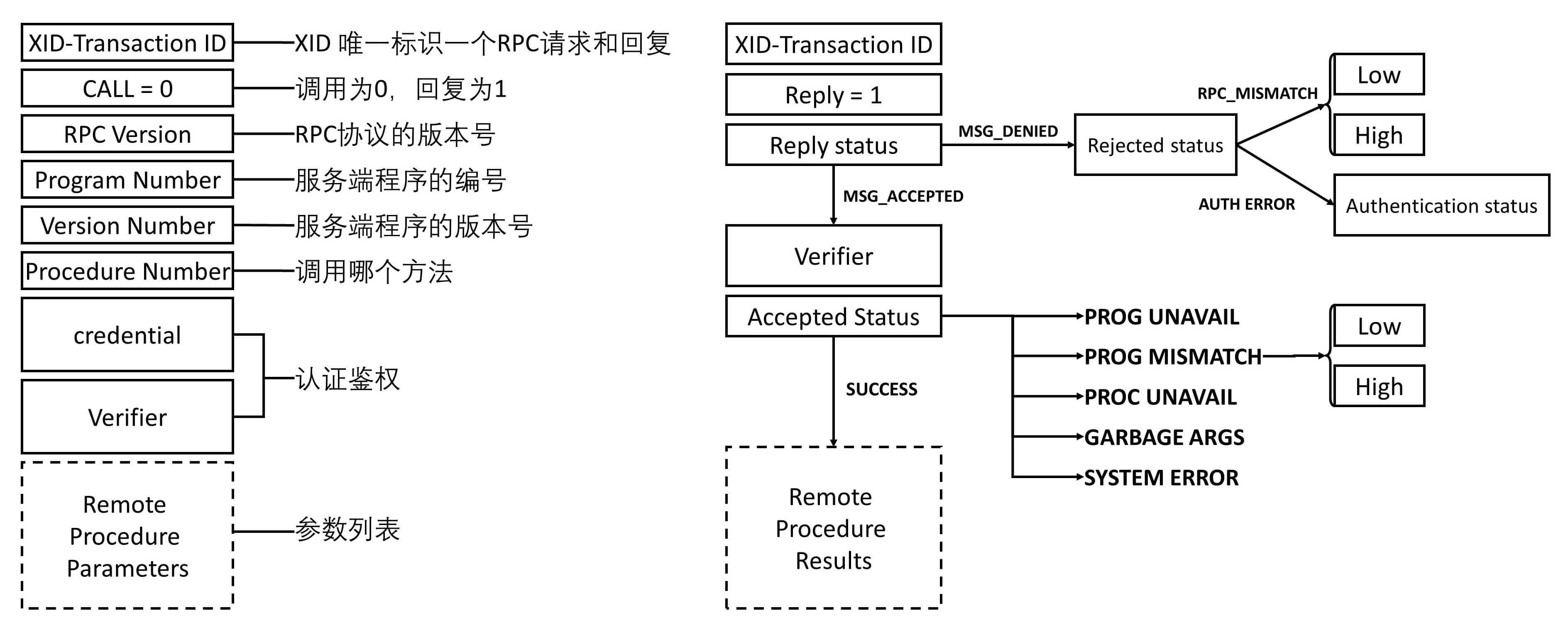
- XID 唯一标识一对请求和回复。请求为 0,回复为 1。
- RPC 有版本号,两端要匹配 RPC 协议的版本号。如果不匹配,就会返回 Deny,原因就是 RPC_MISMATCH。
- 程序有编号。如果服务端找不到这个程序,就会返回 PROG_UNAVAIL。
- 程序有版本号。如果程序的版本号不匹配,就会返回 PROG_MISMATCH。
- 一个程序可以有多个方法,方法也有编号,如果找不到方法,就会返回 PROC_UNAVAIL。
- 调用需要认证鉴权,如果不通过,则 Deny。
- 最后是参数列表,如果参数无法解析,则返回 GABAGE_ARGS。
- 在客户端和服务端实现 RPC 的时候,首先要定义一个双方都认可的程序、版本、方法、参数等。下图是一个加法操作的协定。
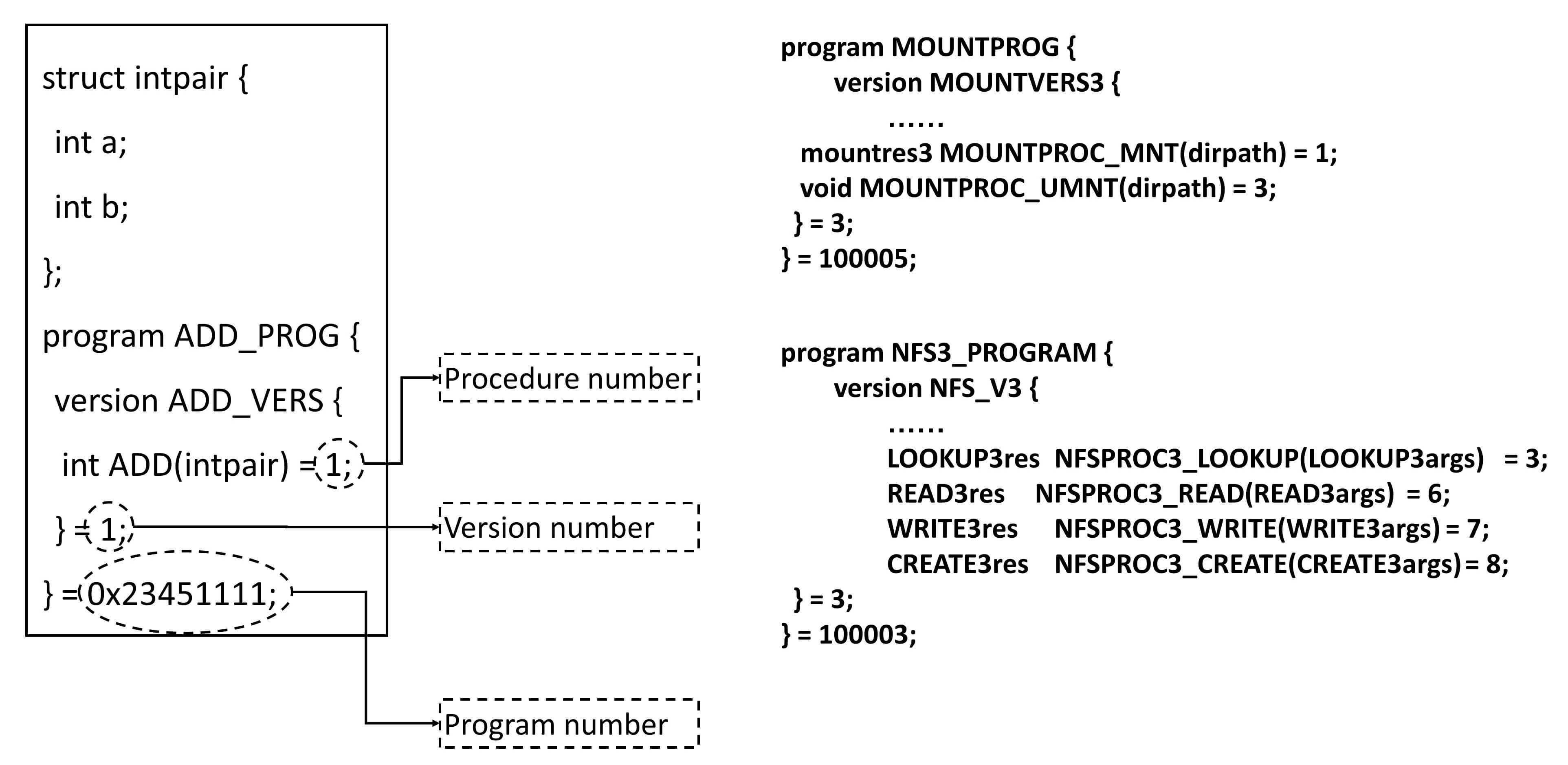
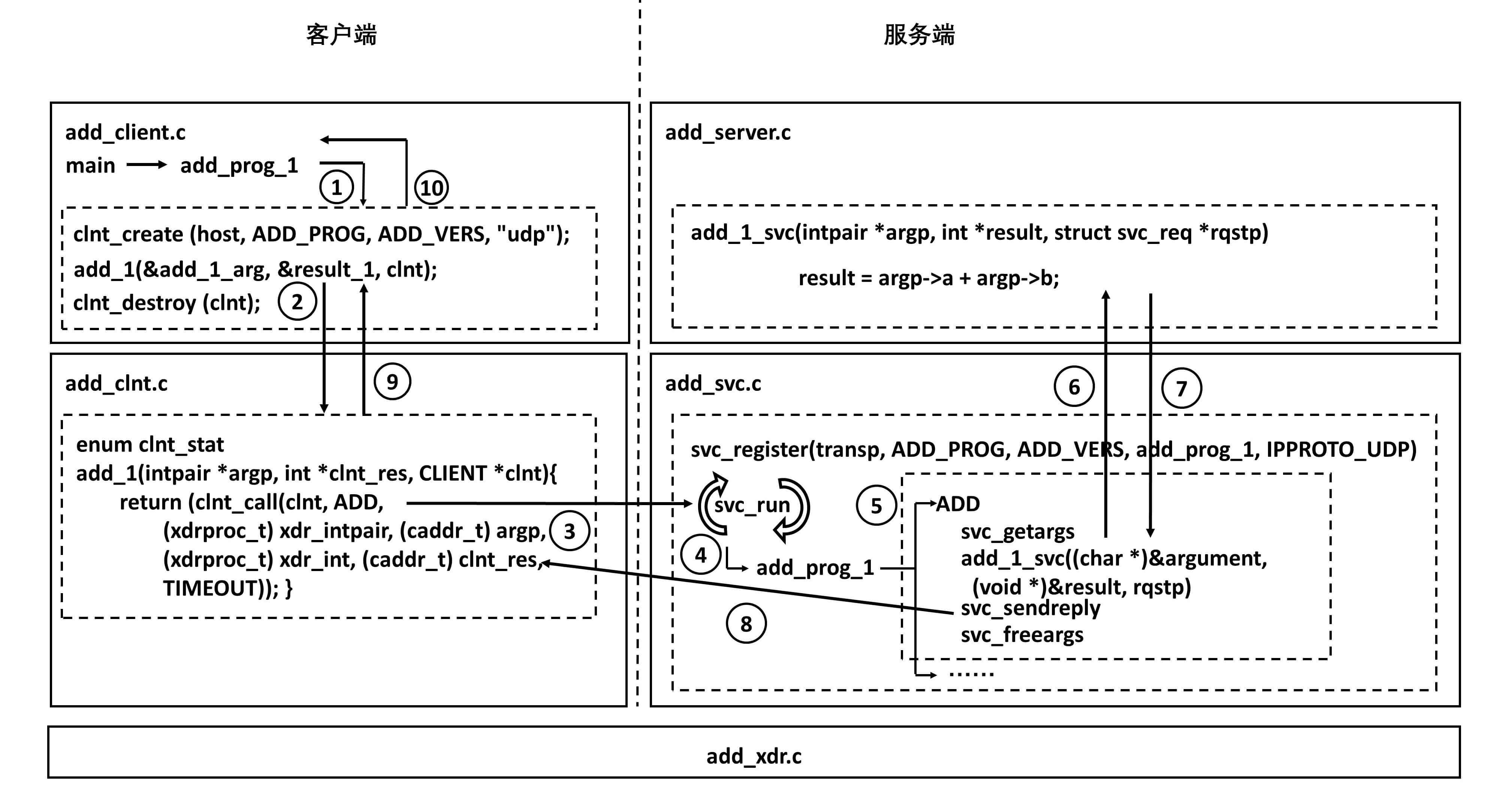
- 有了协议定义文件,ONC RPC 会提供一个工具,根据这个文件生成客户端和服务器端的 Stub 程序。
- 最下层的是 XDR 文件,用于编码和解码参数。这个文件是客户端和服务端共享的,因为只有双方一致才能成功通信。
- 最后依照本例中的加法操作说明一下调用流程
- 在客户端,会调用 clnt_create 创建一个连接,然后调用 add_1,这是一个 Stub 函数,感觉是在调用本地一样。
- Stub 函数 add_1 发起了一个 RPC 调用,通过调用 clnt_call 来调用 ONC RPC 的类库,来真正发送请求。
- 服务端也有一个 Stub 程序,监听客户端的请求,当调用到达的时候,判断如果是 add,则调用真正的服务端逻辑,也即将两个数加起来。
- 服务端将结果返回服务端的 Stub,这个 Stub 程序发送结果给客户端。
- 当结果到达客户端 Stub,就将结果返回给客户端的应用程序,从而完成整个调用过程。
服务发现问题
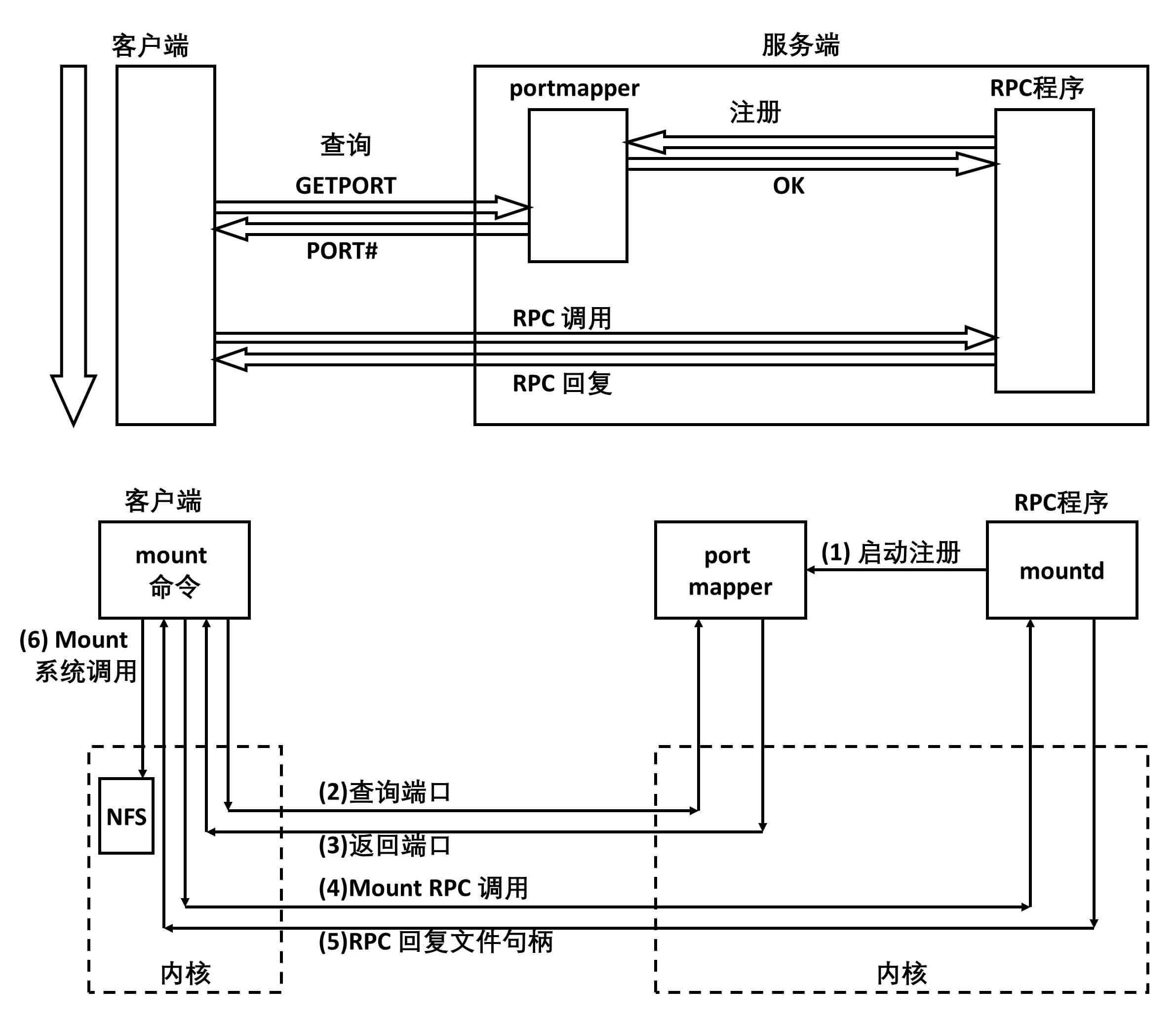
在 ONC RPC 中,服务发现是通过 portmapper 实现的。
- portmapper 会启动在一个众所周知的端口上。
- RPC 程序启动的时候,会向 portmapper 注册。
RPC 程序由于是用户自己写的,会监听在一个随机端口上。
- 客户端要访问 RPC 服务端这个程序的时候,首先查询 portmapper,获取 RPC 服务端程序的端口,然后向这个随机端口建立连接,开始 RPC 调用。
从图中可以看出,mount 命令的 RPC 调用,就是这样实现的。
传输问题
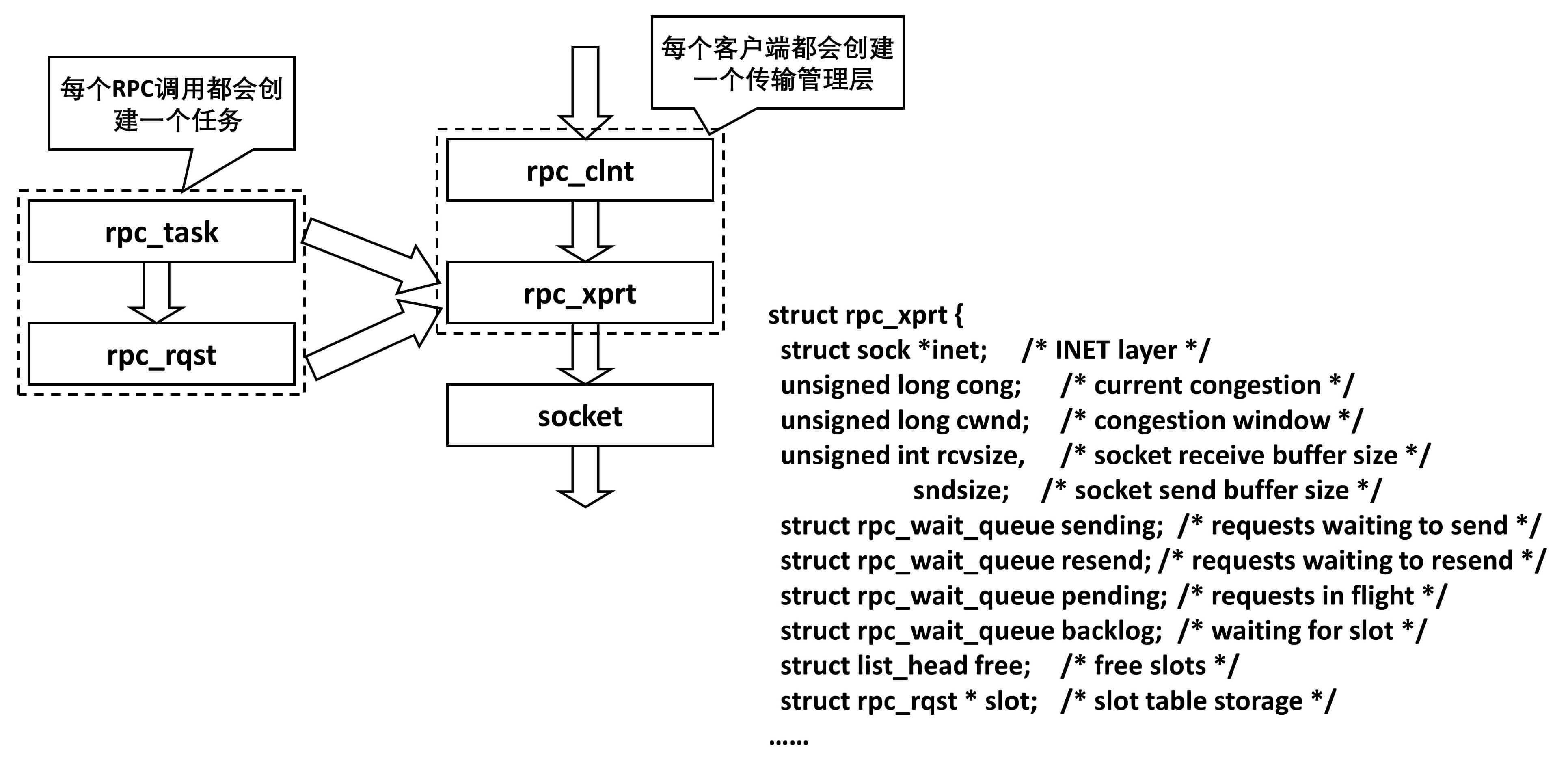
ONC RPC 的类库实现了错误、重传、丢包、性能等功能,只需调用即可。在这个类库中,为了解决传输问题,对于每一个客户端,都会创建一个传输管理层,而每一次 RPC 调用,都会是一个任务,在传输管理层,你可以看到熟悉的队列机制、拥塞窗口机制等。
第33讲 | 基于XML的SOAP协议:不要说NBA,请说美国职业篮球联赛
ONC RPC 存在哪些问题?
- 需要双方的压缩格式完全一致
- 协议修改不灵活
- 业务逻辑变化后,需要双方都知晓,并重新生成 Stub 程序。
- 版本问题
- 一旦某个用户有新的需求,则整个服务端的程序也要做对应的调整,同时,已经部署的其他用户(客户端)也需要升级到新版本。
- ONC RPC 的设计明显是面向函数的,而非面向对象
- 这需要客户端和服务端的开发人员密切沟通,相互合作,有大量的共同语言,才能按照既定的协议顺畅地进行工作。
- 对于面向过程与面向对象的区别,这里以 XML 格式来举例
1
2
3
4
5
6<order>
<date>2018-07-01</date>
<className> 趣谈网络协议 </className>
<Author> 刘超 </Author>
<price>68</price>
</order>- date,className 等参数的顺序没有固定要求
- 如果需要添加参数 count,值为 10,只需要添加一行
<count>10</count>即可,而且对于不需要该参数的客户端,不解析这个参数即可。
传输协议问题与 SOAP
SOAP 是一个基于 XML 的通信协议,全称简单对象访问协议(Simple Object Access Protocol)。它使用 XML 编写简单的请求和回复消息,并用 HTTP 协议进行传输。
SOAP 将请求和回复放在一个信封里面,就像传递一个邮件一样。信封里面的信分抬头和正文。
- 抬头
1
2
3
4POST /purchaseOrder HTTP/1.1
Host: www.geektime.com
Content-Type: application/soap+xml; charset=utf-8
Content-Length: nnn - 正文
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
<soap:Envelope xmlns:soap="http://www.w3.org/2001/12/soap-envelope"
soap:encodingStyle="http://www.w3.org/2001/12/soap-encoding">
<soap:Header>
<m:Trans xmlns:m="http://www.w3schools.com/transaction/"
soap:mustUnderstand="1">1234
</m:Trans>
</soap:Header>
<soap:Body xmlns:m="http://www.geektime.com/perchaseOrder">
<m:purchaseOrder">
<order>
<date>2018-07-01</date>
<className> 趣谈网络协议 </className>
<Author> 刘超 </Author>
<price>68</price>
</order>
</m:purchaseOrder>
</soap:Body>
</soap:Envelope>
协议约定问题
可以通过 Web 服务描述语言,WSDL(Web Service Description Languages)来说明协议约定。WSDL 也是一个 XML 文件。
- WSDL 的优点
- 对于某个服务,可以通过在服务地址后面加上“?wsdl”来获取到这个文件。
- WSDL 可以通过工具生成
- 也有工具可以根据 WSDL 生成客户端 Stub,让客户端通过 Stub 进行远程调用,就跟调用本地的方法一样。
- WSDL 的格式如下
- 定义一个类型 order,与上面的 XML 对应起来
1
2
3
4
5
6
7
8
9
10<wsdl:types>
<xsd:schema targetNamespace="http://www.example.org/geektime">
<xsd:complexType name="order">
<xsd:element name="date" type="xsd:string"></xsd:element>
<xsd:element name="className" type="xsd:string"></xsd:element>
<xsd:element name="Author" type="xsd:string"></xsd:element>
<xsd:element name="price" type="xsd:int"></xsd:element>
</xsd:complexType>
</xsd:schema>
</wsdl:types> - 定义一个 message 的结构
1
2
3<wsdl:message name="purchase">
<wsdl:part name="purchaseOrder" element="tns:order"></wsdl:part>
</wsdl:message> - 暴露一个端口
1
2
3
4
5
6<wsdl:portType name="PurchaseOrderService">
<wsdl:operation name="purchase">
<wsdl:input message="tns:purchase"></wsdl:input>
<wsdl:output message="......"></wsdl:output>
</wsdl:operation>
</wsdl:portType> - 编写一个 binding,将上面定义的信息绑定到 SOAP 请求的 body 里面
1
2
3
4
5
6
7
8
9
10
11
12<wsdl:binding name="purchaseOrderServiceSOAP" type="tns:PurchaseOrderService">
<soap:binding style="rpc"
transport="http://schemas.xmlsoap.org/soap/http" />
<wsdl:operation name="purchase">
<wsdl:input>
<soap:body use="literal" />
</wsdl:input>
<wsdl:output>
<soap:body use="literal" />
</wsdl:output>
</wsdl:operation>
</wsdl:binding> - 编写 service
1
2
3
4
5<wsdl:service name="PurchaseOrderServiceImplService">
<wsdl:port binding="tns:purchaseOrderServiceSOAP" name="PurchaseOrderServiceImplPort">
<soap:address location="http://www.geektime.com:8080/purchaseOrder" />
</wsdl:port>
</wsdl:service>
- 定义一个类型 order,与上面的 XML 对应起来
服务发现问题
UDDI(Universal Description, Discovery, and Integration),也即统一描述、发现和集成协议。它其实是一个注册中心,服务提供方可以将上面的 WSDL 描述文件,发布到这个注册中心,注册完毕后,服务使用方可以查找到服务的描述,封装为本地的客户端进行调用。
第34讲 | 基于JSON的RESTful接口协议:我不关心过程,请给我结果
SOAP 的问题
无论 XML 中调用的是什么函数,多是通过 HTTP 的 POST 方法发送的。这就浪费了 HTTP 其他方法以及他们本身附带的意义。
传输协议问题与 RESTful 格式的 API
RESTful 是一种架构风格,全称 Representational State Transfer,表述性状态转移。
对于之前 SOAP 中的提交订单操作,使用 RESTful 风格 API 可以改写为如下的形式。
1 | POST /purchaseOrder HTTP/1.1 |
协议约定问题(对比 REST/RESTful 与 SOAP)
RESTful API 使用 JSON 进行协议约定。如上的请求可以改写为如下的形式。
1 | POST /purchaseOrder HTTP/1.1 |
下面对比一下 REST 与 SOAP
- REST 是一种设计风格,一种架构,SOAP 是一种严格规定的标准
- 如果按照 REST 风格进行设计,RESTful 接口和 SOAP 接口都能做到,只不过后面的架构是 REST 倡导的,而 SOAP 相对比较关注前面的接口。
- REST 倾向于客户端记录业务状态,SOAP 则并不关心谁来记录状态
- SOAP 在设计之初便能够通过 WSDL 生成客户端的 Stub,因而 SOAP 常常被用于类似传统的 RPC 方式,也即调用远端和调用本地是一样的。这就导致 SOAP 并不太关心谁来记录状态。这在 SOAP 出现的年代是可以的,因为服务端与客户端的比例并未失衡。但在互联网时代,服务端可能需要记录数以千万记的客户端的状态。
- REST 倾向于服务端的无状态化,即让客户端记录状态。
比如要访问一个当前文件夹下的文件列表,服务端记录状态则是服务端记录客户端当前所在的文件夹路径;客户端记录状态则是自己记录当前所在的文件夹路径,并将之提交给服务端。
这里需要区分资源状态与业务逻辑状态,上述的例子是业务逻辑状态,交由客户端自己处理,而资源状态,比如文件夹有哪些,结构如何,还是需要服务端来记录。
服务发现问题
我们可以使用一些框架来解决服务发现的问题,这里以 Spring Cloud 举例。Spring Cloud 是一个基于 RESTful API 的跨系统调用框架。
- 在 Spring Cloud 中有一个组件叫 Eureka,用来实现注册中心,负责维护注册的服务列表。
- 服务提供方向 Eureka 做服务注册、续约和下线等操作,注册的主要数据包括服务名、机器 IP、端口号、域名等等。为了实现负载均衡和容错,服务提供方可以注册多个。
- 服务消费方向 Eureka 获取服务提供方的注册信息,即获取可以调用的服务。
- 服务消费方可以使用 RestTemplate 工具进行服务调用。RestTemplate 是 Spring Cloud 提供的一个工具,用于将请求对象转换为 JSON,并发起 Rest 调用,RestTemplate 的调用也是分 POST、PUT、GET、 DELETE 的,当结果返回的时候,根据返回的 JSON 解析成对象。
第35讲 | 二进制类RPC协议:还是叫NBA吧,总说全称多费劲
数据中心内部是如何相互调用的?
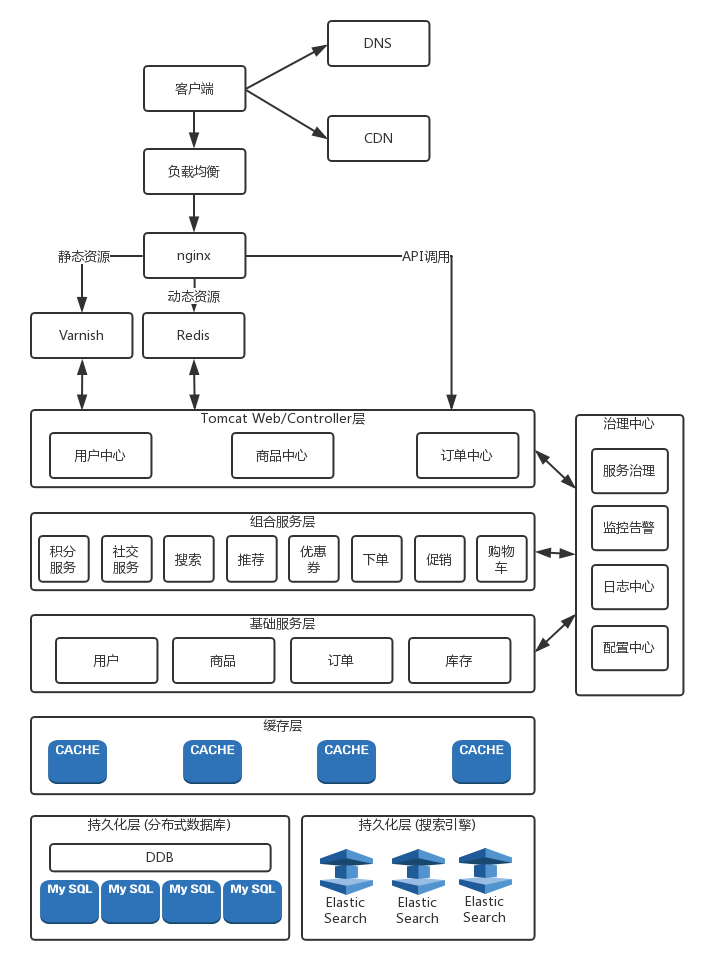
- 数据中心架构
- 对于微服务的架构,API 需要一个 API 网关统一的管理。API 的实现一般在一个叫作Controller 层的地方。这一层对外提供 API。在 Controller 之内,就是互联网应用的业务逻辑实现。
由于是让陌生人访问的,我们能看到目前业界主流的,基本都是 RESTful 的 API,是面向大规模互联网应用的。
- 资源的状态应该维护在最底层的持久化层,一般会使用分布式数据库和 ElasticSearch。
- 由于硬盘读写性能差,因而持久化层往往吞吐量不能达到互联网应用要求的吞吐量,因而前面要有一层缓存层,使用 Redis 或者 memcached 将请求拦截一道。
- 缓存和持久化层之上一般是基础服务层,这里面提供一些原子化的接口。例如,对于用户、商品、订单、库存的增删查改,将缓存和数据库对再上层的业务逻辑屏蔽一道。
- 有了这一层,上层业务逻辑看到的都是接口,而不会调用数据库和缓存。
- 对于缓存层的扩容,数据库的分库分表,所有的改变,都截止到这一层,这样有利于将来对于缓存和数据库的运维。
- 再往上就是组合层。因为基础服务层只是提供简单的接口,实现简单的业务逻辑,而复杂的业务逻辑,比如下单,要扣优惠券,扣减库存等,就要在组合服务层实现。
- 对于微服务的架构,API 需要一个 API 网关统一的管理。API 的实现一般在一个叫作Controller 层的地方。这一层对外提供 API。在 Controller 之内,就是互联网应用的业务逻辑实现。
- 数据中心内部的调用
- 按照上面的结构,Controller 层、组合服务层、基础服务层就会相互调用,这个调用是在数据中心内部的,量也会比较大,还是使用 RPC 的机制实现的。
- 由于服务比较多,需要一个单独的注册中心来做服务发现。服务提供方会将自己提供哪些服务注册到注册中心中去,同时服务消费方订阅这个服务,从而可以对这个服务进行调用。
- 这里的 RPC 调用,大多数的选择是使用二进制的方案。因为二进制方案相比文本方案更加省空间和带宽,相应的效能也更好。
Dubbo
Dubbo 是一个服务框架,其内部实现使用了二进制的 RPC 方式。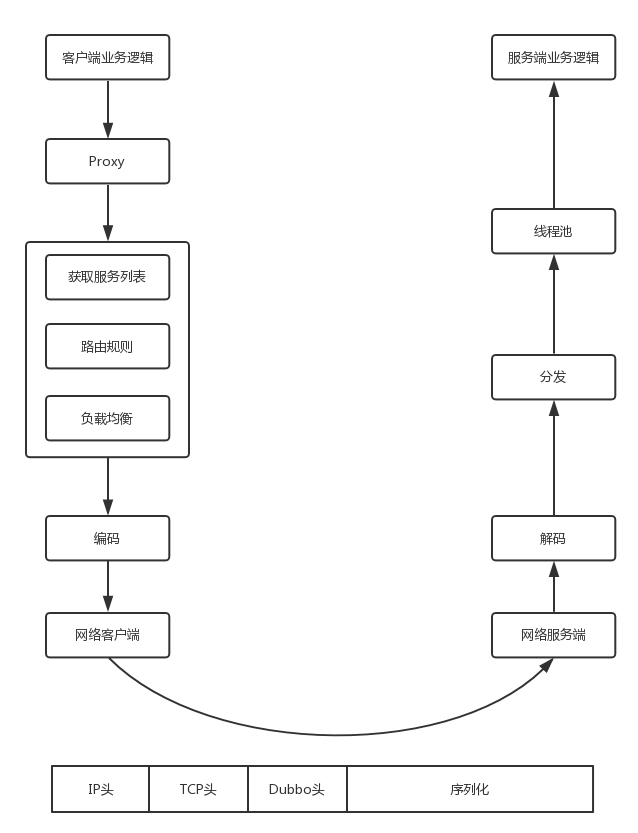
- Dubbo 会在客户端的本地启动一个 Proxy,其实就是客户端的 Stub,对于远程的调用都通过这个 Stub 进行封装。
- 接下来,Dubbo 会从注册中心获取服务端的列表,根据路由规则和负载均衡规则,在多个服务端中选择一个最合适的服务端进行调用。
- 调用服务端的时候,首先要进行编码和序列化,形成 Dubbo 头和序列化的方法和参数。将编码好的数据,交给网络客户端进行发送。
- 网络服务端收到消息后,进行解码。然后将任务分发给某个线程进行处理,在线程中会调用服务端的代码逻辑,然后返回结果。
Dubbo 如何解决 RPC 三大问题?
- 协议约定问题: Dubbo 中默认的 RPC 协议是 Hessian2
- Hessian2 将远程调用序列化为二进制进行传输,并且可以进行一定的压缩。
- Hessian2 不需要定义这个协议文件,而是自描述的。
- 原来要定义一个协议文件,然后通过这个文件生成客户端和服务端的 Stub,才能进行相互调用,这样使得修改就会不方便。
- 所谓自描述就是,关于调用哪个函数,参数是什么,另一方不需要拿到某个协议文件、拿到二进制,靠它本身根据 Hessian2 的规则,就能解析出来。
这其实相当于综合了 XML 和二进制的共同优势。
- RPC 传输问题: Dubbo 默认使用 Netty 的网络传输框架。
- Netty 是一个非阻塞的基于事件的网络传输框架,在服务端启动的时候,会监听一个端口,并注册以下的事件。
- 连接事件:当收到客户端的连接事件时,会调用 void connected(Channel channel) 方法。
- 可写事件:当可写事件触发时,会调用 void sent(Channel channel, Object message),服务端向客户端返回响应数据。
- 可读事件:当可读事件触发时,会调用 void received(Channel channel, Object message) ,服务端在收到客户端的请求数据。
- 发生异常:当发生异常时,会调用 void caught(Channel channel, Throwable exception)。
- 当事件触发之后,服务端可以选择直接在这个函数里面进行操作,还是将请求分发到线程池去处理。一般异步的数据读写都需要另外的线程池参与,在线程池中会调用真正的服务端业务代码逻辑,返回结果。
Dubbox 还有其他的 RPC 协议选择,例如从 Spark 那里借鉴 Kryo,实现高性能的序列化。
- Netty 是一个非阻塞的基于事件的网络传输框架,在服务端启动的时候,会监听一个端口,并注册以下的事件。
- 注册发现问题: 通过注册中心解决
为何 Spring Cloud 又兴起了?
Dubbox 等基于二进制 RPC 协议的服务端框架存在的问题
- Dubbox 等方案,接口的定义,以及传的对象 DTO,还是需要共享 JAR。因为只有客户端和服务端都有这个 JAR,才能成功地序列化和反序列化。
- 并发量越来越大,微服务粒度更细,模块之间的关系更加复杂,JAR 的依赖也变得异常复杂,难以维护。
上述问题的解决方案主要有以下两种,一般结合实际场景进行选择。
- 方案1: 建立严格的项目管理流程
- 不允许循环调用,不允许跨层调用,只准上层调用下层,不允许下层调用上层。
- 接口要保持兼容性,不兼容的接口新添加而非改原来的,当接口通过监控,发现不用的时候,再下掉。
- 升级的时候,先升级服务提供端,再升级服务消费端。
- 方案2: 改用 RESTful 的方式
- 使用 Spring Cloud,消费端和提供端不用共享 JAR,各声明各的,只要能变成 JSON 就行,而且 JSON 也是比较灵活的。
- 使用 RESTful 的方式,性能会降低,所以需要通过横向扩展来抵消单机的性能损耗。
第36讲 | 跨语言类RPC协议:交流之前,双方先来个专业术语表
前文 RPC 内容总结
四种框架
- ONC RPC
- 基于 XML 的 SOAP
- 基于 JSON 的 RESTful
- 基于 JSON 的 Hessian2
一个 RPC 框架中,各处细节实现的选择与差别
- 传输数据格式
- 二进制的性能好,但难以跨语言
- 文本的性能差,但可以跨语言
- 是否需要文件协议
- 写文件协议的严谨一些,但不灵活
- 不写文件协议的不太严谨,但灵活
- 服务发现机制
- 有些可以服务治理
- 有些不能服务治理
对 RPC 框架的要求越来越多,具体细节如下
- 传输性能很重要。还是二进制的越快越好。
- 跨语言很重要。服务多了,什么语言写成的都有,而且不同的场景适宜用不同的语言,不能一个语言走到底。
- 最好既严谨又灵活,添加个字段不用重新编译和发布程序。
- 最好既有服务发现,也有服务治理。就像 Dubbo 和 Spring Cloud 一样。
Protocol Buffers
GRPC 满足二进制和跨语言这两条,它通过一个协议约定文件来实现这两点的共存。对于 GRPC 来讲,二进制序列化协议是 Protocol Buffers。
这里以购买极客时间专栏来举例说明 Protocol Buffers 格式,其协议文件后缀名为 .proto。
1 | syntax = “proto3”; |
- 首先指定使用 proto3 的语法
- 使用 Protocol Buffers 的语法,定义两个消息的类型
- 一个是发出去的参数,一个是返回的结果
- 里面的每一个字段,例如 date、classname、author、price 都有唯一的一个数字标识,这样在压缩的时候,就不用传输字段名称了,只传输这个数字标识就行了,能节省很多空间。
- 定义一个 Service,里面会有一个 RPC 调用的声明。
无论使用什么语言,都有相应的工具生成客户端和服务端的 Stub 程序,这样客户端就可以像调用本地一样,调用远程的服务了。
协议约定问题
Protocol Buffers 考虑了兼容性。在协议文件中,每一个字段都有修饰符。比如:
- required:这个值不能为空,一定要有这么一个字段出现
- optional:可选字段,可以设置,也可以不设置,如果不设置,则使用默认值
- repeated:可以重复 0 到多次
如果我们想修改协议文件
- 对于赋给某个标签的数字,不允许改变,改变了就不认了
- 不能添加或者删除 required 字段,因为解析的时候,发现没有这个字段就会报错
- 对于 optional 和 repeated 字段,可以删除,也可以添加。这就给了客户端和服务端升级的可能性。
例如,我们在协议里面新增一个 string recommended 字段,表示这个课程是谁推荐的,就将这个字段设置为 optional。
- 可以先升级服务端,当客户端发过来消息的时候,是没有这个值的,将它设置为一个默认值。
- 也可以先升级客户端,当客户端发过来消息的时候,是有这个值的,那它将被服务端忽略。
网络传输问题
如果是 Java 技术栈,GRPC 的客户端和服务器之间通过 Netty Channel 作为数据通道,每个请求都被封装成 HTTP 2.0 的 Stream。
由于基于 HTTP 2.0,GRPC 和其他的 RPC 不同,可以定义四种服务方法。
- 单向 RPC,即客户端发送一个请求给服务端,从服务端获取一个应答。
- 服务端流式 RPC,即服务端返回的不是一个结果,而是一批。客户端发送一个请求给服务端,可获取一个数据流用来读取一系列消息。客户端从返回的数据流里一直读取,直到没有更多消息为止。
- 客户端流式 RPC,也即客户端的请求不是一个,而是一批。客户端用提供的一个数据流写入并发送一系列消息给服务端。一旦客户端完成消息写入,就等待服务端读取这些消息并返回应答。
- 双向流式 RPC,即两边都可以分别通过一个读写数据流来发送一系列消息。这两个数据流操作是相互独立的,所以客户端和服务端能按其希望的任意顺序读写,服务端可以在写应答前等待所有的客户端消息,或者它可以先读一个消息再写一个消息,或者读写相结合的其他方式。每个数据流里消息的顺序会被保持。
服务发现与治理问题
GRPC 本身没有提供服务发现的机制,需要借助其他的组件,发现要访问的服务端,在多个服务端之间进行容错和负载均衡,比如 Envoy。
Envoy 不仅仅是负载均衡器,它还是一个高性能的 C++ 写的 Proxy 转发器,可以配置非常灵活的转发规则。
- Envoy 支持两种规则配置方式
- 静态配置规则
- 规则放在配置文件中的,在启动的时候加载。要想重新加载,一般需要重新启动,但是 Envoy 支持热加载和热重启,这在一定程度上缓解了这个问题。
- 使用方式: 将后端的服务端的 IP 地址拿到,然后放在配置文件里面就可以了。
- 动态配置规则
- 规则放在统一的地方维护,这个统一的地方在 Envoy 眼中被称为服务发现(Discovery Service),过一段时间去这里拿一下配置,就修改了转发策略。
- 使用方式: 需要配置一个服务发现中心,这个服务发现中心要实现 Envoy 的 API,Envoy 可以主动去服务发现中心拉取转发策略。
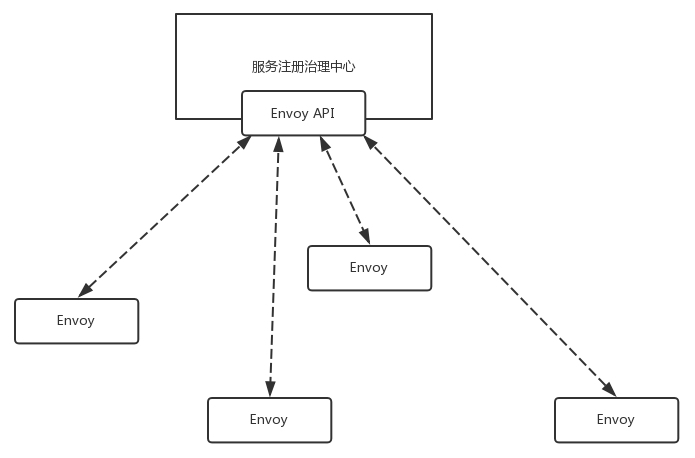
- 静态配置规则
- 无论是静态的,还是动态的,在配置里面往往会配置四个东西。
- listener。Envoy 既然是 Proxy,专门做转发,就得监听一个端口,接入请求,然后才能够根据策略转发,这个监听的端口就称为 listener。
- endpoint,是目标的 IP 地址和端口。这个是 Proxy 最终将请求转发到的地方。
- cluster。一个 cluster 是具有完全相同行为的多个 endpoint,也即如果有三个服务端在运行,就会有三个 IP 和端口,但是部署的是完全相同的三个服务,它们组成一个 cluster,从 cluster 到 endpoint 的过程称为负载均衡,可以轮询。
- 第四个是 route。有时候多个 cluster 具有类似的功能,但是是不同的版本号,可以通过 route 规则,选择将请求路由到某一个版本号,也即某一个 cluster。
- 常见的几种 Envoy 配置使用场景
- 配置路由策略。例如后端的服务有两个版本,可以通过配置 Envoy 的 route,来设置两个版本之间,也即两个 cluster 之间的 route 规则,一个占 99% 的流量,一个占 1% 的流量。
- 负载均衡策略。对于一个 cluster 下的多个 endpoint,可以配置负载均衡机制和健康检查机制,当服务端新增了一个,或者挂了一个,都能够及时配置 Envoy,进行负载均衡。
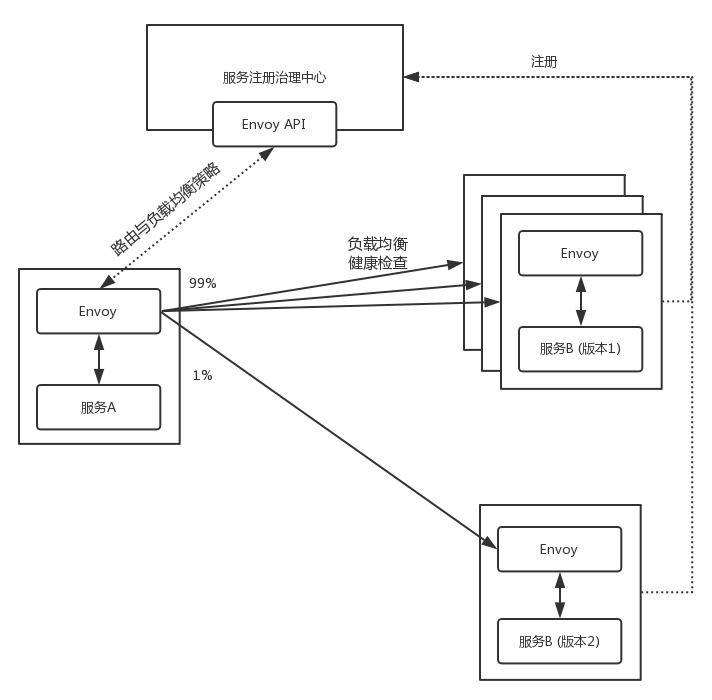
所有这些节点的变化都会上传到注册中心,所有这些策略都可以通过注册中心进行下发,所以,更严格的意义上讲,注册中心可以称为注册治理中心。
Envoy 能够将服务之间的相互调用全部由它代理,这就是未来服务治理的趋势Serivce Mesh。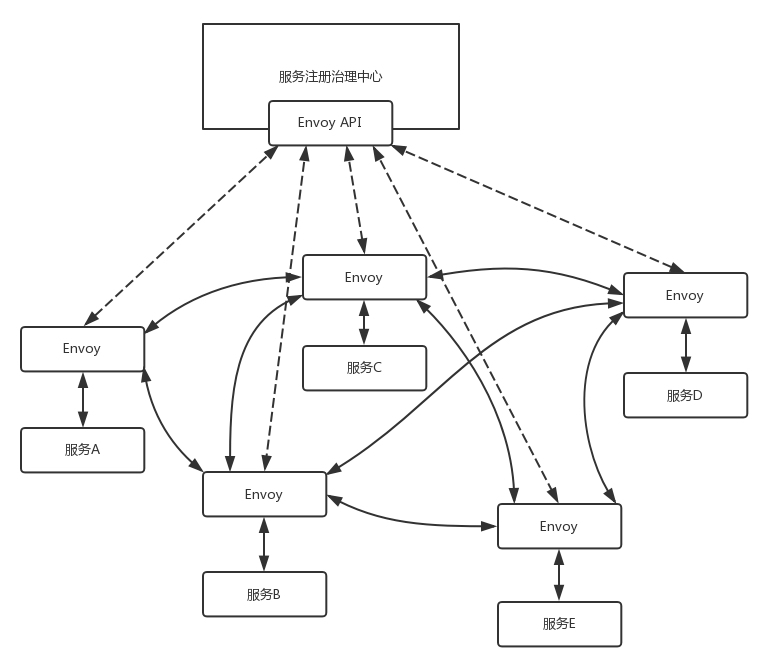
- 服务不需要自己感知到注册中心,自己注册,自己治理,这对应用干预比较大。
- 应用能够意识不到服务治理的存在,就是直接进行 GRPC 的调用就可以了。
第37讲 | 知识串讲:用双十一的故事串起碎片的网络协议(上)
一. 部署一个高可用高并发的电商平台
首先,要有个电商平台。这里假设已经有了一个特别大的电商平台。
- 为了高可用性,需要在公有云上部署多个机房,形成多个可用区(Available Zone)。
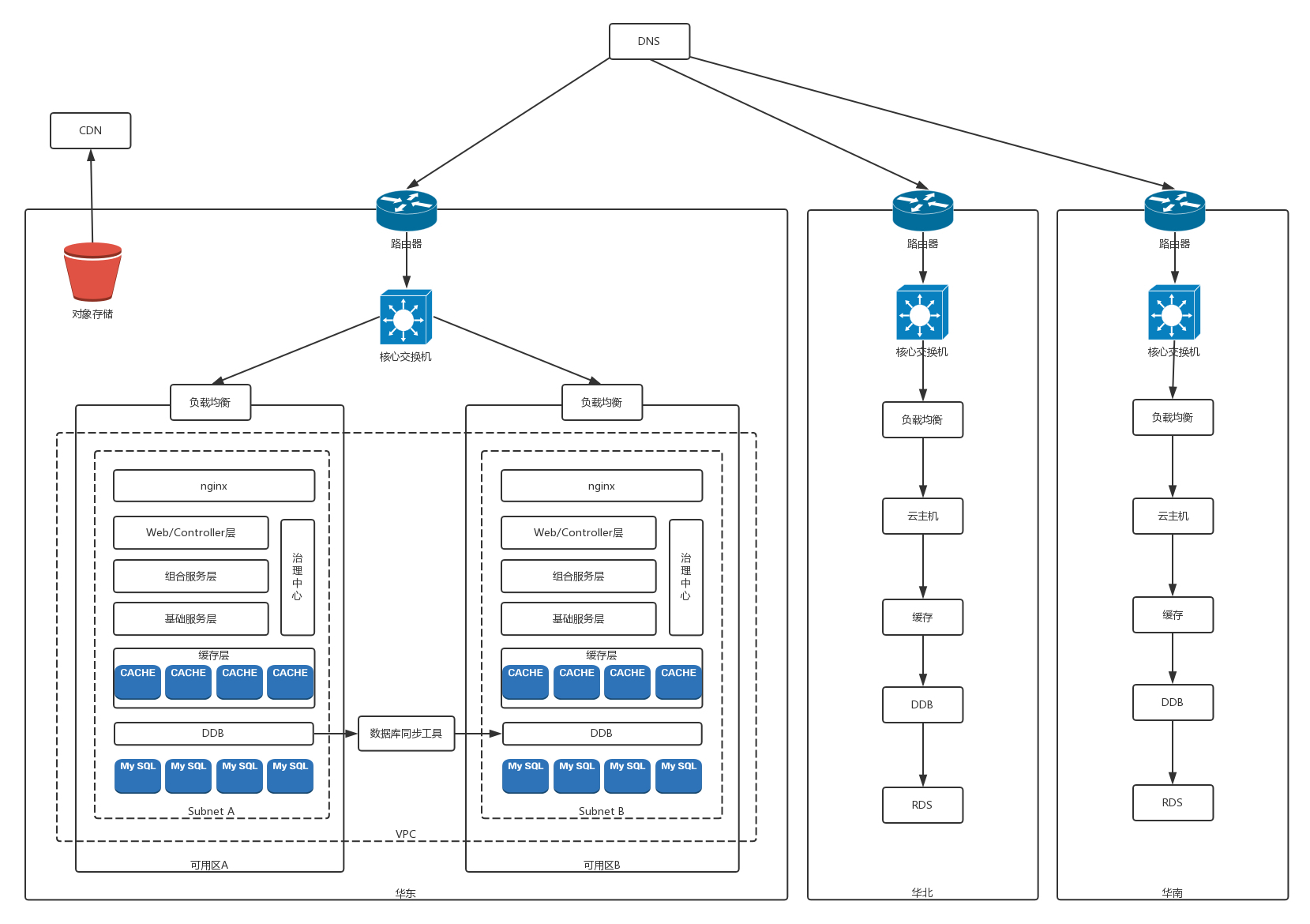
- 每个可用区里有一片一片的机柜,每个机柜上有一排一排的服务器,每个机柜都有一个接入交换机,有一个汇聚交换机将多个机柜连在一起。这些服务器里面部署的都是计算节点,每台上面都有 Open vSwitch 创建的虚拟交换机,将来在这台机器上创建的虚拟机,都会连到 Open vSwitch 上。
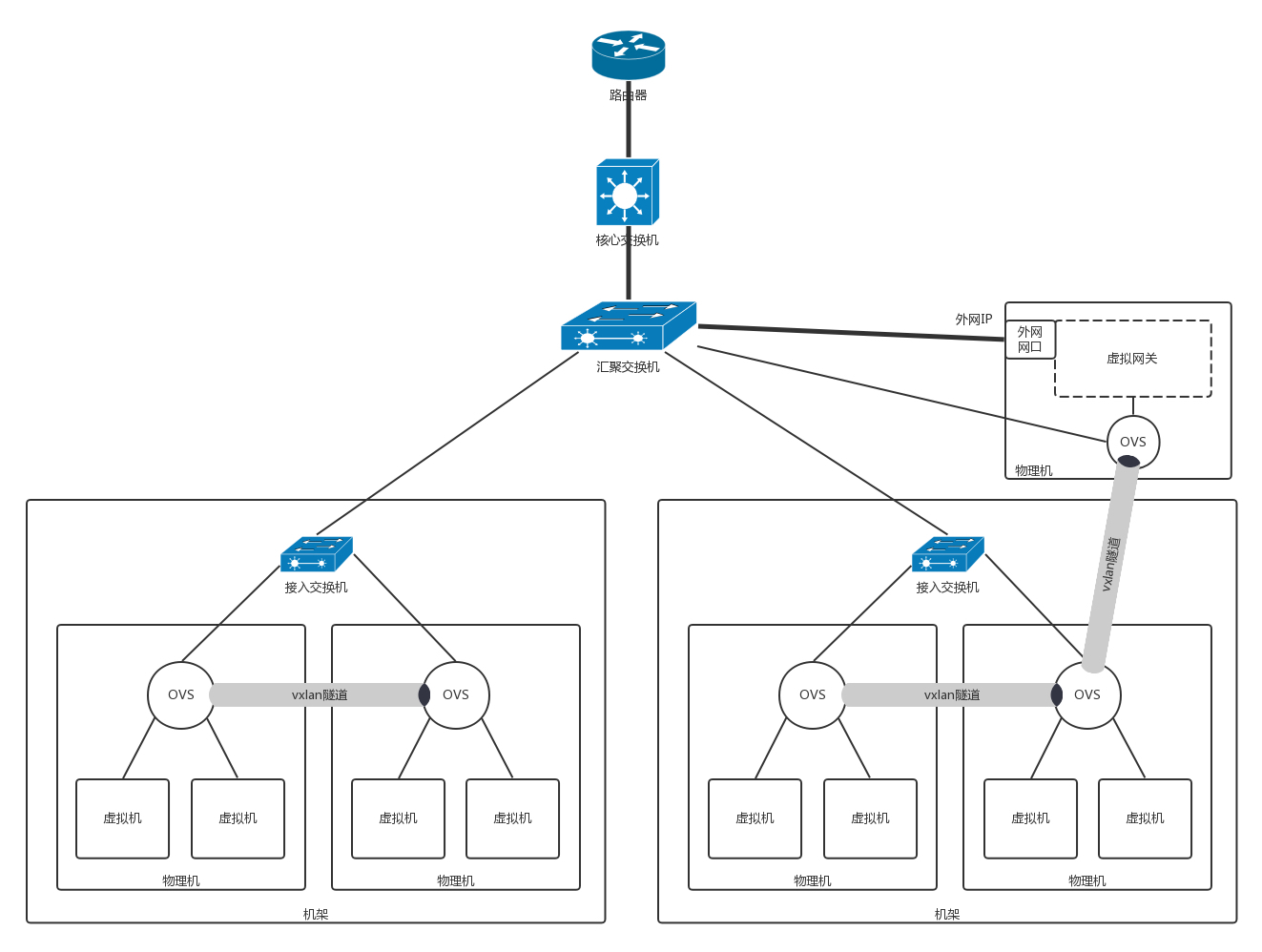
- 在云计算的界面上创建一个 VPC(Virtual Private Cloud,虚拟私有网络),指定一个 IP 段,以后部署的所有应用都会在这个虚拟网络里,使用分配的这个 IP 段。
- 为了不同的 VPC 相互隔离,每个 VPC 都会被分配一个 VXLAN 的 ID。尽管不同用户的虚拟机有可能在同一个物理机上,但是不同的 VPC 二层压根儿是不通的。
- 由于有两个可用区,在这个 VPC 里面,要为每一个可用区分配一个 Subnet,也就是在大的网段里分配两个小的网段。当两个可用区里面网段不同的时候,就可以配置路由策略,访问另外一个可用区,走某一条路由了。
- 创建数据库持久化层。大部分云平台都会提供 PaaS 服务,不需要自己搭建数据库,而是采用直接提供数据库的服务,并且单机房的主备切换都是默认做好的,数据库也是部署在虚拟机里面的,只不过从界面上,你看不到数据库所在的虚拟机而已。
- 云平台会给每个 Subnet 的数据库实例分配一个域名。创建数据库实例的时候,需要你指定可用区和 Subnet,这样创建出来的数据库实例可以通过这个 Subnet 的私网 IP 进行访问。
- 为了分库分表实现高并发的读写,在创建的多个数据库实例之上,会创建一个分布式数据库的实例,也需要指定可用区和 Subnet,还会为分布式数据库分配一个私网 IP 和域名。
- 对于数据库这种高可用性比较高的,需要进行跨机房高可用,因而两个可用区都要部署一套,但是只有一个是主,另外一个是备,云平台往往会提供数据库同步工具,将应用写入主的数据同步给备数据库集群。
- 创建缓存集群。云平台也会提供 PaaS 服务,也需要每个可用区和 Subnet 创建一套,缓存的数据在内存中,由于读写性能要求高,一般不要求跨可用区读写。
- 自己编写的程序。基础服务层、组合服务层、Controller 层,以及 Nginx 层、API 网关等等,这些都是部署在虚拟机里面的。它们之间通过 RPC 相互调用,需要到注册中心进行注册。
- 它们之间的网络通信是虚拟机和虚拟机之间的。如果是同一台物理机,则那台物理机上的 OVS 就能转发过去;如果是不同的物理机,这台物理机的 OVS 和另一台物理机的 OVS 中间有一个 VXLAN 的隧道,将请求转发过去。
- 负载均衡,也是云平台提供的 PaaS 服务。
- 负载均衡也是部署在虚拟机里面的,属于 VPC。
- 负载均衡有个外网的 IP,这个外网的 IP 地址在网关节点的外网网口上。
- 在网关节点上,会有 NAT 规则,将外网 IP 地址转换为 VPC 里面的私网 IP 地址,通过这些私网 IP 地址访问到虚拟机上的负载均衡节点,然后通过负载均衡节点转发到 API 网关的节点。
- 网关节点的外网网口是带公网 IP 地址的,里面有一个虚拟网关转发模块,还会有一个 OVS,将私网 IP 地址放到 VXLAN 隧道里面,转发到虚拟机上,从而实现外网和虚拟机网络之间的互通。
- 不同的可用区之间,通过核心交换机连在一起,核心交换机之外是边界路由器。在华北、华东、华南同样也部署了一整套,每个地区都创建了 VPC,这就需要有一种机制将 VPC 连接到一起。
- 云平台一般会提供硬件的 VPC 互连的方式,当然也可以使用软件互连的方式,也就是使用 VPN 网关,通过 IPsec VPN 将不同地区的不同 VPC 通过 VPN 连接起来。
- 对于不同地区和不同运营商的用户,我们希望他能够就近访问到网站,而且当一个点出了故障之后,我们希望能够在不同的地区之间切换,这就需要有智能 DNS,这个也是云平台提供的。
- 对于一些静态资源,可以保持在对象存储里面,通过 CDN 下发到边缘节点,这样客户端就能尽快加载出来。
- 负载均衡也是部署在虚拟机里面的,属于 VPC。
二. 大声告诉全世界,可以到我这里买东西
当电商应用搭建完毕之后,接下来需要将如何访问到这个电商网站广播给全网。
对于多个可用区的情况,我们可以隐去计算节点的情况,将外网访问区域放大。外网 IP 是放在虚拟网关的外网网口上的,这个 IP 通过 BGP 路由协议让全世界知道。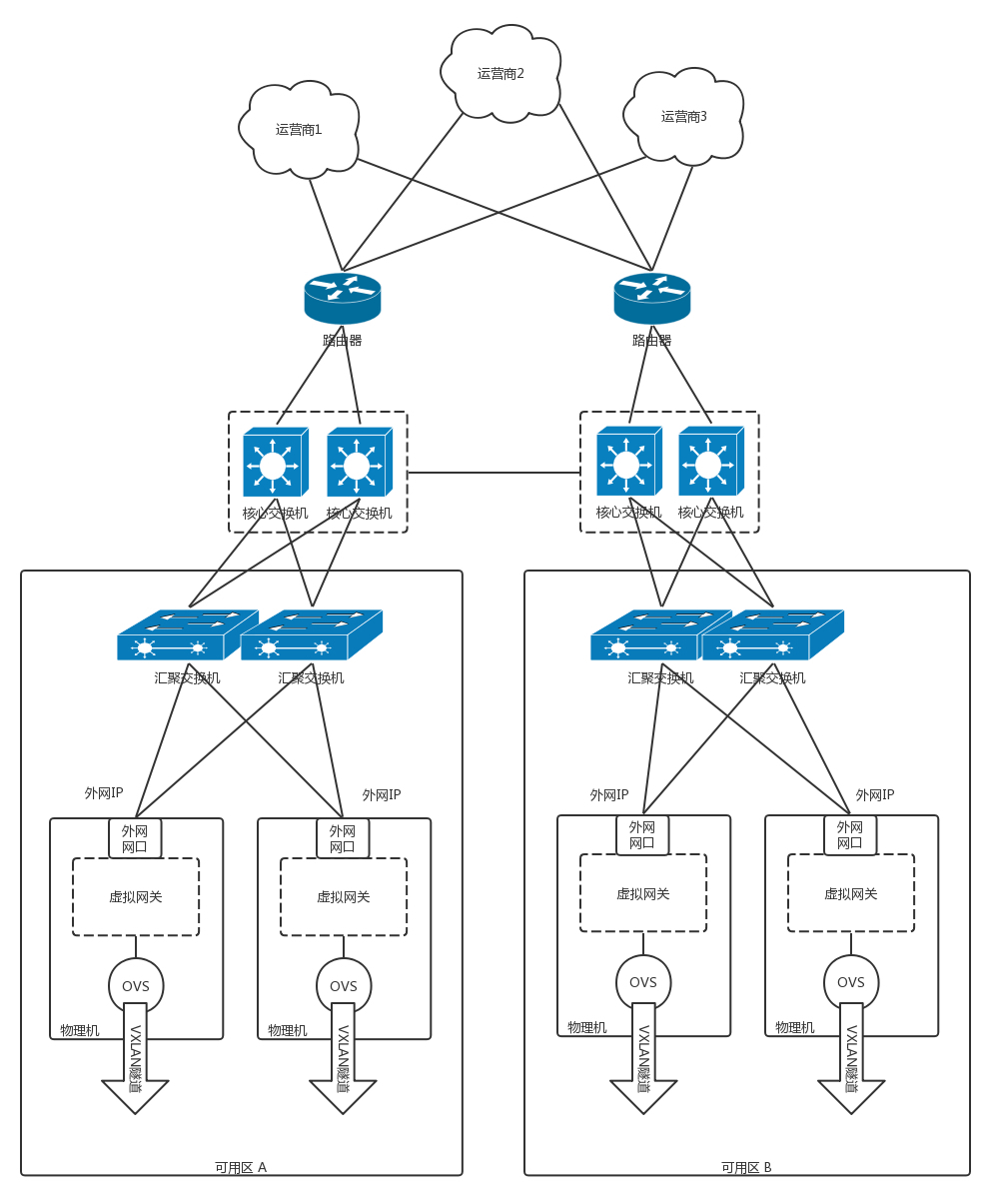
- 每个可用区都有自己的汇聚交换机,如果机器数目比较多,可以直接用核心交换机,每个 Region 也有自己的核心交换区域。
- 在核心交换外面是安全设备,然后就是边界路由器。
- 边界路由器会和多个运营商连接,从而每个运营商都能够访问到这个网站。边界路由器可以通过 BGP 协议,将自己数据中心里面的外网 IP 向外广播。
每个运营商也有很多的路由器、很多的点,于是就可以将如何到达这些 IP 地址的路由信息,广播到全国乃至全世界。
三. 打开手机来上网,域名解析得地址

- 客户的手机开机以后,在附近寻找基站 eNodeB,发送请求,申请上网。
- 基站将请求发给 MME,MME 对手机进行认证和鉴权,还会请求 HSS 看有没有钱,看看是在哪里上网。
- 当 MME 通过了手机的认证之后,开始建立隧道,建设的数据通路分两段路,其实是两个隧道。一段是从 eNodeB 到 SGW,第二段是从 SGW 到 PGW,在 PGW 之外,就是互联网。
- PGW 会为手机分配一个 IP 地址,手机上网都是带着这个 IP 地址的。
- 当在手机上面打开一个 App 的时候,首先要做的事情就是解析这个网站的域名。
- 在手机运营商所在的互联网区域里,有一个本地的 DNS,手机会向这个 DNS 请求解析 DNS。当这个 DNS 本地有缓存,则直接返回;如果没有缓存,本地 DNS 才需要递归地从根 DNS 服务器,查到.com 的顶级域名服务器,最终查到权威 DNS 服务器。
- 如果使用云平台,配置了智能 DNS 和全局负载均衡,在权威 DNS 服务中,一般是通过配置 CNAME 的方式,我们可以起一个别名,例如 vip.yourcomany.com ,然后告诉本地 DNS 服务器,让它请求 GSLB 解析这个域名,GSLB 就可以在解析这个域名的过程中,通过自己的策略实现负载均衡。
- GSLB 通过查看请求它的本地 DNS 服务器所在的运营商和地址,就知道用户所在的运营商和地址,然后将距离用户位置比较近的 Region 里面,三个负载均衡 SLB 的公网 IP 地址,返回给本地 DNS 服务器。本地 DNS 解析器将结果缓存后,返回给客户端。
- 对于手机 App 来说,可以绕过刚才的传统 DNS 解析机制,直接只要 HTTPDNS 服务,通过直接调用 HTTPDNS 服务器,得到这三个 SLB 的公网 IP 地址。
第38讲 | 知识串讲:用双十一的故事串起碎片的网络协议(中)
四. 购物之前看图片,静态资源 CDN
我们部署电商应用的时候,一般会把静态资源保存在两个地方。
- 接入层 nginx 后面的 varnish 缓存里面,一般是静态页面
- 对于比较大的、不经常更新的静态图片,会保存在对象存储里面
这两个地方的静态资源都会配置 CDN,将资源下发到边缘节点。
- 配置了 CDN 之后,权威 DNS 服务器上,会为静态资源设置一个 CNAME 别名,指向另外一个域名 cdn.com ,返回给本地 DNS 服务器。
- 本地 DNS 服务器拿到 cdn.com,继续请求 cdn.com 的权威 DNS 服务器。这是 CDN 自己的权威 DNS 服务器。
- 在 cdn.com 的权威服务器上,还是会设置一个 CNAME,指向另外一个域名,也即 CDN 网络的全局负载均衡器。
- 本地 DNS 服务器去请求 CDN 的全局负载均衡器解析域名,全局负载均衡器会为用户选择一台合适的缓存服务器提供服务,将 IP 返回给客户端,客户端去访问这个边缘节点,下载资源。缓存服务器响应用户请求,将用户所需内容传送到用户终端。
- 如果这台缓存服务器上并没有用户想要的内容,那么这台服务器就要向它的上一级缓存服务器请求内容,直至追溯到网站的源服务器,将内容拉到本地。
五. 看上宝贝点下单,双方开始建连接
电商网站会对下单的情况提供 RESTful 的下单接口,而对于下单这种需要保密的操作,需要通过 HTTPS 协议进行请求。
在所有这些操作之前,首先要做的事情是建立连接。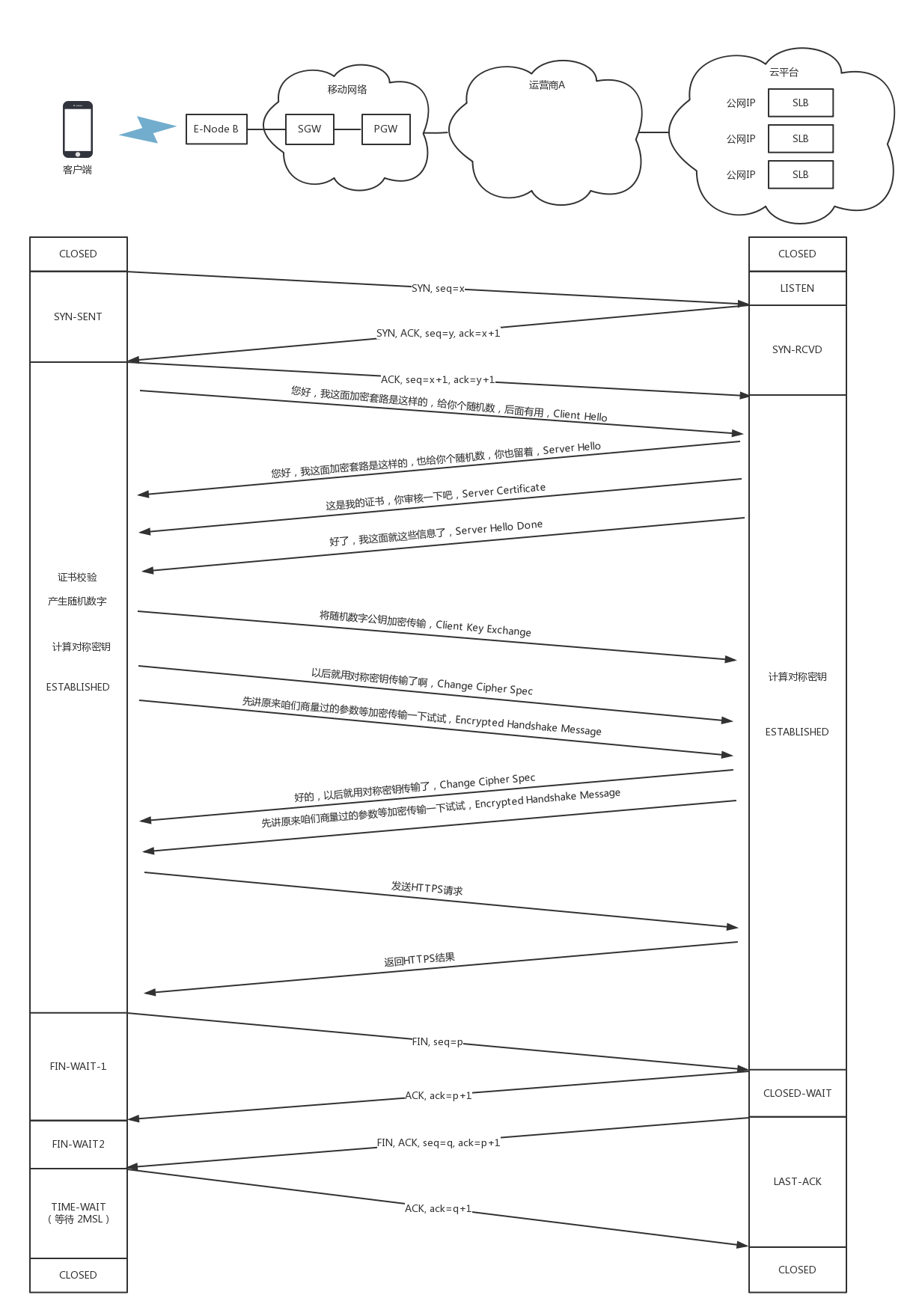
- HTTPS 协议是基于 TCP 协议的,因而要先建立 TCP 的连接。
在这个例子中,TCP 的连接是从手机上的 App 和负载均衡器 SLB 之间的。
- 一开始,客户端和服务端都处于 CLOSED 状态。
- 服务端先主动监听某个端口,处于 LISTEN 状态。
- 客户端主动发起连接 SYN,之后处于 SYN-SENT 状态。
- 服务端收到发起的连接,返回 SYN,并且 ACK 客户端的 SYN,之后处于 SYN-RCVD 状态。
- 客户端收到服务端发送的 SYN 和 ACK 之后,发送 ACK 的 ACK,之后处于 ESTABLISHED 状态。
- 服务端收到 ACK 的 ACK 之后,处于 ESTABLISHED 状态。至此,TPC 层连接简历完毕。
- 当 TCP 层的连接建立完毕之后,接下来轮到HTTPS 层建立连接了,在 HTTPS 的交换过程中,TCP 层始终处于 ESTABLISHED。
- 客户端会发送 Client Hello 消息到服务器,用明文传输 TLS 版本信息、加密套件候选列表、压缩算法候选列表等信息。还会有一个随机数,在协商对称密钥的时候使用。
- 服务器会返回 Server Hello 消息,告诉客户端,服务器选择使用的协议版本、加密套件、压缩算法等。这也有一个随机数,用于后续的密钥协商。
- 服务器发送 Server Hello Done,包含一个服务器端的证书。
- 客户端需要验证这个证书,于是从自己信任的 CA 仓库中,拿 CA 的证书里面的公钥去解密电商网站的证书。如果能够成功,则说明电商网站是可信的。这个过程中,你可能会不断往上追溯 CA、CA 的 CA、CA 的 CA 的 CA,直到一个授信的 CA。
- 证书验证完毕之后,客户端计算产生随机数字 Pre-master,发送 Client Key Exchange,用证书中的公钥加密,再发送给服务器,服务器可以通过私钥解密出来。
- 接下来,无论是客户端还是服务器,都有了三个随机数,分别是:自己的、对端的,以及刚生成的 Pre-Master 随机数。通过这三个随机数,可以在客户端和服务器产生相同的对称密钥。
- 客户端发送 Change Cipher Spec,声明之后的通信采用协商的通信密钥和加密算法进行加密通信。
- 然后客户端发送一个 Encrypted Handshake Message,将已经商定好的参数等,采用协商密钥进行加密,发送给服务器用于数据与握手验证。
- 服务器也可以发送 Change Cipher Spec,确认之后的通信规则,并且也发送 Encrypted Handshake Message 消息。至此,HTTPS 连接建立完毕。
六. 发送下单请求网络包,西行需要出网关
当客户端和服务端之间建立了连接后,接下来就要发送下单请求的网络包了。
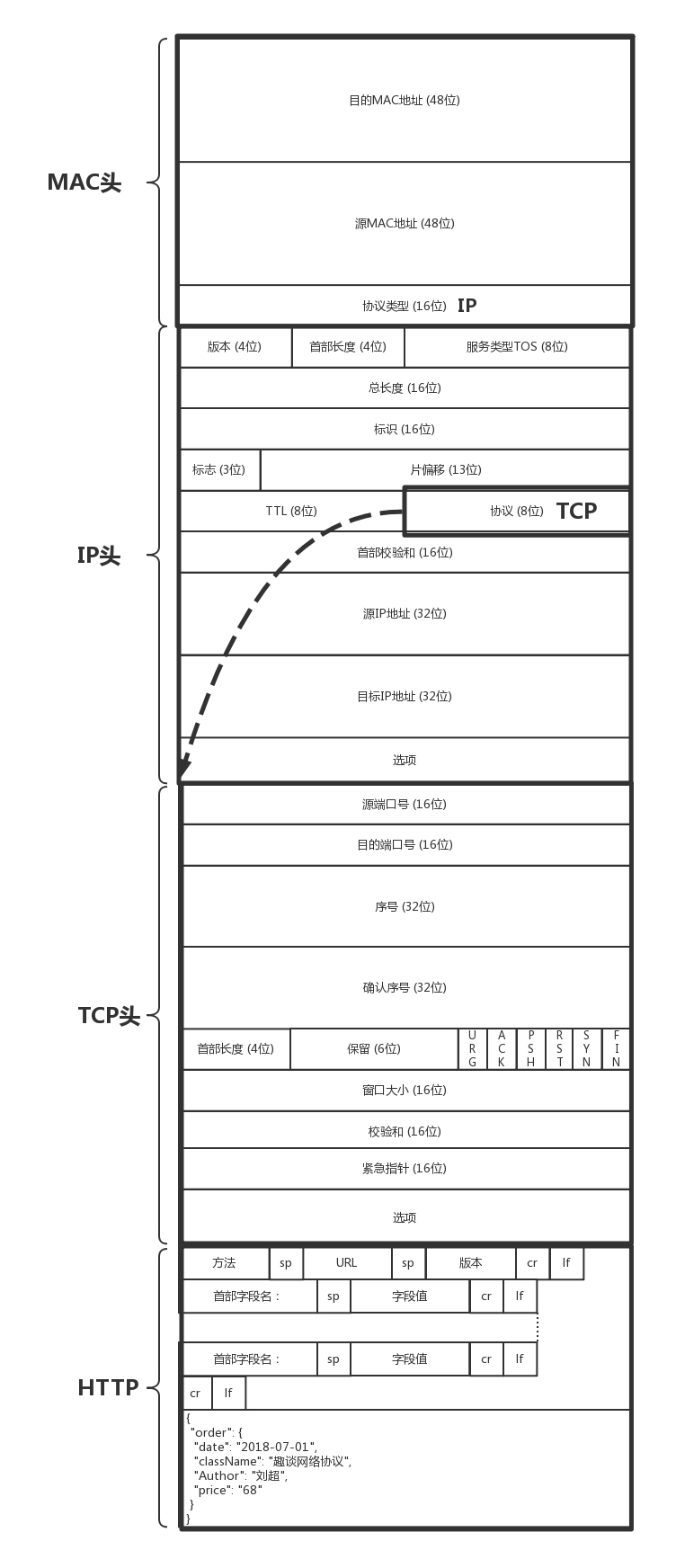
- 在用户层发送的是 HTTP 的网络包,因为服务端提供的是 RESTful API,因而 HTTP 层发送的就是一个请求。首先组装 HTTP 报文。
1
2
3
4
5
6
7
8
9
10
11
12
13POST /purchaseOrder HTTP/1.1
Host: www.geektime.com
Content-Type: application/json; charset=utf-8
Content-Length: nnn
{
"order": {
"date": "2018-07-01",
"className": " 趣谈网络协议 ",
"Author": " 刘超 ",
"price": "68"
}
}- 请求行
- URL 是 www.geektime.com/purchaseOrder
- 版本为 HTTP 1.1
- 请求的类型为 POST
- 首部
- Content-Type 指明正文的格式,这里设置为 json,编码 utf-8
- 还有其他的首部 key-value 参数,这里略去
- 正文实体
- 这里是一个 JSON 字符串,因为我们在首部中指明了正文格式为 json。
- 里面通过文本的形式描述了,要买一个课程,作者是谁,多少钱。
- 请求行
- HTTP 请求的报文组装好了,接下来浏览器或者移动 App 会把它交给下一层 TCP 传输层。
- 交付传输层即通过 Socket 进行程序设计。
- 浏览器端已有 Socket 实现,直接调用即可。
- 移动 APP 端,一般会用一个 HTTP 的客户端工具来发送,并且帮你封装好。
- Socket 会将数据封装为二进制流,交付 TCP 层。TCP 层会把二进制流变成一个一个的报文段发送给服务器。
- 在 TCP 头里面,会有源端口号和目标端口号,目标端口号一般是服务端监听的端口号,源端口号在手机端,往往是随机分配一个端口号。这个端口号在客户端和服务端用于区分请求和返回,发给那个应用。
- 交付传输层即通过 Socket 进行程序设计。
- 接下来是 IP 层
- 在 IP 头里面,包含源地址与目标地址。
- 对于手机来说,源地址是 PGW 给这个手机分配的 IP 地址,目标地址则是云平台的负载均衡器的外网 IP 地址。
- 在 IP 层,客户端需要查看目标地址和自己是否是在同一个局域网,计算是否是同一个网段,往往需要通过 CIDR 子网掩码来计算。
- 对于这个下单场景,目标 IP 和源 IP 不会在同一个网段,因而需要发送到默认的网关。一般通过 DHCP 分配 IP 地址的时候,同时配置默认网关的 IP 地址。
- 在 IP 头里面,包含源地址与目标地址。
- 最后是 MAC 层
- 客户端发送 ARP 协议,来获取网关的 MAC 地址,然后将网关 MAC 作为目标 MAC,自己的 MAC 作为源 MAC,放入 MAC 头,发送出去。
第39讲 | 知识串讲:用双十一的故事串起碎片的网络协议(下)
七. 一座座城池一道道关,流控拥塞与重传
对于手机来讲,默认的网关在 PGW 上。在移动网络里面,从手机到 SGW,到 PGW 是有一条隧道的。也有相应的隧道协议。
- 从手机发送出来的时候,网络包的结构为:
- 源 MAC:手机也即 UE 的 MAC
- 目标 MAC:网关 PGW 上面的隧道端点的 MAC
- 源 IP:UE 的 IP 地址
- 目标 IP:SLB 的公网 IP 地址
- 网络包进入手机端与 SGW 的隧道,封装隧道协议,因而网络包的格式为:
- 外层源 MAC:E-NodeB 的 MAC
- 外层目标 MAC:SGW 的 MAC
- 外层源 IP:E-NodeB 的 IP
- 外层目标 IP:SGW 的 IP
- 内层源 MAC:手机也即 UE 的 MAC
- 内层目标 MAC:网关 PGW 上面的隧道端点的 MAC
- 内层源 IP:UE 的 IP 地址
- 内层目标 IP:SLB 的公网 IP 地址
- 网络包抵达 SGW,进入 SGW 到 PGW 的隧道,因而网络包的格式为:
- 外层源 MAC:SGW 的 MAC
- 外层目标 MAC:PGW 的 MAC
- 外层源 IP:SGW 的 IP
- 外层目标 IP:PGW 的 IP
- 内层源 MAC:手机也即 UE 的 MAC
- 内层目标 MAC:网关 PGW 上面的隧道端点的 MAC
- 内层源 IP:UE 的 IP 地址
- 内层目标 IP:SLB 的公网 IP 地址
- 在 PGW 的隧道端点将包解出来,然后转发出去。一般在 PGW 出外部网络的路由器上,会部署 NAT 服务,将手机的 IP 地址转换为公网 IP 地址,当请求返回的时候,再 NAT 回来。因而在 PGW 之后,会将网络包发送至 NAT 网关,网络包的格式为:
- 源 MAC:PGW 出口的 MAC
- 目标 MAC:NAT 网关的 MAC
- 源 IP:UE 的 IP 地址
- 目标 IP:SLB 的公网 IP 地址
- 在 NAT 网关,需要穿越一个一个的 AS,通过各种路由一次一次的转发,最终抵达目标,也即 SLB 的公网 IP 地址。这里以 NAT 发出到第一个边界路由器为例,网络包的格式变成:
- 源 MAC:NAT 网关的 MAC
- 目标 MAC:A2 路由器的 MAC
- 源 IP:UE 的公网 IP 地址
- 目标 IP:SLB 的公网 IP 地址
- 出了 NAT 网关,就从核心网到达了互联网。之后会通过一个一个的路由器不停的下一跳,跨越一个一个的 AS,最终抵达目标。
- AS 分类
- 公网中,每一个运营商的网络成为自治系统 AS。每个自治系统都有边界路由器,通过它和外面的世界建立联系。
- 对于云平台来讲,它可以被称为 Multihomed AS,有多个连接连到其他的 AS,但是大多拒绝帮其他的 AS 传输包。
- 一些大公司的网络,对于运营商来说,它可以被称为 Transit AS,有多个连接连到其他的 AS,并且可以帮助其他的 AS 传输包,比如主干网。
- 在路由器之间需要通过 BGP 协议实现,BGP 又分为两类,eBGP 和 iBGP。
- 自治系统之间、边界路由器之间使用 eBGP 广播路由。内部网络也需要访问其他的自治系统。
- 边界路由器通过运行 iBGP 将 BGP 学习到的路由导入到内部网络,使内部的路由器能够找到到达外网目的地最好的边界路由器。
- 对于我们这个例子,它的跳转路线如下:
- NAT 网关的下一跳是 A2,也即将 A2 的 MAC 地址放在目标 MAC 地址中。
- 到达 A2 之后,从路由表中找到下一跳是路由器 C1,于是将目标 MAC 换成 C1 的 MAC 地址。
- 到达 C1 之后,找到下一跳是 C2,将目标 MAC 地址设置为 C2 的 MAC。
- 到达 C2 后,找到下一跳是云平台的边界路由器,于是将目标 MAC 设置为边界路由器的 MAC 地址。
这一路,都是只换 MAC,不换目标 IP 地址。这就是所谓下一跳的概念。
- 在云平台的边界路由器,会将下单的包转发进来,经过核心交换,汇聚交换,到达外网网关节点上的 SLB 的公网 IP 地址。
- AS 分类
在整个传输过程中,很可能出现错误,因此需要通过各种方式来保证其可靠性。
- 包在传输过程中可能因为某些原因失败,因此需要 TCP 的重发机制保证包完整发送至目标。而重发规则的制定则是通过 TCP 的滑动窗口协议。
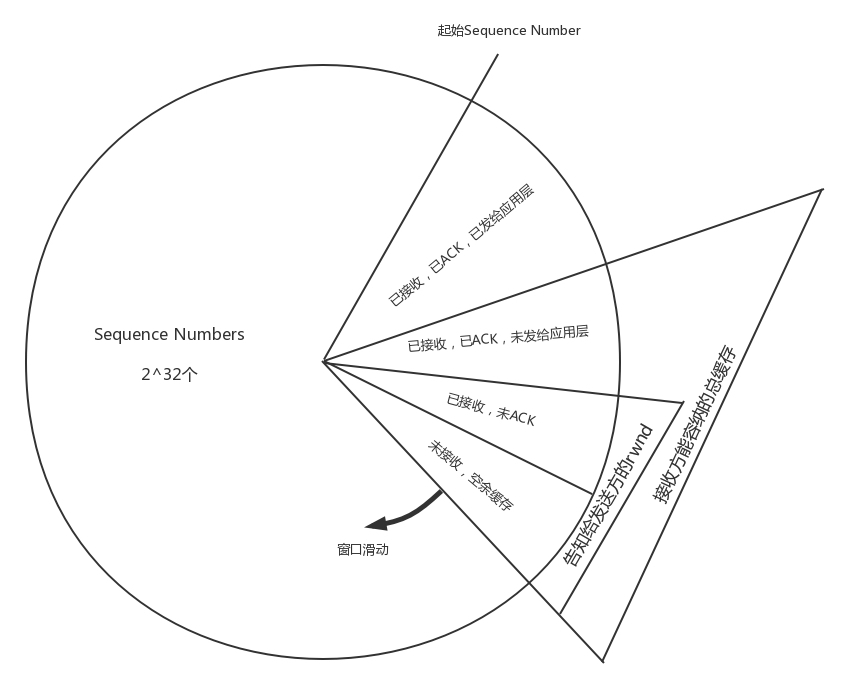
- 整个 TCP 的发送,一开始会协商一个 Sequence Number,从这个 Sequence Number 开始,每个包都有编号。滑动窗口将接收方的网络包分成四个部分:
- 已经接收,已经 ACK,已经交给应用层的包
- 已经接收,已经 ACK,未发送给应用层
- 已经接收,尚未发送 ACK
- 未接收,尚有空闲的缓存区域
- 如果发送方超过一定的时间没有收到 ACK,就会重新发送。只有 TCP 层 ACK 过的包,才会发给应用层,并且只会发送一份,对于下单的场景,应用层是 HTTP 层。
- 整个 TCP 的发送,一开始会协商一个 Sequence Number,从这个 Sequence Number 开始,每个包都有编号。滑动窗口将接收方的网络包分成四个部分:
- TCP 连接可能因为某种原因中断,这个时候手机把所有的动作重新做一遍,建立一个新的 TCP 连接,在 HTTP 层调用两次 RESTful API。这个时候可能会导致两遍下单的情况,因而 RESTful API 需要实现幂等。
八. 从数据中心进网关,公网 NAT 成私网
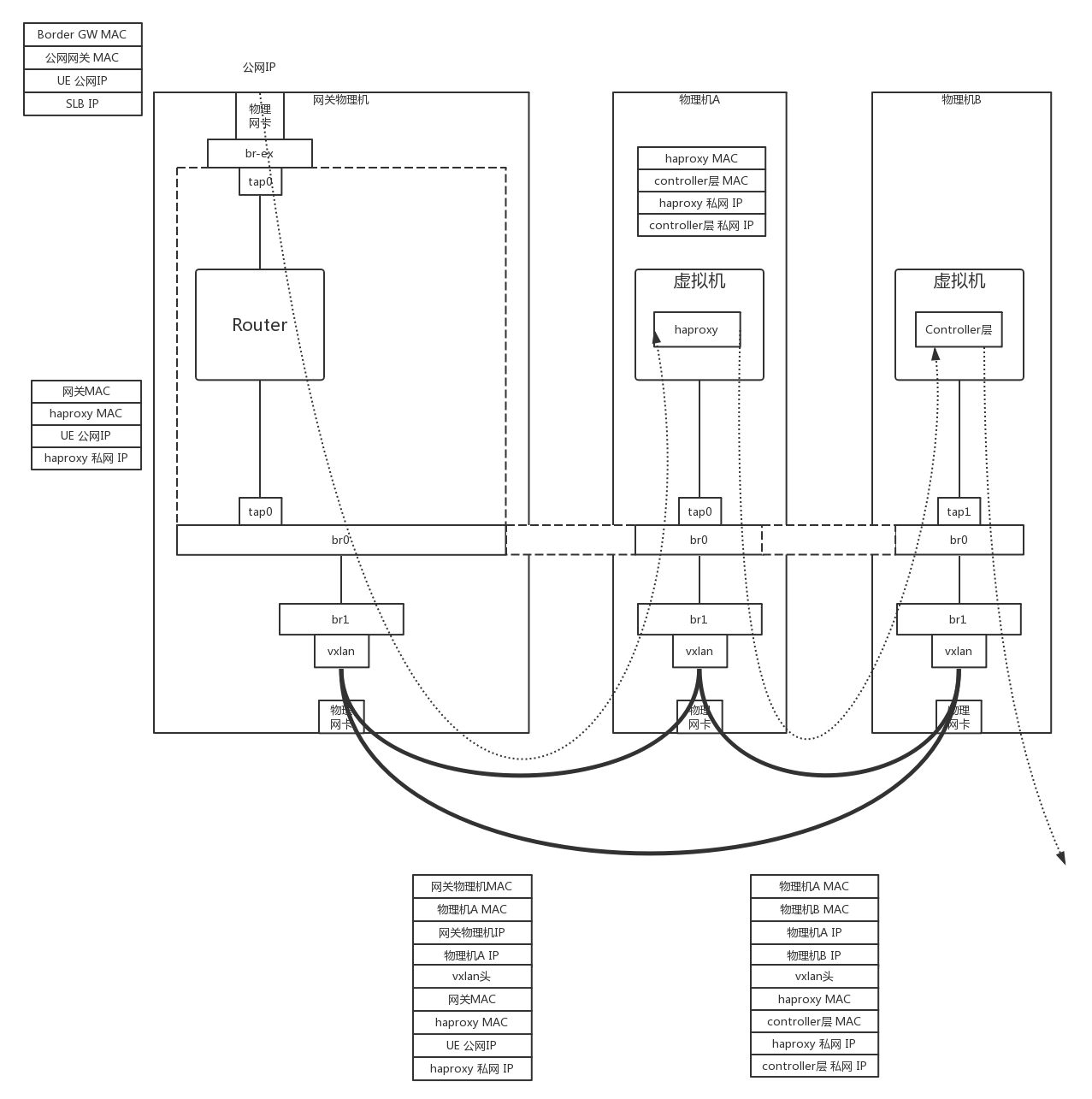
- 包从手机端经历千难万险,终于到了 SLB 的公网 IP 所在的公网网口。由于匹配上了 MAC 地址和 IP 地址,因而将网络包收了进来。
- 在虚拟网关节点的外网网口上,会有一个 NAT 规则,将公网 IP 地址转换为 VPC 里面的私网 IP 地址,这个私网 IP 地址就是 SLB 的 HAProxy 所在的虚拟机的私网 IP 地址。
- 为了承载比较大的吞吐量,虚拟网关节点会有多个,物理网络会将流量分发到不同的虚拟网关节点。
- 同样 HAProxy 也会是一个大的集群,虚拟网关会选择某个负载均衡节点,将某个请求分发给它,负载均衡之后是 Controller 层,也是部署在虚拟机里面的。
- 当网络包里面的目标 IP 变成私有 IP 地址之后,虚拟路由会查找路由规则,将网络包从下方的私网网口发出来。这个时候包的格式为:
- 源 MAC:网关 MAC
- 目标 MAC:HAProxy 虚拟机的 MAC
- 源 IP:UE 的公网 IP
- 目标 IP:HAProxy 虚拟机的私网 IP
九. 进入隧道打标签,RPC 远程调用下单
- 在虚拟路由节点上,也会有 OVS,将网络包封装在 VXLAN 隧道里面,VXLAN ID 就是给你的租户创建 VPC 的时候分配的。包的格式为:
- 外层源 MAC:网关物理机 MAC
- 外层目标 MAC:物理机 A 的 MAC
- 外层源 IP:网关物理机 IP
- 外层目标 IP:物理机 A 的 IP
- 内层源 MAC:网关 MAC
- 内层目标 MAC:HAProxy 虚拟机的 MAC
- 内层源 IP:UE 的公网 IP
- 内层目标 IP:HAProxy 虚拟机的私网 IP
- 在物理机 A 上,OVS 会将包从 VXLAN 隧道里面解出来,发给 HAProxy 所在的虚拟机。
- HAProxy 所在的虚拟机发现 MAC 地址匹配,目标 IP 地址匹配,就根据 TCP 端口,将包发给 HAProxy 进程,因为 HAProxy 是在监听这个 TCP 端口的。
- HAProxy 就是这个 TCP 连接的服务端,客户端是手机。对于 TCP 的连接状态、滑动窗口等,都是在 HAProxy 上维护的。
- 在这里 HAProxy 是一个四层负载均衡,也即它只解析到 TCP 层,里面的 HTTP 协议它不关心,就将请求转发给后端的多个 Controller 层的一个。HAProxy 发出去的网络包就认为 HAProxy 是客户端了,看不到手机端了。网络包格式如下:
- 源 MAC:HAProxy 所在虚拟机的 MAC
- 目标 MAC:Controller 层所在虚拟机的 MAC
- 源 IP:HAProxy 所在虚拟机的私网 IP
- 目标 IP:Controller 层所在虚拟机的私网 IP
- 这个包发出去之后,会被物理机上的 OVS 放入 VXLAN 隧道里面,网络包格式为:
- 外层源 MAC:物理机 A 的 MAC
- 外层目标 MAC:物理机 B 的 MAC
- 外层源 IP:物理机 A 的 IP
- 外层目标 IP:物理机 B 的 IP
- 内层源 MAC:HAProxy 所在虚拟机的 MAC
- 内层目标 MAC:Controller 层所在虚拟机的 MAC
- 内层源 IP:HAProxy 所在虚拟机的私网 IP
- 内层目标 IP:Controller 层所在虚拟机的私网 IP
- 在物理机 B 上,OVS 会将包从 VXLAN 隧道里面解出来,发给 Controller 层所在的虚拟机。
- Controller 层所在的虚拟机发现 MAC 地址匹配,目标 IP 地址匹配,就根据 TCP 端口,将包发给 Controller 层的进程,因为它在监听这个 TCP 端口。
- 在 HAProxy 和 Controller 层之间,维护一个 TCP 的连接。
- Controller 层收到包之后,它是关心 HTTP 里面是什么的,于是解开 HTTP 的包,发现是一个 POST 请求,内容是下单购买一个课程。
十. 下单扣减库存优惠券,数据入库返回成功
下单是一个复杂的过程,因而往往在组合服务层会有一个专门管理下单的服务,Controller 层会通过 RPC 调用这个组合服务层。
假设我们使用的是 Dubbo。
- Controller 层需要读取注册中心,将下单服务的进程列表拿出来,选出一个来调用。
- Dubbo 中默认的 RPC 协议是 Hessian2。Hessian2 将下单的远程调用序列化为二进制进行传输。
- Controller 层和下单服务之间,使用了 Netty 的网络传输框架。有了 Netty,就不用自己编写复杂的异步 Socket 程序了。Netty 使用的方式,是 Socket 结构中一个 IO 多路复用,等待通知的方式。
- Socket 基于 TCP 层发送网络包,下层还是需要封装上 IP 头和 MAC 头。如果跨物理机通信,还是需要封装的外层的 VXLAN 隧道里面。当然底层的这些封装,Netty 都不感知,它只要做好它的异步通信即可。
- 在 Netty 的服务端,也即下单服务中,收到请求后,先用 Hessian2 的格式进行解压缩。然后将请求分发到线程中进行处理,在线程中,会调用下单的业务逻辑。
下单的业务逻辑比较复杂,往往要调用基础服务层里面的库存服务、优惠券服务等,将多个服务调用完毕,才算下单成功。
- 下单服务调用库存服务和优惠券服务,也是通过 Dubbo 的框架,通过注册中心拿到库存服务和优惠券服务的列表,然后选一个调用。
- 调用的时候,统一使用 Hessian2 进行序列化,使用 Netty 进行传输,底层如果跨物理机,仍然需要通过 VXLAN 的封装和解封装。
- 当下单更新到分布式数据库中之后,整个下单过程才算真正告一段落。
协议专栏特别福利 | 答疑解惑第一期
当网络包到达一个城关的时候,可以通过路由表得到下一个城关的 IP 地址,直接通过 IP 地址找就可以了,为什么还要通过本地的 MAC 地址呢?
在网络包里,有源 IP 地址和目标 IP 地址、源 MAC 地址和目标 MAC 地址。从路由表中取得下一跳的 IP 地址后,应该把这个地址放在哪里呢?如果放在目标 IP 地址里面,到了城关,谁知道最终的目标在哪里呢?所以要用 MAC 地址。
所谓的下一跳,看起来是 IP 地址,其实是要通过 ARP 得到 MAC 地址,将下一跳的 MAC 地址放在目标 MAC 地址里面。
MAC 地址可以修改吗?
MAC(Media Access Control,介质访问控制)地址,也叫硬件地址,长度是 48 比特(6 字节),由 16 进制的数字组成,分为前 24 位和后 24 位。
- 前 24 位叫作组织唯一标志符(Organizationally Unique Identifier,OUI),是由 IEEE 的注册管理机构给不同厂家分配的代码,用于区分不同的厂家。
- 后 24 位是厂家自己分配的,称为扩展标识符。同一个厂家生产的网卡中 MAC 地址后 24 位是不同的。
MAC 本来设计为唯一性的,但是后来设备越来越多,而且还有虚拟化的设备和网卡,有很多工具可以修改,就很难保证不冲突了。但是至少应该保持一个局域网内是唯一的。这样,一台机器启动的时候,就能够在没有 IP 地址的情况下,先用 MAC 地址进行通信,获得 IP 地址。
MAC 地址是工作在一个局域网中的,因而即便出现了冲突,网络工程师也能够在自己的范围内很快定位并解决这个问题。
TCP 重试有没有可能导致重复下单?
答案是不会的。因为 TCP 层收到了重复包之后,TCP 层自己会进行去重,发给应用层、HTTP 层。还是一个唯一的下单请求,所以不会重复下单。
但仍有一些情况会导致重复下单
- TCP 断线重连会导致重复下单,这样会重新发送应用层的请求,也即 HTTP 的请求会重新发送一遍。
- 请求被黑客拦截并重放会导致重复下单,这在 HTTPS 层可以有很多种机制,例如通过 Timestamp 和 Nonce 随机数联合起来,然后做一个不可逆的签名来保证。
如果服务端设计的是无状态的,它记不住上一次已经发送了一次请求。如果处理不好,就会导致重复下单,这就需要服务端除了实现无状态,还需要根据传过来的订单号实现幂等,同一个订单只处理一次。
IP 地址和 MAC 地址的关系?
IP 是有远程定位功能的,MAC 是没有远程定位功能的,只能通过本地 ARP 的方式找到。
如果最后一跳的时候,IP 改变了怎么办?
对于 IP 层来讲,当包到达最后一跳的时候,原来的 IP 不存在了。比如网线拔掉了,或者服务器直接宕机了,则 ARP 就找不到了,所以这个包就会发送失败了。对于 IP 层的工作就结束了。但是 IP 层之上还有 TCP 层,TCP 会重试的,包还是会重新发送。
- 如果服务器没有启动起来,超过一定的次数,最终放弃。
- 如果服务器重启了,IP 还是原来的 IP 地址,这个时候 TCP 重新发送的一个包的时候,ARP 是能够得到这个地址的,因而会发到这台机器上来,但是机器上面没有启动服务端监听那个端口,于是会发送 ICMP 端口不可达。
- 如果服务器重启了,服务端也重新启动了,也在监听那个端口了,这个时候 TCP 的服务端由于是新的,Sequence Number 根本对不上,说明不是原来的连接,会发送 RST。
按照 Sequence Number 的生成算法,是不存在对的上的可能的。
- 有一个非常特殊的方式,就是虚拟机的热迁移,从一台物理机迁移到另外一台物理机,IP 不变,MAC 不变,内存也拷贝过去,Sequence Number 在内存里面也保持住了,在迁移的过程中会丢失一两个包,但是从 TCP 来看,最终还是能够连接成功的。
ARP 协议属于哪一层?
ARP 属于哪个层,一直是有争议的。比如《TCP/IP 详解》把它放在了二层和三层之间,但是既然是协议,只要大家都遵守相同的格式、流程就可以了,在实际应用的时候,不会有歧义的。
唯一有歧义的是参加各种考试,让你做选择题,ARP 属于哪一层?平时工作中咱不用纠结这个。
为什么要分层?
其实这是一个架构设计的通用问题,不仅仅是网络协议的问题。一旦涉及到复杂的逻辑,或者软件需求需要经常变动,一般都会通过分层来解决问题。
什么情况下会有下层没上层?
有时候我们自己写应用的时候,不一定是直接调用应用层协议的接口,例如 HTTP 等,而是自己写 Socket 编程,来约定应用层的协议。再如,ping 也是一个应用,但是它没有用传输层的协议,而是用了 ICMP 的协议。
协议专栏特别福利 | 答疑解惑第二期
你知道 net-tools 和 iproute2 的“历史”故事吗?
- net-tools
- net-tools 起源于 BSD,自 2001 年起,Linux 社区已经对其停止维护
- net-tools通过procfs(/proc)和ioctl系统调用去访问和改变内核网络配置
- net-tools中工具的名字比较杂乱
- iproute2
- iproute2 旨在取代 net-tools,并提供了一些新功能
- iproute2则通过netlink套接字接口与内核通讯
- iproute2则相对整齐和直观,基本是ip命令加后面的子命令
一些Linux发行版已经停止支持net-tools,只支持iproute2。虽然取代意图很明显,但是这么多年过去了,net-tool依然还在被广泛使用,最好还是两套命令都掌握吧。
网络号、IP 地址、子网掩码和广播地址的先后关系是什么?
一般选择来说,在一个小的局域网环境下,私有地址使用 192.168.0.0/24 就可以了。
- 先有的是网络号。192.168.0 就是网络号。
- 有了网络号,子网掩码同时也就有了,就是前面都是网络号的是 1,其他的是 0。
- 有了网络号,广播地址也有了,除了网络号之外都是 1。
- 最后确定的是 IP 地址。当规划完网络的时候,一般这个网络里面的第一个、第二个地址被默认网关 DHCP 服务器占用,你自己创建的机器,只要和其他的不冲突就可以了,当然你也可以让 DHCP 服务自动配置。
组播和广播的意义和原理是什么?
- 广播相对比较简单
- MAC 层的广播为 ff:ff:ff:ff:ff:ff
- IP 层指向子网的广播地址为主机号为全 1 且有特定子网号的地址。
- 组播复杂一些
- MAC 层中,当地址中最高字节的最低位设置为 1 时,表示该地址是一个组播地址,用十六进制可表示为 01:00:00:00:00:00
- IP 层中,组播地址为 D 类 IP 地址,当 IP 地址为组播地址的时候,有一个算法可以计算出对应的 MAC 层地址。
MTU 1500 的具体含义是什么?
MTU(Maximum Transmission Unit,最大传输单元)是二层的一个定义。以以太网为例,MTU 为 1500 个 Byte,前面有 6 个 Byte 的目标 MAC 地址,6 个 Byte 的源 MAC 地址,2 个 Byte 的类型,后面有 4 个 Byte 的 CRC 校验,共 1518 个 Byte。
- 在 IP 层,一个 IP 数据报在以太网中传输。如果它的长度大于该 MTU 值,就要进行分片传输。如果不允许分片 DF,就会发送 ICMP 包,这个在ICMP那一节讲过。
- 在 TCP 层有个 MSS(Maximum Segment Size,最大分段大小),它等于 MTU 减去 IP 头,再减去 TCP 头。即在不分片的情况下,TCP 里面放的最大内容。
- 在 HTTP 层看来,它的 body 没有限制,而且在应用层看来,下层的 TCP 是一个流,可以一直发送,但其实是会被分成一个个段的。
PXE 协议可以用来安装操作系统,但是如果每次重启都安装操作系统,就会很麻烦。你知道如何使得第一次安装操作系统,后面就正常启动吗?
一般如果咱们手动安装一台电脑的时候,都是有启动顺序的。在通过 PXE 安装操作系统后,再改为硬盘启动,就没有问题了。
在 DHCP 网络里面,手动配置 IP 地址会冲突吗?
- IP 地址会冲突
- 在一个 DHCP 网络里面,如果某一台机器手动配置了一个 IP 地址,并且在 DHCP 管理的网段里的话,DHCP 服务器是会将这个地址分配给其他机器的。一旦分配了,ARP 的时候,就会收到两个应答,IP 地址就冲突了。
- DHCP 的客户端和服务器都可以添加相应的机制来检测冲突。
- 如果由客户端来检测冲突,一般情况是,客户端在接受分配的 IP 之前,先发送一个 ARP,看是否有应答,有就说明冲突了,于是发送一个 DHCPDECLINE,放弃这个 IP 地址。
- 如果由服务器来检测冲突,DHCP 服务器会发送 ping,来看某个 IP 是否已经被使用。如果被使用了,它就不再将这个 IP 分配给其他的客户端了。
DHCP 的 Offer 和 ACK 应该是单播还是广播呢?
这取决于客户端的协议栈的能力
- 如果没配置好 IP,就不能接收单播的包,那就将 BROADCAST 设为 1,以广播的形式进行交互。
- 如果客户端的协议栈实现很厉害,即便是没有配置好 IP,仍然能够接受单播的包,那就将 BROADCAST 位设置为 0,就以单播的形式交互。
DHCP 如何解决内网安全问题?
DHCP 协议的设计是基于内网互信的基础来设计的,而且是基于 UDP 协议。但这里面的确是有风险的。
- 两种风险
- 例如一个普通用户无意地或者恶意地安装一台 DHCP 服务器,发放一些错误或者冲突的配置。
- 再如,有恶意的用户发出很多的 DHCP 请求,让 DHCP 服务器给他分配大量的 IP。
- 两种风险对应的解决方案
- 对于第一种情况,DHCP 服务器和二层网络都是由网管管理的,可以在交换机配置只有来自某个 DHCP 服务器的包才是可信的,其他全部丢弃。如果有 SDN,或者在云中,非法的 DHCP 包根本就拦截到虚拟机或者物理机的出口。
- 对于第二种情况,一方面进行监控,对 DHCP 报文进行限速,并且异常的端口可以关闭,一方面还是 SDN 或者在云中,除了被 SDN 管控端登记过的 IP 和 MAC 地址,其他的地址是不允许出现在虚拟机和物理机出口的,也就无法模拟大量的客户端。
在二层中我们讲了 ARP 协议,即已知 IP 地址求 MAC;还有一种 RARP 协议,即已知 MAC 求 IP 的,你知道它可以用来干什么吗?
之前有无盘工作站,即没有硬盘的机器,无法持久化 IP 到本地,但有网卡,所以可以通过 RARP 协议来获取 IP 地址到本地。
RARP 可以用于局域网管理员想指定机器 IP(与机器绑定,不可变),又不想每台机器去设置静态 IP 的情况。可以在 RARP 服务器上配置 MAC 与 IP 对应的 ARP 表。
但获取每台机器的 MAC 地址也挺麻烦的,所以现在这个协议用的已经不多了,都换用 BOOTP 或 DHCP。
如果一个局域网里面有多个交换机,ARP 广播的模式会出现什么问题呢?
多个交换机可能形成环,导致广播不停被转发,形成广播风暴
STP 协议能够很好地解决环路问题,但是也有它的缺点,你能举几个例子吗?
STP 的主要问题在于,当拓扑发生变化,新的配置消息要经过一定的时延才能传播到整个网络。
- 由于整个交换网络只有一棵生成树,在网络规模比较大的时候会导致较长的收敛时间,拓扑改变的影响面也较大
- 当链路被阻塞后将不承载任何流量,造成了极大带宽浪费。
在 MAC 地址已经学习的情况下,ARP 会广播到没有 IP 的物理段吗?
这里 ARP 的目标地址是广播的,所以无论是否进行地址学习,都会广播,而对于某个 MAC 的访问。
- 在没有地址学习的时候,是转发到所有的端口的
- 学习之后,只会转发到有这个 MAC 的端口
802.1Q VLAN 和 Port-based VLAN 有什么区别?
- Port-based VLAN 一般只在一台交换机上起作用,比如一台交换机,10 个口,1、3、5、7、9 属于 VLAN 10。1 发出的包,只有 3、5、7、9 能够收到,但是从这些口转发出去的包头中,并不带 VLAN ID。
- 802.1Q 的 VLAN,出了交换机也起作用,也就是说,一旦打上某个 VLAN,则出去的包都带这个 VLAN,也需要链路上的交换机能够识别这个 VLAN,进行转发。
协议专栏特别福利 | 答疑解惑第三期
当发送的报文出问题的时候,会发送一个 ICMP 的差错报文来报告错误,但是如果 ICMP 的差错报文也出问题了呢?
- 不发 ICMP 差错报文的一种情况就是 ICMP 的差错报文出错
- ICMP 一般认为属于网络层的,和 IP 同一层,是管理和控制 IP 的一种协议,而 UDP 和 TCP 是传输层,所以 UDP 出错可以返回 ICMP 差错报文
ping 使用的是什么网络编程接口?
咱们使用的网络编程接口是 Socket
- 对于 ping 来讲,使用的是 ICMP,创建 Socket 如下,SOCK_RAW 就是基于 IP 层协议建立通信机制:
1
socket(AF_INET, SOCK_RAW, IPPROTO_ICMP)
- 如果是 TCP,则建立下面的 Socket:
1
socket(AF_INET, SOCK_STREAM, IPPROTO_TCP)
- 如果是 UDP,则建立下面的 Socket:
1
socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP)
NAT 能建立多少连接?
SNAT 多用于内网访问外网的场景,鉴于 conntrack 是由{源 IP,源端口,目标 IP,目标端口},hash 后确定的。
- 如果内网机器很多,但是访问的是不同的外网,也即目标 IP 和目标端口很多,这样内网可承载的数量就非常大,可不止 65535 个。
- 如果内网所有的机器,都一定要访问同一个目标 IP 和目标端口,这样源 IP 如果只有一个,这样的情况下,才受 65535 的端口数目限制。
- 一种解决方法是多个源 IP
- 另一种解决方法是多个 NAT 网关,来分摊不同的内网机器访问
如果你使用的是公有云,65535 台机器,应该放在一个 VPC 里面,可以放在多个 VPC 里面,每个 VPC 都可以有自己的 NAT 网关。
公网 IP 和私网 IP 需要一一绑定吗?
- 公网 IP 是有限的,如果使用公有云,需要花钱去买。但是不是每一个虚拟机都要有一个公网 IP 的,只有需要对外提供服务的机器,也即接入层的那些 nginx 需要公网 IP
- 没有公网 IP,使用 SNAT,大家共享 SNAT 网关的公网 IP 地址,也是能够访问的外网的
路由协议要在路由器之间交换信息,这些信息的交换还需要走路由吗?不是死锁了吗?
- OSPF 是直接基于 IP 协议发送的,而且 OSPF 的包都是发给邻居的,也即只有一跳,不会中间经过路由设备。
- BGP 是基于 TCP 协议的,在 BGP peer 之间交换信息。
多线 BGP 机房是怎么回事儿?
- 前提概念
- BGP 主要用于互联网 AS 自治系统之间的互联,BGP 的最主要功能在于控制路由的传播和选择最好的路由。
- 各大运营商都具有 AS 号,全国各大网络运营商多数都是通过 BGP 协议与自身的 AS 来实现多线互联的。
- 多线 BGP 机房原理
- 使用此方案来实现多线路互联,IDC 需要在 CNNIC(中国互联网信息中心)或 APNIC(亚太网络信息中心)申请自己的 IP 地址段和 AS 号,然后通过 BGP 协议将此段 IP 地址广播到其它的网络运营商的网络中。
- 使用 BGP 协议互联后,网络运营商的所有骨干路由设备将会判断到 IDC 机房 IP 段的最佳路由,以保证不同网络运营商用户的高速访问。
都说 TCP 是面向连接的,在计算机看来,怎么样才算一个连接呢?
TCP 连接时通过三次握手建立的,四次挥手释放连接,这里的连接是指彼此可以感知到对方的存在,计算机两端表现为 socket,有对应的接受缓存和发送缓存,有相应的拥塞控制策略。
TCP 的连接有这么多的状态,你知道如何在系统中查看某个连接的状态吗?
netstat 或 lsof 命令 grep 一下 TCP 状态进行查看,例如:
1 | netstat grep establish |
TIME_WAIT 状态太多是怎么回事儿?
如果处于 TIMEWAIT 状态,说明双方建立成功过连接,而且已经发送了最后的 ACK 之后,才会处于这个状态,而且是主动发起关闭的一方处于这个状态。
如果存在大量的 TIMEWAIT,往往是因为短连接太多,不断的创建连接,然后释放连接,从而导致很多连接在这个状态,可能会导致无法发起新的连接。
起始序列号是怎么计算的,会冲突吗?
- 起始 ISN 是基于时钟的,每 4 毫秒加一,转一圈要 4.55 个小时。
- TCP 初始化序列号不能设置为一个固定值,因为这样容易被攻击者猜出后续序列号,从而遭到攻击。 RFC1948 中提出了一个较好的初始化序列号 ISN 随机生成算法。 M 是一个计时器,这个计时器每隔 4 毫秒加 1。F 是一个 Hash 算法,根据源 IP、目的 IP、源端口、目的端口生成一个随机数值。要保证 Hash 算法不能被外部轻易推算得出,用 MD5 算法是一个比较好的选择。
1
ISN = M + F (localhost, localport, remotehost, remoteport)
TCP 的 BBR 听起来很牛,你知道它是如何达到这个最优点的嘛?
- 设备缓存会导致延时?
- 假如经过设备的包都不需要进入缓存,那么速度是最快的。进入缓存且等待,等待的时间就是额外的延时。BBR 就是为了避免这些问题,即充分利用带宽,降低 buffer 占用率。
- 降低 packet 的速度,为何反而提速了?
- 标注的 TCP 拥塞算法是遇到丢包的数据时快速下降发送速度,因为算法假设丢包都是因为过程设备存满了。快速下降再重新慢启动,这个过程对于带宽来说是浪费的。
- 通过 packet 速度 - 时间的图来看,从积分上来说,BBR 充分利用带宽时发送效率才最高。
epoll 是 Linux 上的函数,那你知道 Windows 上对应的机制是什么吗?如果想实现一个跨平台的程序,你知道应该怎么办吗?
如果跨平台,推荐使用 libevent 库,它是一个事件通知库,适用于 Windows、Linux、BSD 等多种平台,内部使用 select、epoll、kqueue、IOCP 等系统调用管理事件机制。
协议专栏特别福利 | 答疑解惑第四期
QUIC 是一个精巧的协议,所以它肯定不止今天我提到的四种机制,你知道还有哪些吗?
QUIC 还有其他特性
- 快速建立连接。以 HTTPS 举例,如果使用基于 UDP 的 QUIC。
- 可以省略掉 TCP 的三次握手。
- 至于 TLS 的建立,对于 QUIC 来讲,当客户端首次发起 QUIC 连接时,会发送一个 client hello 消息,服务器会回复一个消息,里面包括 server config,类似于 TLS1.3 中的 key_share 交换。当客户端获取到 server config 以后,就可以直接计算出密钥,发送应用数据了。
- 拥塞控制。QUIC 协议当前默认使用了 TCP 协议的 CUBIC(拥塞控制算法)。
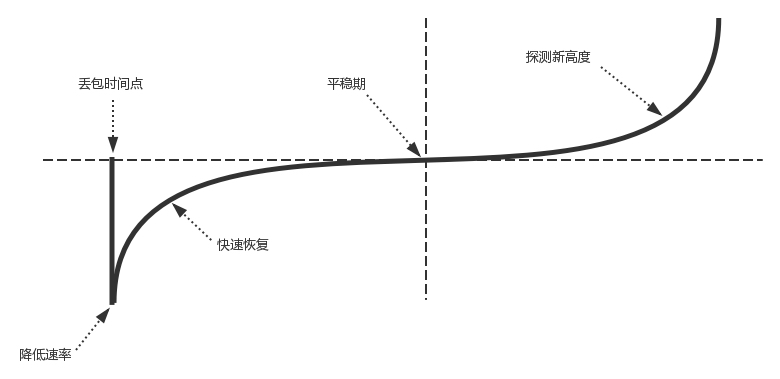
- CUBIC 的窗口增长函数仅仅取决于连续两次拥塞事件的时间间隔值,窗口增长完全独立于网络的时延 RTT。CUBIC 的窗口大小以及变化过程如图所示。
- 当出现丢包事件时,CUBIC 会记录这时的拥塞窗口大小,把它作为 Wmax。接着,CUBIC 会通过某个因子执行拥塞窗口的乘法减小,然后,沿着立方函数进行窗口的恢复。
- 从图中可以看出,一开始恢复的速度是比较快的,后来便从快速恢复阶段进入拥塞避免阶段,也即当窗口接近 Wmax 的时候,增加速度变慢;立方函数在 Wmax 处达到稳定点,增长速度为零,之后,在平稳期慢慢增长,沿着立方函数的开始探索新的最大窗口。
HTTP 的 keepalive 模式是什么样?
- 在没有 keepalive 模式下,每个 HTTP 请求都要建立一个 TCP 连接,并且使用一次之后就断开这个 TCP 连接。
- 使用 keepalive 之后,在一次 TCP 连接中可以持续发送多份数据而不会断开连接,可以减少 TCP 连接建立次数,减少 TIME_WAIT 状态连接。
- 长时间的 TCP 连接容易导致系统资源无效占用,因而需要设置正确的 keepalive timeout 时间。当一个 HTTP 产生的 TCP 连接在传送完最后一个响应后,还需要等待 keepalive timeout 秒后,才能关闭这个连接。如果这个期间又有新的请求过来,可以复用 TCP 连接。
HTTPS 协议比较复杂,沟通过程太繁复,这样会导致效率问题,那你知道有哪些手段可以解决这些问题吗?
使用基于 UDP 的 QUIC。
参考上面的问题『QUIC 是一个精巧的协议,所以它肯定不止今天我提到的四种机制,你知道还有哪些吗?』
你觉得基于 RTMP 的视频流传输的机制存在什么问题?如何进行优化?
RTMP 是基于 TCP 的,并不适合做实时流传输,可以换用基于 UDP 的方案
- 基于自研 UDP 的协议传输
- 基于 QUIC 的协议传输
99% 卡住的原因是什么?
99.99%的定义,是最后校验出了错误,漏失某个文件。
- 漏失的原因可能是 client 因为流量压力过大而下线了,其他人就无法找到这个文件了,顶多DHT网络告诉每个client,漏失的文件在某个下线的人手上。你们就乖乖等他上线,并且把手上的99.99%分享给其他新来的new node吧。
- 不论是依赖 tracker,还是分布式哈希算法,p2p 开宗明义就是要减轻 server 压力,把压力转嫁给 client。
解决方案
- 比如迅雷,提供了 p2sp,长效种子,让 server 也有义务承担一些压力。
至于迅雷为什么也会99.99%,应该是更进阶的技术问题了。比如下载网站专门防止迅雷盗链。
全局负载均衡使用过程中,常常遇到失灵的情况,你知道具体有哪些情况吗?对应应该怎么来解决呢?
- 全局负载均衡器因为流量过大,而导致的失灵,
- 此情况,是因为流量已经超过了当前机器的极限所导致的,针对此只能通过扩容来解决。
- 全局负载均衡器因为机器故障了,导致的失灵。
- 此情况的发生,说明机器存在负载均衡器有单点问题,须通过增加备机,或者更为可靠的集群来解决。
- 全局负载均衡器因为网络故障,导致的失灵。
- 此情况,案例莫过于支付宝的光纤被挖掘机挖断,此问题可通过接入更多的线路来解决,
如果权威 DNS 连不上,怎么办?
一般情况下,DNS 是基于 UDP 协议的。在应用层设置一个超时器,如果 UDP 发出没有回应,则会进行重试。
- DNS 服务器一般也是高可用的,很少情况下会挂。即便挂了,也会很快切换,重试一般就会成功。
- 对于客户端来讲,为了 DNS 解析能够成功,也会配置多个 DNS 服务器,当一个不成功的时候,可以选择另一个来尝试。
使用 HTTPDNS,需要向 HTTPDNS 服务器请求解析域名,可是客户端怎么知道 HTTPDNS 服务器的地址或者域名呢?
HTTPDNS 服务器的地址一般不变,可以使用 DNS 的方式获取 HTTPDNS 服务器 IP 地址,也可以直接把 HTTPDNS 服务器的 IP 地址写死在客户端中。
这一节讲了 CDN 使用 DNS 进行全局负载均衡的例子,CDN 如何使用 HTTPDNS 呢?
参照阿里云 CDN HTTPDNS 的方式
- 客户端请求服务端 umc.danuoyi.alicdn.com xxx,参数是客户端 IP 地址和待解析的域名
- 服务端返回多个 IP 地址,也就是一组 CDN 服务器地址
- 客户端轮训这些 IP 地址,以实现负载均衡
对于数据中心来讲,高可用是非常重要的,每个设备都要考虑高可用,那跨机房的高可用,你知道应该怎么做吗?
跨机房的高可用分两个级别
- 同城双活,就是在同一个城市,距离大概 30km 到 100km 的两个数据中心之间,通过高速专线互联的方式,让两个数据中心形成一个大二层网络。
- 同城双活最重要的是
- 数据如何从一个数据中心同步到另一个数据中心
- 在一个数据中心故障的时候,实现存储设备的切换,保证状态能够快速切换到另一个数据中心。
- 在高速光纤互联情况下,主流的存储厂商都可以做到在一定距离之内的两台存储设备的近实时同步。数据双活是一切双活的基础。基于双数据中心的数据同步,可以形成一个统一的存储池,从而数据库层在共享存储池的情况下可以近实时的切换,例如 Oracle RAC。
- 虚拟机在统一的存储池的情况下,也可以实现跨机房的 HA,在一个机房切换到另一个机房。
- SLB 负载均衡实现同一机房的各个虚拟机之间的负载均衡。GSLB 可以实现跨机房的负载均衡,实现外部访问的切换。
- 如果在两个数据中心距离很近,并且大二层可通的情况下,也可以使用 VRRP 协议,通过 VIP 方式进行外部访问的切换。
- 同城双活最重要的是
- 异地灾备
- 异地灾备的第一大问题还是数据的问题,也即生产数据中心的数据如何备份到容灾数据中心。
- 由于异地距离比较远,不可能像双活一样采取近同步的方式,只能通过异步的方式进行同步。
- 可以预见的问题是,容灾切换的时候,数据会丢失一部分。
- 由于容灾数据中心平时是不用的,不是所有的数据都会进行容灾,否则成本太高。
- 建议从业务层面进行容灾。由于数据同步会比较慢,可以根据业务需求高优先级同步重要的数据,因而容灾的层次越高越好。
- 对业务来讲,如果用户可以根据业务层情况,在更细的粒度上区分数据是否重要。重要的数据,例如交易数据,需要优先同步;不重要的数据,例如日志数据,就不需要优先同步。
- 有的用户完全不想操心,直接使用存储层面的异步复制。
- 对于存储设备来讲,它是无法区分放在存储上的虚拟机,哪台是重要的,哪台是不重要的,只会完全根据块进行复制,很可能就会先复制了不重要的虚拟机。
- 如果用户想对虚拟机做区分,则可以使用虚拟机层面的异步复制。用户知道哪些虚拟机更重要一些,哪些虚拟机不重要,则可以先同步重要的虚拟机。
- 建议从业务层面进行容灾。由于数据同步会比较慢,可以根据业务需求高优先级同步重要的数据,因而容灾的层次越高越好。
- 在有异地容灾的情况下,可以平时进行容灾演练,看容灾数据中心是否能够真正起作用,别容灾了半天,最后用的时候掉链子。
- 异地灾备的第一大问题还是数据的问题,也即生产数据中心的数据如何备份到容灾数据中心。
协议专栏特别福利 | 答疑解惑第五期
当前业务的高可用性和弹性伸缩很重要,所以很多机构都会在自建私有云之外,采购公有云,你知道私有云和公有云应该如何打通吗?
公有云和私有云之间打通主要通过两种方式
- 专线,这个需要跟运营商购买,而且需要花时间搭建。
- VPN,包括 IPSec VPN 和 MPLS VPN。这个还需要在公有云厂商那边购买VPN 网关,将其和私有云的网关联通。
咱们上网都有套餐,有交钱多的,有交钱少的,你知道移动网络是如何控制不同优先级的用户的上网流量的吗?
这个其实是 PCRF 协议进行控制的,它可以下发命令给 PGW 来控制上网的行为和特性。
为了直观,这一节的内容我们以桌面虚拟化系统举例。在数据中心里面,有一款著名的开源软件 OpenStack,这一节讲的网络连通方式对应 OpenStack 中的哪些模型呢?
openstack网络模式有三种
- flat
- flat dhcp
- vlan
实际上对应到kvm的两种模式
- nat
- 桥接
openstack 的 vlan 模式等 = kvm 的桥接模式 + vlan。
在这一节中,提到了通过 VIP 可以通过流表在不同的机器之间实现负载均衡,你知道怎样才能做到吗?
可以通过 ovs-ofctl 下发流表规则,创建 group,并把端口加入 group 中,所有发现某个地址的包在两个端口之间进行负载均衡。
SDN 控制器是什么东西?
SDN 控制器是一个独立的集群,主要是在管控面,因为要实现一定的高可用性。
- 主流的开源控制器有 OpenContrail、OpenDaylight 等
- 每个网络硬件厂商都有自己的控制器,而且可以实现自己的私有协议,进行更加细粒度的控制
所以江湖一直没有办法统一
这一节中提到,入口流量其实没有办法控制,出口流量是可以很好控制的,你能想出一个控制云中的虚拟机的入口流量的方式吗?
在云平台中,我们可以限制一个租户的默认带宽
- 我们仍然可以配置点对点的流量控制
- 在发送方的 OVS 上,我们可以统计发送方虚拟机的网络统计数据,上报给管理面。
- 在接收方的 OVS 上,我们同样可以收集接收方虚拟机的网络统计数据,上报给管理面。
- 当流量过大的时候,我们虽然不能控制接收方的入口流量,但是我们可以在管理面下发一个策略,控制发送方的出口流量。
对于 HTB 借流量的情况,借出去的流量能够抢回来吗?
借出去的流量,当自己使用的时候,是能够抢回来的。
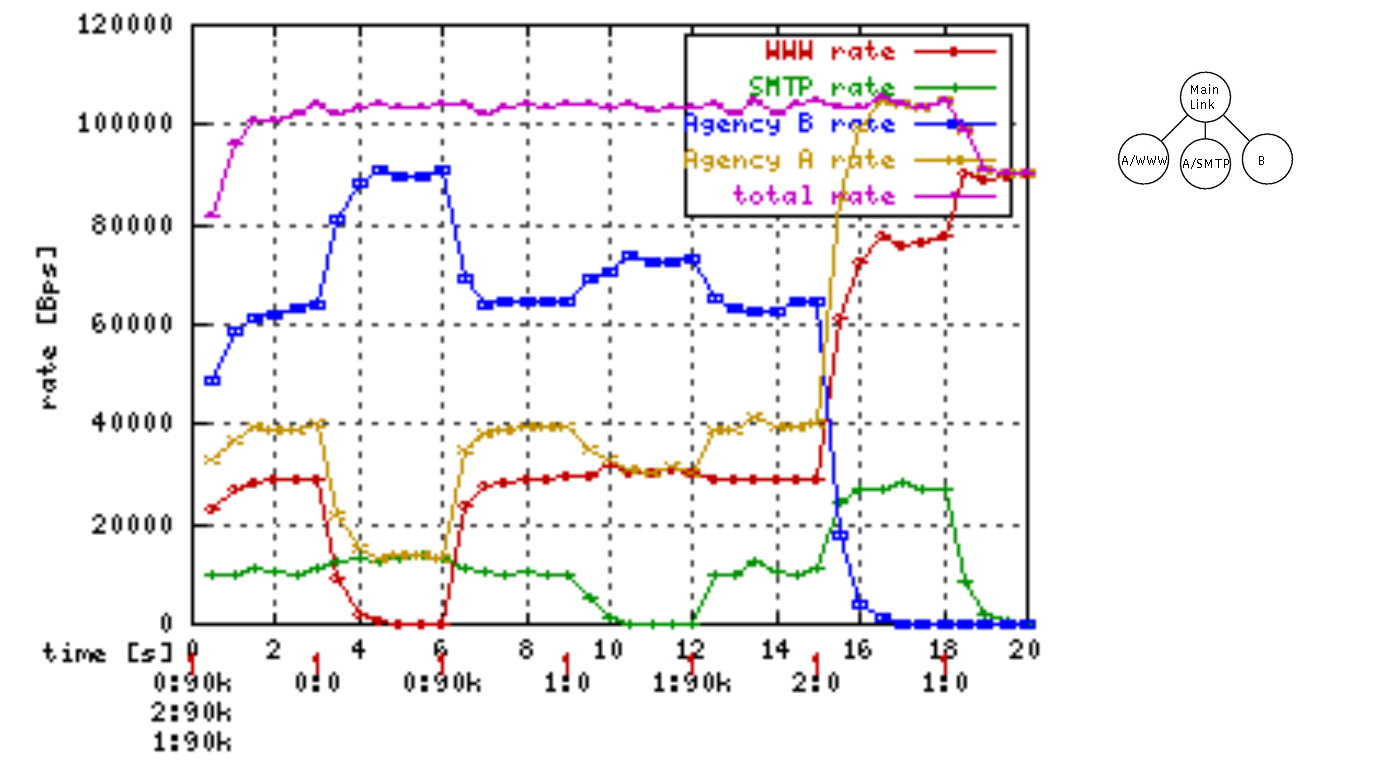
这是一棵 HTB 树
- 有三个分支
- A 用户使用 www 访问网页
- A 用户使用 SMTP 协议发送邮件
- B 用户不限协议。
- 图示分析
- 在时间 0 的时候,0、1、2 都以 90k 的速度发送数据,也即 A 用户在访问网页,同时发送邮件;B 也在上网,干啥都行。
- 在时间 3 的时候,将 0 的发送停止,A 不再访问网页了,红色的线归零,A 的总速率下来了,剩余的流量按照比例分给了蓝色的和绿色的线,也即分给了 A 发邮件和 B 上网。
- 在时间 6 的时候,将 0 的发送重启为 90k,也即 A 重新开始访问网页,则蓝色和绿色的流量返还给红色的流量。
- 在时间 9 的时候,将 1 的发送停止,A 不再发送邮件了,绿色的流量为零,A 的总速率也下来了,剩余的流量按照比例分给了蓝色和红色。
- 在时间 12,将 1 的发送恢复,A 又开始发送邮件了,红色和蓝色返还流量。
- 在时间 15,将 2 的发送停止,B 不再上网了,啥也不干了,蓝色流量为零,剩余的流量按照比例分给红色和绿色。
- 在时间 19,将 1 的发送停止,A 不再发送邮件了,绿色的流量为零,所有的流量都归了红色,所有的带宽都用于 A 来访问网页。
虽然 VXLAN 可以支持组播,但是如果虚拟机数目比较多,在 Overlay 网络里面,广播风暴问题依然会很严重,你能想到什么办法解决这个问题吗?
很多情况下,物理机可以提前知道对端虚拟机的 MAC 地址,因而当发起 ARP 请求的时候,不用广播全网,只要本地返回就可以了,在 Openstack 里面称为 L2Population。
容器内的网络和物理机网络可以使用 NAT 的方式相互访问,如果这种方式用于部署应用,有什么问题呢?
- NAT 导致网络性能有损耗
- NAT 导致看不到真实 IP
- 物理机端口被占用,当容器多的时候对于物理机端口的占用更加明显
通过 Flannel 的网络模型可以实现容器与容器直接跨主机的互相访问,那你知道如果容器内部访问外部的服务应该怎么融合到这个网络模型中吗?
Pod 内到外部网络是通过 docker 引擎在 iptables 的 POSTROUTING 中的 MASQUERADE 规则实现的
- 将容器的地址伪装为 node IP 出去
- 回来时再把包 nat 回容器的地址
有的时候,我们想给外部的一个服务使用一个固定的域名,这就需要用到 Kubernetes 里 headless service 的 ExternalName。
- 我们可以将某个外部的地址赋给一个 Service 的名称,当容器内访问这个名字的时候,就会访问一个虚拟的 IP。
- 在容器所在的节点上,由 iptables 规则映射到外部的 IP 地址。
将 Calico 部署在公有云上的时候,经常会选择使用 IPIP 模式,你知道这是为什么吗?
如果 VPC 网络是平的,中间有路由,但是公有云经常会有一个限制,那就是容器的 IP 段是用户自己定义的,一旦出虚拟机的时候,云平台发现不是它分配的 IP,很多情况下直接就丢弃了。如果是 IPIP,出虚拟机之后,IP 还是虚拟机的 IP,就没有问题。
在这篇文章中,mount 的过程是通过系统调用,最终调用到 RPC 层。一旦 mount 完毕之后,客户端就像写入本地文件一样写入 NFS 了,这个过程是如何触发 RPC 层的呢?
是通过 VFS 实现的。在 Linux 里面,很多东西都是文件,因而内核中有一个打开的文件列表 File list,每个打开的文件都有一项。
- 对于 Socket 来讲,in-core inode 就是内存中的 inode。
- 对于 nfs 来讲,也有一个 inode,这个 inode 里面有一个成员变量 file_operations,这里面是这个文件系统的操作函数,有 nfs_file_read、nfs_file_write,所以在一个 mount 的路径中读取某个文件的时候,就会调用这两个函数,触发 RPC,远程调用服务端。
对于 HTTP 协议来讲,有多种方法,但是 SOAP 只用了 POST,这样会有什么问题吗?
虽然 HTTP 协议有多种方法,但是平常来说 POST,GET 基本足够用。
- SOAP 协议规范上是支持 GET 的,但是由于一般 XML 比较复杂,不适合放在 GET 请求的查询参数里,所以 SOAP 协议的服务多采用 POST 请求方法。
- SOAP 只支持 POST 方法,缺少 GET 方法,GET 方法可以浏览器直接跳转,POST 必须借助表单或者 ajax 等提交,也就限制了 SOAP 请求只能在页面内获取或者提交数据。
对于微服务模式下的 RPC 框架的选择,Dubbo 和 SpringCloud 各有优缺点,你能做个详细的对比吗?
- 实现方案
- Dubbo 只实现了服务治理
- Spring Cloud 子项目分别覆盖了微服务架构下的众多部件
- 协议
- Dubbo 使用 RPC 通讯协议
- Spring Cloud使用 HTTP 协议 REST API
- 性能:Dubbo 通信性能略胜于 Spring Cloud
- 组件依赖关系
- Dubbo通过接口的方式相互依赖,强依赖关系,需要严格的版本控制,对程序无入侵
- Spring Cloud 无接口依赖,定义好相关的json字段即可,对程序有一定入侵性
在讲述 Service Mesh 的时候,我们说了,希望 Envoy 能够在服务不感知的情况下,将服务之间的调用全部代理了,你知道怎么做到这一点吗?
iptables 规则可以这样来设置:
- 定义的一条规则是 ISTIO_REDIRECT 转发链。这条链不管三七二十一,都将网络包转发给 envoy 的 15000 端口。但是一开始这条链没有被挂到 iptables 默认的几条链中,所以不起作用。
- 在 PREROUTING 规则中使用这个转发链。从而,进入容器的所有流量都被先转发到 envoy 的 15000 端口。而 envoy 作为一个代理,已经被配置好了,将请求转发给 productpage 程序。
- 当 productpage 往后端进行调用的时候,就碰到了 output 链。这个链会使用转发链,将所有出容器的请求都转发到 envoy 的 15000 端口。
- 这样,无论是入口的流量,还是出口的流量,全部用 envoy 做成了“汉堡包”。envoy 根据服务发现的配置,做最终的对外调用。
- 这个时候,iptables 规则会对从 envoy 出去的流量做一个特殊处理,允许它发出去,不再使用上面的 output 规则。